這篇算是念書的重點筆記
主要是基礎語法
書目是林信良撰寫的python 3.5技術手冊
條例出來內容有點多
建議可以用關鍵字找
1.cmd或powershell 輸入python可以進入REPL模式
可以直接打指令
Ex print('hello world')
2.help() 可以進去說明頁面
前面會變成help>
想知道有那些模組或關鍵字可以輸入modules.keywords
要結束可以輸入quit
3.REPL也可以使用help()查詢
Ex: help(print)
要離開REPL環境可以使用quit()
4.只是要執行小程式片段可以在命令提示字元輸入
Python –c “print(‘hello world’)”
5.
程式最上面編碼設定
# coding=<encoding name>
# coding:<encoding name>
可以指定要用的編碼,避免錯誤
Python 3之後的直譯器預設編碼是UTF-8
原始是ASCII
6.匯入模組可以用,區隔
Import sys,email
常用模組都存在__builtins__
可以在REPL模式使用dir(__builtins__)查看
7.如果要匯入別人的模組或不同資料夾的檔案
可以SET PYTHONPATH=路徑1;路徑2
可以檢查
>>Import sys
>>sys.path
或是直接用append也可以
>>sys.path.append(‘路徑’)
8.重新命名模組
Import 模組名稱as 自訂名稱
但是還要加上前置詞
也可以直接指定模組中的名稱
Ex:
From sys import argv
From sys import argv,path (多個)
From sys import * (全部 不建議用 會覆蓋前面名稱)
也可以從套件匯入模組
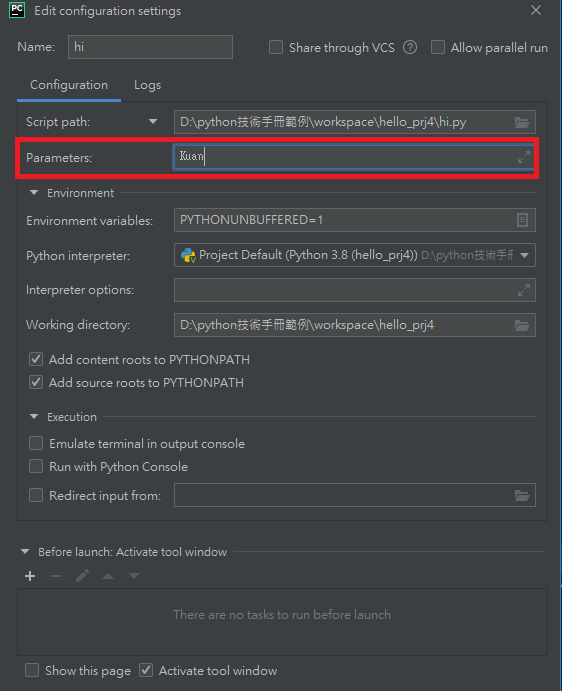
9.pycharm的Run點開可以用Edit設定命令列引數
不用自己打指令
10.整數型態為int,不區分整數與長整數
可以用Int()轉換
浮點數float()
Ex取得字串3.14的整數部位要 int(float(‘3.14’))
布林bool()
0,None,False,0.0,0j(複數),’’,()(空Tuple),[](空清單),{}(空字典)傳給bool()都回傳False
其他傳進去都會是True
複數 :Complex類別的實例
可以直接運算
>>a = 3+2j
>>b=5+3j
>>a+b
>>8+5j
11.溢出字元 跟C#差不多
Print(‘\\t’)
==print(r‘\t’) >>r表示raw string
12.如果字串需要換行 要用’’’表示
Print(‘’’ aaa
Bbb‘’’)
12.print()預設會換行
Print(‘hello’,end=’’) 在指定的字串之後,end參數指定的字串就會輸出
不想換行就把end指定空字串
Print('hello','kuan')預設會用空白分隔字串
Print('hello','kuan',sep='')設定sep可以用指定的來分隔
13.字串格式化符號
String % data
String % (data1,data2,…)
%5d 保留5個欄位 不足用空白表示
%-5d表示向左對齊
%.2f表示小數後保留2位數
Python 3之後版本
‘{ }’.format()的格式
{0:d}
{0:.2f}
Format()也可以進行簡單運算
EX
Names = ['Kuan','Lin','Fu']
'All names :{n[0]},{n[1]},{n[2]}'.format(n = names)
或是格式化單一數值
Format(3.14159,'.2f')
14.List
用[ ]建立
有以下方法append(),
Pop(),取出元素
Remove(), 移除指定元素值
Reverse(),
Sort()
Del listname[index] 刪除指定位置元素
附加多個元素 extend() ex.numbers.extend([10,20,30])
可以存任何型態的物件
List()可以把iterable的物件轉成list
15.Set 是無序不重複的集合
可以使用{}包括元素,元素用,區隔
如果要建立空集合 必須要用set()
List跟set不能放到集合中 因為要保證元素不重複(unhashable物件)
Set()可以把iterable的物件轉成Set (字串,list,Tuple)
16.Dictionary
每個key不能重複
可以用in檢查是否存在字典裡
可以用Get(‘key name’)取得值
預設傳回None
也可以指定預設值
Dict.get(‘key’,9999)
Items():可取得鍵值 回傳dict_items物件
Keys():取得鍵 回傳dict_keys物件
Values():取得值 回傳dict_values物件
以上三個是惰性求值,需要的時候才進行運算轉成list使用
也可以使用dict()建立字典
Ex.
Accounts = dict(kuan=123456,momor=642132,hamimi=970221)
Accounts2 = dict([('kuan',123465),('momor',642132),('hamimi',970221)])
17.Tuple
有序結構,且建立後就不能改變
用,就可以建立
最後一個,可以省略
() 沒任何元素的Tuple
建立單一個元素要寫成(elem,) 或elem, 不可以寫成(elem)
如果不想定義一個型態,只是想傳回相關的值就可以用
Tuple的元素可以Unpack,逐一分配給每個變數
Data = (1, 'kuan', True)
Id, name, verified = data
更方便的用法是置換變數
X = 10
Y = 20
X, y = y, x
Extended lterable unpacking
A, * b = (1, 2, 3, 4, 5)
>>>a =1
>>>b =[2,3,4,5]
18.變數都是存參考
而且變數本身沒有型態
可以前後指定不同的型別
可以看變數有幾個參考
Import sys
Sys.getrefcount(x)
不使用變數的話可以用del 刪除
19.運算
1.0 - 0.8 = 0.19999999999999996
算錢用浮點 遲早被人扁XD
要用decimal型別
Ex.
Import decimal
D1 = decimal.Decimal(sys.argv[1])
D2 = decimal.Decimal(sys.argv[2])
指數運算 **
2**3 =8
9**0.5=3
除法
/ :一定會產生浮點數
// : 整數跟整數除會產生整數,整數跟浮點數除會產生浮點數
print(10 / 3) #3.3333333333333335
print(10 // 3) #3
print(10 / 3.0) #3.3333333333333335
print(10 // 3.0) #3.0
20.字串運算
+可以串聯字串
*可以讓字串重複出現
但是python是強型別
字串跟數字不能串接,需要透過轉型str()
21.比較運算子
>, >=, <, <=, ==, !=(<>沒在用)
他們可以串接在一起
Ex. X <y <= z
W == x == y ==z
- == , !=是用來比較物件實際的值
Is ,is not 是用來比較物件參考
22.邏輯運算
And or not
0,None,False,0.0,0j(複數),’’,()(空Tuple),[](空清單),{}(空字典)
以上這些都是false的結果
其他都會是True
23.位元運算
And or not xor
二進位逐位元運算
10010001 and
01000001
=
00000001
補數運算是所有位元0變1,1變0
也可以用在set型態上
&交集,|聯集,^互斥 –差集
24.切片運算slice
[start:end:step]
Ex name = ‘Justin’
Name[0:4:2]=’Js’
Name[2::2]=’si’
Name[:5:2]=’Jsi’
Name[::-1]=’nitsuj’ 負偏移 等於反轉了
[:]只是做淺層複製,只複製參考
也可以用來做元素取代
Lt = ['one','two','three','four']
Lt[1:3] = [2, 3]
Print(lt)
Lt[1:3] = ['ohoh']
25.while迴圈
有else的用法,但不管true或false都會執行,除非用break中斷
26.range函數
Range(start,stop[,step])
Step是遞增值 預設1
27. Enumerate()可以用來做迭代
Name = 'Justin'
List(enumerate(name))
>>>
[(0, 'J'), (1, 'u'), (2, 's'), (3, 't'), (4, 'i'), (5, 'n')]
預設會從0開始記數
如果要從其他開始可以指定2個參數enumerate(arrayname,index)
28.
Pass:不做任何動作 只是用來維持程式完整性
Continue:執行下一次迴圈
Break:中斷執行 跳出迴圈
29.for Comprehension
把迴圈語法壓縮,但是可讀性會下降
Ex.
Squares = []
For arg in sys.argv[1:]:
Squares.append(int(arg) ** 2)
Print(squares)
可以簡化為
Squares = [int(arg) ** 2 for arg in sys.argv[1:]]
Print(squares)
另一個例子
For arg in sys.argv[1:]:
If int(arg) % 2:
Odds.append(arg)
改成
Odds = [arg for arg in sys.argv[1:] if int(arg) % 2]
兩邊放上[]表示會幫忙轉成list,如果資料來源很多或是有惰性求值特性的產生器時候,可以放上() 效能比較好
30.函式裡面可以再寫一個函式
Local function
不支援overload 因為後面的函式會蓋掉前面的(同樣名稱的)
參數預設
def prepend(elem,lt=[])
這樣寫法不好 因為沒指定的話lt會一直用同一個(參考)
要改成def prepend(elem,lt=None)然後在程式裡判斷
lt = lt if lt else []
31.unpack的應用
第一種用法:
函式定義
def account(name, number, balance)
可以用這樣給(轉成tuple分配)
account(*('Kuan', '123-4567', 1000))
或是(字典自動對應)
Params = {'name': 'Jenny', 'number': '123-987654', 'balance': 1000}
Account(**params)
第二種用法:
反過來也可以
def sum(*numbers)
用這樣給
Sum(1, 2, 3)
第三種用法:
Def ajax(url, **user_settings):
Settings = {
'Method': user_settings.get('method', 'GET'),
'Contents': user_settings.get('contents', ''),
'Datatype': user_settings.get('datatype', 'text/plain')
}
Print(f'請求:{url}')
Print(f'設定:{settings}')
Ajax('http://www.com.tw', method='POST', contents='book=python')
My_settings = {'method': 'POST', 'contents': 'book=python'}
Ajax('http://www.com.tw', **my_settings)
*是轉成tuple分配給值
**是轉成dictionary對應
32.一級函式
函式可以當作物件傳遞,指定給其他變數
可以傳入list跟一個function 有點類似C#的delegate
具有惰性求值的特性
Filter()
Map()
Sorted():可以傳入list或tuple 有key 跟 reverse參數
Ex: sorted(('Justin', 'openhome', 'momor'), key=len, reverse=True)
List本身有sort()方法,會直接本身排序不像sorted()回傳一個新的list
也可以使用lambda建立簡單函式
語法:lambda 參數:函式本體
運算結果會作為回傳值,不用寫return
Ex:
def filter_lt(predicate, lt):
result = []
for elem in lt:
if predicate(elem):
result.append(elem)
return result
lt = ['justin', 'caterpillar', 'openhome']
寫法一
filter_lt(lambda elem: len(elem) > 6, lt)
寫法二
list(filter(lambda elem:len(elem) > 6,lt))
如果不用參數,直接在lambda後面加上冒號
要兩個以上參數中間要用,區隔
33.lambda也可以模擬switch,因為python本身沒有
score = int(input('請輸入分數:'))
level = score // 10
#dictionary
{
10 : lambda: print('Perfect'),
9 : lambda: print('A'),
8 : lambda: print('B'),
7 : lambda: print('C'),
6 : lambda: print('D')
}.get(level, lambda: print('E'))()
如果get取不到key值,就傳回預設,跟default一樣
Lambda沒辦法寫太複雜的邏輯,要就還是用def
34.python的變數可以在區域函式、外包函式、全域、內建的順序尋找或建立
取變數的時候會從最內層往外尋找
全域是以模組檔案為界
可以用locals()取得所有區域變數
globals() 可以取得全域變數
在函式內定義跟全域變數一樣名稱的變數不會改變全域變數的值
但是如果在變數前宣告global就是取用全域變數
或是宣告成nonlocal 他就會依照順序往外找這個變數
35.yield會把流程控制權讓給函式呼叫者
會傳回一個產生器有__next__()方法,可以用next()函式呼叫取出下個產生值
yield也可以透過send()給值
Asyncio模組可以去搜尋
36.from import 會將被匯入模組中之名稱參考的值,指定給目前模組中建立的新名稱
簡單說就是在現在模組中建立新變數,只是一開始參考同一個值
如果變數不想被from import *建立同名變數,可以用底線開頭命名
Ex._y = 20
或是定義一個__all__清單,限定可以被import的變數
但是用 import modulename 這種形式的不限
還是可以用[modulename.變數]存取
37.可以用del刪除模組名稱
>>>import foo
>>>qoo = foo
>>> del foo
>>>foo.x會出錯
是刪除指定的名稱,而不是刪除名稱參考的物件本身
所以參考那個物件的變數還會有資料
如果想知道目前已載入的module名稱與實例有哪些,可以透過sys.modules
38.import也可以出現在函式裡面,作用範圍就只會在函式中
39.尋找模組時的路徑
執行python直譯器時的資料夾
PYTHONPATH環境變數
PYTHON安裝中標準程式庫等資料夾
PTH檔案列出的資料夾(可以在.pth檔案中列出模組搜尋路徑,一行一個)
例如:建一個.pth檔案
列出模組搜尋路徑
C:\workspace\libs
C:\workspace\third-party
C:\workspace\devs
PTH檔案的存放位置不同作業系統不相同,可以如下取得位置
>>>import site
>>>site.getsitepackages()
如果確實建立.pth中列出的資料夾,而且將檔案放在上面列出的位置
Sys.path就會加入那些路徑
或是想要把PTH檔案放在其他資料夾
可以使用site.addsitedir(‘路徑’)
40.python的類別也是宣告class
初始化寫法是 __init__(self)方法
要設置屬性可以在後面直接加參數
這個方法是實例建構後初始化,不是建構類別實例
Ex
Class Account:
Def __init__(self,name, number, balance):
Self.name = name
Self.number = number
Self.balance = balance
建立實體
Act =Account(‘Justin’,’123456’,1000)
建立方法的第一個參數也都是放self(物件本身)
41.__str__()方法
可以傳回物件描述字串的方法,第一個參數是self
不要直接呼叫
可以用print()或str(物件)
42.如果要避免使用者直接誤用屬性
可以使用self.__XXX定義內部值
Ex.
Class Account:
Def __init__(self, name, number, balance):
Self.__name = name
Self.__number = number
Self.__balance = balance
但有一招可以破解就是用 ’_類別名稱__屬性名稱’
Ex._Account__balance
但不建議使用
因為__XXX是定義內部流程使用的
.43.外部屬性
如果是想可以讓外部取得的屬性
可以用@property宣告 方法
但是只允許取值,不能給值
Ex.
@property
Def name(self):
Return self.__name
44.外部屬性設定值
@property的用法只能給值
@屬性名稱.setter 加在方法上可以用來設定值(對應@property的方法名稱做前綴)
Ex.
@name.setter
Def name(self,name):
Self.__name = name
45.可以取得方法綁定的物件
class some:
def me(self):
return self
s = some()
print(s.me() is s.me.__self__)
s.me()叫做bound method
45.如果定義類別的時候,希望某個方法不被拿來作為綁定方法,可以使用 @staticmethod 標註
Ex.
@staticmethod
def default(name, number):
return account(name, number, 100)
可以直接用類別名稱呼叫方法
bank.account.default('kuan','123456')
也可以用類別實例呼叫 但不建議
acct.default('kuan','123456')
這樣acct也不會被傳入當default的第一個參數
46.上面的方法不好,因為寫死類別名稱
萬一要改名稱的話要改很多地方
對於這個狀況 可以在方法上標註 @classmethod
第一個參數一定是接受所在類別的type實例
@classmethod
def default2(cls,name, number):
return cls(name, number, 100)
47.可以用__dict取得類別或實例的特性
但是不建議直接呼叫__的方法
可以改用vars(物件)
48.可以在類別實例建構後,直接再建立新方法
也可以直接建一個變數在實例上
49.類別實例的建構是__new()__方法定義
第一個參數是類別本身
之後可定義任意參數建構物件
如果傳回的物件是第一個參數的類別實例,才會接著執行__init()__方法
後面的參數會繼續使用
50.如果想再物件被刪除的時候,自行定義清除相關資源的行為,可以實作__del__()方法
不被任何名稱參考就會被回收,等於刪除
51.類別的繼承寫法
class 子類別(父類別)
52.鴨子定型
如果他走路像個鴨子,游泳像個鴨子,叫聲像個鴨子,那他就是鴨子
要思考物件的行為,而不是物件的種類
53.繼承類別後打算基於父類的方法來重新定義某個方法,可以使用super()來呼叫父類別方法
54.如果希望子類別在繼承後一定要實作的方法,可以在父類別中指定metaclass為abc模組的abcmeta類別,並在指定的方法上標註abc模組的@abstractmethod
Ex
from abc import abcmeta, abstractmethod
class role(metaclass=abcmeta):
方法
@abstractmethod
def fight(self):
pass
這時候就不能用父類來建構物件了
如果類別繼承但沒實作方法會發生TYPEERROR
55.python中若沒有定義的方法,某些狀況下必須呼叫時,就會看父類別中是否有定義,如果定義了自己的方法,就會以你定義的為主
56.繼承的時候需要父類別的初始化方法
那可以在子類的初始化方法用super().__init__()叫用父類的初始化流程
Super()相當於super(__class__,<first argument>)
__class__代表所在類別
<first argument>代表目前所在方法第一個引數
呼叫init當法就等同於super(__class__,self)
57.rich comparison方法
自定義比較運算子
__lt__():<
__le__():<=
__gt__():>
__ge__():>=
__eq__():==
通常是用is比較,但只有比較物件參考,沒有比較物件的值
可以用hasattr(object,’屬性名稱’)來比較屬性值是否相等
或是可以檢查型態isinstance(other,__class__)
__ne__():!=
如果需要定義完整的比較方法
可以用functools. Total_ordering
然後在class上掛@total_ordering
當被標註後必須實作__eq__()方法
__lt__(),__le__(),__gt__(),__ge__()選一個方法實作
Ex.
From functools import total_ordering
@total_ordering
class some:
def __init__(self,value):
self.value = value
def __eq__(self, other):
return self.value == other.value
def __gt__(self, other):
return self.value > other.value
58.列舉模組
from enum import intenum,Enum,unique
繼承Enum的話列舉值可以是各型態
Intenum值只能是int
Ex.
@unique
class Action(intenum):
Stop = 1
Right = 2
Left = 3
Up = 4
Down = 5
Action()是用來指定列舉值然後傳回列舉物件
Ex Action(3)
>> Action.left
列舉物件有name跟value可以取得名稱跟值
Ex.
Temp = Action(3)
Print(temp.name)
Print(temp.value)
或是用[]指定列舉名稱舉得列舉物件
Ex.
>>> Action['right']
>>>Action.right
也可以用for in來迭代
列舉名稱不能重複,但值可以重複(但是後者會是前者的別名)
如果不想要值重複可以在class上加標註 @unique(要import)
59.繼承多個父類時,如果父類有相同方法名稱
搜尋順序是 子類>父類由左至右 > ….
事實上是依據類別的__mro__屬性的tuple元素順序來找
(method resolution order)
如果要直接知道父類別可以用__bases__來得知
也可以直接 Class. __bases__ = (Class1, Class2)來更改繼承順序
60.如果繼承的父類定義抽象方法,另一個繼承的也定義了同名的
會依照繼承順序決定抽象方法是否得到實作
61. Help(super)看super的用法
Super() -> same as super(__class__, <first argument>)
Super(type) -> unbound super object
Super(type, obj) -> bound super object; requires isinstance(obj, type)
會從obj的__mro__清單裡面type的下個元素開始尋找相同的方法
Super(type, type2) -> bound super object; requires issubclass(type2, type)
會使用type2的__mro__清單,從指定的type之下各類別開始尋找指定的方法,有的話把type2當作是呼叫方法的第一個引數
62.help()函式會取出__doc__字串
稱作docstrings,可以自己在函式內定義 用’’’把字串包起來
63.python文件查詢
Indices and tables裡面
或是用cmd 輸入
>python -m pydoc -p 8080
>b
開啟一個瀏覽器(http://localhost:8080/)
第三方函式庫
https://pypi.org/
找到後可以用pip install ‘套件名稱’ 安裝
也可以把要的套件放在requirements.txt
然後pip –r install requirements.txt
64.錯誤捕捉語法
try
except typeerror as err:
else (try沒出錯才執行)
finally (不管怎樣都會執行)
for in語法遇到stopiteration的時候會直接pass
不會引發例外錯誤
Except之後可以使用tuple指定多個物件,也可以有多個except
如果沒有指定except後的物件型態,表示捕捉所有引發的物件
如果一個例外在except的過程中就符合某個例外的父型態,後續即使有定義也不會執行到
Ex arithmeticerror > zerodivisionerror
所有例外都是baseexception的子類別
例外的繼承架構可以搜尋build-in Exceptions
Https://docs.python.org/3/library/exceptions.html
65.想要自訂例外,要繼承Exception或是相關子類別
如果自定義__init__() ,建議把傳入的參數透過super().__init__(arg1,arg2…)
來呼叫Exception的__init__(),因為這些參數可透過args屬性已tuple取得
66.要丟出一個例外錯誤要使用raise
如果在except已經記錄錯誤訊息但要重新引發例外錯誤時
可以用
try
except exception as err:
raise 自訂例外 from err
67.如果進一步使用except處理重新引發的例外,可以透過例外實例的__cause__
來取得raise from時的來源例外
就算沒有使用到raise from,原本的例外也會自動被設定給被引發例外的__context__屬性
Ex.
try:
try:
raise eoferror('xd')
except eoferror:
raise indexerror('orz')
except indexerror as e:
print(e.__cause__)
print(e.__context__)
68.在python中,就算例外是個錯誤,只要程式碼能明確表達出意圖的情況下,也常會當程式流程的一部分
69.堆疊追蹤
可以用traceback module得知發生例外的根源跟執行過程
Ex.
import traceback
traceback.print_exc()
print_exc()可以指定開啟的檔案
file=open(‘xxx.txt’)
limit參數 預設none 不限制堆疊追蹤個數 指定正數就是顯示最近幾次
負數就是顯示最初幾次
70.sys.exe_info()
可以取得一個tuple物件 包括例外類型、實例、traceback物件
Ex
(<class 'Exception'>, Exception('shit happens!'), <traceback object at 0x00000252ff980380>)
Traceback物件代表每一層次的追蹤,可以用tb_next取得更深層的呼叫堆疊
Ex.
try:
test()
except:
type, value, traceback = sys.exc_info()
print('例外型態:', type)
print('例外物件:', value)
while traceback:
print('..........')
code = traceback.tb_frame.f_code
print('檔案名稱:', code.co_filename)
print('函式或模組名稱:', code.co_name)
traceback = traceback.tb_next
71.未被比對到的例外,直譯器最後會呼叫sys.excepthook()並傳入三個引數
也就是sys.exc_info()傳回的三個物件
72.提出警告訊息
通常是一種提示,用來告知程式有潛在問題
比方使用被棄用的功能,以不適當的方式存取資源
透過warnings模組的warn()函式提出警告
Ex.
Import warnings
warnings.warn('orz方法已棄用', deprecationwarning)
warnings.warn('xd使用者權限不足', userwarning)
預設是不會有任何結果
要起作用要在直譯器下指令
>>>Python –W always
-W接受的格式是action:message:category:module:leneno
Always是action指定
|
Error |
將警告訊息轉為例外(引發) |
|
Ignore |
不顯示警告訊息 |
|
Always |
總是顯示警告訊息 |
|
Default |
只顯示每個位置第一個符合的警告訊息 |
|
Module |
只顯示每個模組第一個符合的警告訊息 |
|
Once |
只顯示第一個符合的警告訊息(無論位置為何) |
Message是正規表達 用來比對想顯示的警告訊息
Category可以指定wrning的子類別 預設是userwarning
Module也是正規 比對模組名稱
Lineno是int 指定發出訊息的程式碼行號
73.try ,except ,else 是一組的,盡量讓可能引發錯誤的來源相關
Ex.
import sys
for arg in sys.argv[1:]:
try:
f = open(arg,'r')
except filenotfounderror:
print('file not found')
else:
try:
print(arg,'有', len(f.readline()), '行')
finally:
f.close()
如果檔案開啟失敗,就不會建立f變數
如果finally寫在外層反而會引發錯誤
74.with [資源] …as 變數 語法
With之後的資源實例可以透過as指定給一個變數,之後就可以在區塊中進行資源的處理,當離開with as 區塊之後,就會自動做清除資源的動作
但as 可以省略
等同於C#的using
Ex.
for arg in sys.argv[1:]:
try:
with open(arg, 'r') as f:
print(arg, ' 有 ', len(f.readlines()), ' 行 ')
except filenotfounderror:
print('找不到檔案', arg)
75.with as 不限使用於檔案,只要物件支援情境管理協定(Context Management Protocol)就可以用
支援情境管理協定的物件必須實作__enter__()、__exit__()兩個方法
With一開始執行就會跑__enter__()方法,回傳的物件可以使用as指定給變數
如果with區塊發生例外就會跑進__exit__()方法,並傳入三個引數
這三個就是sys.exe_info()回傳的物件
這邊回傳False 例外會重新被throw出去
但要是沒發生例外正常執行,也是會執行__exit__()方法,只是都傳入None
class resource:
def __init__(self, name):
self.name = name
def __enter__(self):
print(self.name, ' __enter__')
return self
def __exit__(self, type, value, traceback):
print(self.name, ' __exit__')
return false
with resource('res') as resource:
print(resource.name)
以上的方式如果不夠直覺,也可以使用模組
Contextlib模組的@contextmanager來實作,讓資源的設定跟清除更直覺
引用>>
From contextlib import contextmanager
Ex.
@contextmanager
def file_reader(filename):
try:
f = open(filename, 'r')
yield f
finally:
f.close()
yield的物件會做為as的值
with as語法是用來表示那個區塊是處於某個特殊情境中,自動關閉檔案的情境只是一種狀況
或是不回傳東西只是要處理error的部分
有更簡單的寫法 suppress()
ex.
from contextlib import suppress
with suppress(filenotfounderror):
for line in open(sys.argv[1]):
print(line, end='')
如果是有實作close但沒有情境管理的
可以使用closing()
76.補充supress()
實作情境管理器的,可以指定想抑制的例外類型
(1)
class suppress:
def __init__(self, ex_type):
self.ex_type = ex_type
def __enter__(self):
return none
def __exit__(self, ex_type, msg, traceback):
if ex_type == self.ex_type:
return true
return false
(2)
from contextlib import contextmanager
@contextmanager
def suppress(ex_type):
try:
yield
except ex_type:
pass
77.檔案讀寫可以使用open()函式
比較常用到前兩個參數
- File
檔案的路徑
可指定相對路徑或絕對路徑
- Mode
用字串來指定檔案開啟模式
|
R |
讀取模式(預設) |
|
W |
寫入模式,會先清空檔案內容 |
|
X |
只在檔案不存在的時候才建立新檔案並開啟為寫入模式,如果檔案已存在會引發fileexisterror |
|
A |
附加模式,若檔案已存在,寫入的內容會附加至檔案尾端 |
|
B |
二進位模式 |
|
T |
文字模式(預設) |
|
+ |
更新模式(讀取&寫入) |
Mode預設是’r’,只指定 ‘r’ ‘w’ ‘x’ ‘a’的情況相當於已文字模式開啟
如果要以二進位模式開啟 要指定 ‘rb’ ‘wb’ ‘xb’ ‘ab’
- Buffering:用來設置緩衝策略
預設是會自行決定
設成0的話,不用flush()就可以馬上看到檔案內容變化
Flush可以把緩衝內容出清
- Encoding跟errors
指定文字模式的檔案編碼
預設會用locale.getpreferredencoding()的傳回值
78.read()方法在未指定參數的情況下,會讀全部檔案的內容,文字模式會回傳Str()實例,二進位模式回傳byte實例
如果有指定整數參數,會讀取指定字元數或位元組數
79.readline(),readlines(),writelines()
文字模式預設是讀到 \n ,\r 或\r\n都可以被判定為一行
而readline(),readlines()讀到的每一行換行字元都一律為\n
二進位模式的行的判斷標準是b’\n’
文字模式在寫入的時候,任何’\n’都會被置換成os.linesep
80.
Tell()方法可以告知目前代檔案的位移值,單位是位元組值,檔案開頭的位移值是0
Seek()方法可以指定跳到哪個位移值
81.readinto()方法可以把二進位模式的檔案轉成bytearray
Ex.
Import os.path
B_arr = bytearray(os.path.getsize('test.txt'))
With open('test.txt','rb') as f:
F.readinto(b_arr)
81.
sys.stdin代表標準輸入
sys.stdout代表標準輸出
可以模擬print()跟input()
也可以類似open()函式
如果要以二進位讀取或寫入
可以用
sys,stdin.buffer或sts.stdout.buffer
ex.
def console_input(prompt):
sys.stdout.write(prompt)
sys.stdout.flush()
return sys.stdin.readline()
82.python的i/o分為三個主要類型
文字i/o
二進位i/o
原始i/o
iobase是所有i/o類別的基礎類別

83.set的內容無序且不重複,但只有hashable的物件可以放進去
list、dict、set本身都不行
hashable的物件:必須有hash值,這個值在執行期都不會變化,而且必須可以進行相等比較,較具體一點,物件必須實作__hash__()跟__eq_()方法
set在加入物件的時候,會呼叫__hash__()取得hash值,看看是否跟現有物件都不相同,然後再用__eq_()比較相等性才確定要不要加入
python的內建型態,只要是建立後狀態無法變動的(immutable)的,都是hashable,可變動的型態之實例都是unhashable
自定義類別的實例,__hash__()是根據id()計算的,__eq_()是用is比較,所以兩個分別建立的實例一定不同
84.具有__iter__()方法的就是iterable物件
可以用iter()方法從物件取得迭代器,不用直接呼叫__iter__()方法
傳回的迭代器具有__next__()方法,可以逐一迭代物件,如果無法進一步迭代會引發stopiteration,迭代器也會具有__iter__()方法,傳回本身(也是iterable物件)
產生器也是一種迭代器(yield語法)
85.itertools模組
import itertools
有cycle(),repeat()函式
count():可以指定起始值跟步進值
accumulate():累加運算
chain()或chain.from_iterable():可以將指定的序列攤平逐一迭代
dropwhile():會在指定函式傳回true的情況下,持續丟棄元素
takewhile():相反持續保留元素,值到有元素讓函式回傳false
groupby():分類 回傳值是itertools.groupby物件(iterable),迭代的時候會傳回一個tuple,第一個值是指定的分類值,第二個值是itertools._grouper,包含所有同個分類的物件
ex.
names = ['justin', 'monica', 'irene', 'pika', 'caterpillar']
group_by_name = itertools.groupby(names, lambda name: len(name))
for length, group in group_by_name:
print(length,list(group))
86.排序可以使用sort()排序
list才有sort()方法
可以放reverse設定 ex. list.sort(reverse = true)
或是針對key排序 ex.list.sort(key = lambda x : x[0])
其他iterable物件,可以使用sorted()
sorted(iterable,key,reverse)
如果是自訂類別要排序,必須實作__lt__()方法
ex.
def __lt__(self, other):
return self.name < other.name
87.使用operator模組幫助排序
itemgetter是針對索引結構
ex.
customers = [
('justin', 'a', 40),
('irene', 'c', 8),
('monica', 'b', 37)
]
from operator import itemgetter
sorted(customers, key = itemgetter(0))
attrgetter是針對物件屬性
ex.
customers = [
customer('justin', 'a', 40),
customer('irene', 'c', 8),
customer('monica', 'b', 37)
]
from operator import attrgetter
print(sorted(customers, key = attrgetter('name')))
88.python的群集架構有三個類型
循序類型sequences type
集合類型set type
映射類型mapping type
89.循序類型
有序、具備索引的資料結構,都是iterable物件
list, tuple,str,bytes,bytearray
tuple,str,bytes是不可變動的循序類型,有預設的hash()實作,可作為set的元素或dict的key
90.集合類型
無序而且元素必須都是hashable物件且不會重複,他們是iterable物件
可以用in ,not in,len(set) 跟交集聯集差集操作
本身是可變動,如果想要不可變動的集合類型
可以使用frozenset()來建立(有實作__hash__()方法,為hashable物件)
91.映射類型
可以把hashable物件映射至一個任意值
內建是dict
92.deque類型
有佇列或雙向佇列的需求 先進先出
可以用collections模組的deque類別
在兩端可以做插入跟移除
o(1)時間複雜度
append(),pop(),insert(),appendleft(),popleft()
rotate還可以指定要轉幾個元素
ex.
from collections import deque
deque = deque([1, 2, 3])
deque.appendleft(0)
deque.appendleft(-1)
print(deque)
print(deque.pop())
print(deque.popleft())
print(deque)
>>>deque([0, 1, 2])
deque.rotate(1)
>>>deque([2, 0, 1])
93.namedtuple函式
tuple狀態不可變,比較省記憶體,而且是hashable可以當set的元素或dict的鍵
namedtuple可以有欄位名稱
namedtuple(typename,field collection…)第一個參數是要建立的型態名稱,第二個是欄位名稱
ex.
from collections import namedtuple
point = namedtuple('point',['x', 'y'])
p1 = point(10, 20)
print(p1.x)
print(p1.y)
p2 = point(11, y=22)
print(p2)
x, y = p1
print(x)
print(y)
#如果來源是iterable物件
lt = [30, 40]
print(point(*lt))
#這樣也可以
print(point._make(lt))
#傳回欄位名稱與值
print(p1._asdict())
print(p1._replace(x=20))
#傳回全部欄位名稱
print(point._fields)
point3d = namedtuple('point3d',point._fields + tuple('z'))
print(point3d(10, 20, 30))
#docstrings
point.__doc__ = 'coordinate system (x, y)'
point.x.__doc__ = 'coordinate system x'
point.y.__doc__ = 'coordinate system y'
94.ordereddict類別
dict沒辦法直接排序,除非拿keys() 然後用for迴圈
可以用collections模組的ordereddict 建立的時候會保有dict最初鍵值加入的順序
ex.
from collections import ordereddict
from operator import itemgetter
origin = {'a':85, 'b':90, 'c':70}
#依值排序
print(ordereddict(sorted(origin.items(), key = itemgetter(1))))
95.defaultdict類別
collections模組的
接受一個函式,建立的實例在當指定的鍵不存在,就會使用指定的函式來產生,並直接設定為鍵的對應值
96.counter類別
collections模組
可以用來計算字串中出現的字元數
ex
from collections import counter
c = counter('your right brain has nothing left.')
print(c)
print(list(c.elements()))
也可以指定dict給counter,會依照dict中值的指定建立對應數量的鍵
97.
如果想合併兩個dict可以用update
ex.
cust1 = {'a':'justin', 'b':'monica'}
cust2 = {'c':'irene', 'd':'kuan'}
custs = {}
#合併
custs.update(cust1)
custs.update(cust2)
或是使用collections模組的chainmap
ex. temp = chainmap(cust1,cust2)
底層是使用list來維護指定的dict,也比較有效率
如果要更新某個鍵值,會在底層第一個找到key的dict更新,但是都找不到的話會直接在第一個dict新增key-value
底層的list可以透過maps屬性取得
ex.temp.maps
如果想在既有的chainmap新增dict,可以在maps屬性上使用append()方法
或是用new_child()指定
想建立一個新的chainmap但不包含來源的第一個dicy,可以使用parents屬性(個人覺得用不到)
98.如果要根據自己需求實作群集
想用[]取值可以實作__getitem__
想用[]設值可以實作__setitem__
用del 或[]刪除可以實作__delitem__
也可以直接繼承abc模組,裡面有定義好該實作的方法
from collections.abc import mutablemapping
mutablesequence,mutableset,
mapping/sequence/set 並不是dict/list/set的子類別,只是擁有行為
99.如果只是要基於str,list,dict等行為增加自己的方法定義
也可以使用collections模組的userstring、userlist、userdict
100.序列化python物件可以使用pickle模組
直接import pickle
序列化的時候會把物件轉為bytes,稱為pickling,可以用dumps()函式
相反的操作稱為unpickling,可以用loads()函式
ex.
cus = {'a':123456, "b":789456}
pickled = pickle.dumps(cus)
print(pickled)
print(pickle.loads(pickled))
如果無法pickling或unpickling就會引發picklingerror或unpicklingerror
(父類別是pickleerror)
如果是想把bytes保存在檔案,dumps()跟loads()都有file參數可以用,檔案物件必須是二進位模式
ex.
with open(self.filename, 'wb') as fh:
pickle.dump(self, fh)
with open(filename, 'rb') as fh:
return pickle.load(fh)
101.shelve模組
shelve物件行為像是字典的物件,key必須是字串,值可以是pickle模組可處理的python物件,他直接與一個檔案關聯,因此使用上就像一個簡單的資料庫
ex.
import shelve
dvd = shelve.open(‘dvdlib.shelve’)
dvd[‘birds’] = (2016, 1, ‘justin’)
dvd.close()
dvd = shelve.open(‘dvdlib.shelve’)
dvd.sync()
close()或async()資料就會儲存到檔案
102.資料庫連線db-api 2.0
connection的基本方法
|
close() |
關閉料庫連線 |
|
commit() |
將尚未完成的交易提交 |
|
rollback() |
將尚未完成的交易撤回 |
|
cursor([cursorclass]) |
傳回一個cursor物件,代表基於目前連線的資料庫游標,所有跟資料庫溝通都是透過cursor物件 |
cursor物件的基本方法
|
close() |
關閉目前cursor物件 |
|
execute(sql,[,params]) |
執行一次sql指令,可以是query或command |
|
executemany(sql,seq_of_params) |
針對seq_of_params序列或映射中每個項目執行一次sql語句 |
|
fetechone() |
從查詢的結果集取得下一筆資料 |
|
fetchmany([size]) |
從查詢的結果集取得多筆資料 |
|
fetchall() |
從查詢的結果集取得全部資料 |
如果只是要測試用可以用sqlite3模組,本身的資料可以存在檔案或記憶體
103.sqlite資料庫操作
(1)建立連線
conn = sqlite3.connect(‘xxx.sqlite3’)
conn.close()
第一次執行會建立一個檔案,也可以傳一個’:memory:’字串,就會在記憶體建立資料庫
(2)建立表格
c = conn.cursor()
c.execute('''create table messages (
id integer primary key autoincrement unique not null ,
name text not null ,
email text not null ,
msg text not null
)''')
#預設不會自動提交變更 要用commit
conn.commit()
conn.close()
以上可以用情境管理器自動commit&close 發生例外會rollback
with sqlite3.connect('db.sqlite3') as conn:
c = conn.cursor()
c.execute("insert into messages values (1, 'justin','kuan@gmail.com','message...')")
(3)查詢
c = conn.cursor()
c.execute('select * from messages')
print(c.fetchall())
cursor本身是迭代器,每一次迭代會呼叫cursor的fetchone()方法
- 更新或刪除
c.execute("update messages set name = 'kuanfu lin' where id = 1")
print(list(c.execute('select * from messages')))
104.sql cmd參數化,避免sql injection
第一種可以用”?”
ex.
querystr = “select * from messages where name =? and id=?”
c.execute(querystr),(name, id)
第一個參數放查詢字串,第二個指定一個tuple,元素順序對應?的順序
第二種可以用具名佔位符號,要加上冒號當前導字元
querystr = “select * from messages where name =:name and id=:id”
c.execute(querystr),{‘name’:’kuan’, ‘id’:4})
第二個參數是用dict指定實際資料
如果有多筆資料要操作的話,可以用executemany()
105.交易的特性
原子性atomicity:交易是一個單元工作,裡面每個步驟(sql指令)必須全部成功(commit)不然就是全部失敗(rollback),需要定義一個交易邊界(begin)
一致性consistency:所有資料集合在交易前後必須前後一致
隔離行為isolation behavior:交易跟交易之間不互相干擾
預設會鎖定資料,timeout時間是5秒
connection有isolation_level屬性,可以設定目前的隔離設定,預設是’’,設成none表示不做任何隔離
持續性durability:交易一但成功,變更必須保留下來
106.sqlite3的模組預設不會自動commit,要自己呼叫commit跟rollback
或是直接把程式包在情境管理器裡面
107.csv模組
可以用reader()讀取csv檔案
可以接受iterable物件
ex.
with open('mi_5mins_hist10505.csv', encoding='utf-8') as f:
with open('test.csv', 'w', encoding='utf-8', newline='') as wf:
for row in csv.reader(f):
print(row)
rows = csv.reader(f)
csv.writer(wf).writerows(rows)
預設的csv偏好格式是['excel', 'excel-tab', 'unix']
可以用csv.list_dialects()來得知有哪些
使用reader可以指定dialect參數指定偏好格式
delimiter可以指定分隔符號csv.reader(file, delimiter =’ ’)
quotechar指定引號字元
csv.writer()可以轉成csv檔,裡面放list,每個元素就是一列
108.dictreader,dicrwriter
可以把csv以dict的方式處理
ex.
import csv
custs = [
'first,last',
'justin,lin',
'monica,huang',
'irene,lin'
]
for row in csv.dictreader(custs):
print(row)
>>>
{'first': 'justin', 'last': 'lin'}
{'first': 'monica', 'last': 'huang'}
{'first': 'irene', 'last': 'lin'}
指定欄位名稱的方式
for row in csv.dictreader(custs,fieldnames=['firstname','lastname']):
print(row)
>>>
{'firstname': 'first', 'lastname': 'last'}
{'firstname': 'justin', 'lastname': 'lin'}
{'firstname': 'monica', 'lastname': 'huang'}
{'firstname': 'irene', 'lastname': 'lin'}
把dict寫進csv檔
ex.
temp = [
{'firstname': 'first', 'lastname': 'last'},
{'firstname': 'justin', 'lastname': 'lin'},
{'firstname': 'monica', 'lastname': 'huang'},
{'firstname': 'irene', 'lastname': 'lin'}
]
with open('sample.csv', 'w', newline='') as f:
writer = csv.dictwriter(f, fieldnames=['firstname','lastname'])
writer.writeheader()
writer.writerows(temp)
109.json的序列化
json.dumps()
參數:
sort_keys :可以指定true或false 根據鍵排序
indent :可以加上指定數字的空白數量計行縮排
separators:分隔符號 可以指定 (',', ':'),預設是(', ', ': ')
ex.
import json
obj = {
'name': 'kuan',
'age': 40,
'childs': [
{'name': 'irene',
'age': 8}
]
}
print(json.dumps(obj, sort_keys= true, indent = 4,separators= (',', ':')))
以上是針對內建型態才可以轉,如果是自訂類別要實作轉換函式
加上default參數,否則會有typeerror
如果是要把json字串轉成內建型態,可以用json.loads()
轉成自訂型態要指定一個轉換函式給object_hook參數
110.處理xml
模組:
xml.dom:基於w3c規範
需要把整個文件載入進行剖析
xml.sax :基於sax 是非正式的規範,不會一次讀取整份文件,是基於事件的api,一邊讀一邊剖析
xml.etree.elementtree:建議使用,以上兩個的折衷,iterparse()也可以做到一邊讀一邊處理
可以把xml檔案用parse()載入,他會傳回elementtree實例,可以用getroot()取得根節點,這會傳回一個element實例,一個element就代表一個標籤元素
ex.
import xml.etree.celementtree as et
#取得全部標籤名稱
def show_tags(elem, ident = ' '):
print(ident + elem.tag)
for child in elem:
show_tags(child, ident + ' ')
tree = et.parse('country_data.xml')
show_tags(tree.getroot())
取得標籤上的屬性值 可以用attrib ,回傳一個dict,key value分別是屬性名稱跟值
element的text屬性可以取得標籤中的文字
fromstring()方法可以把xml字串轉成element實例
find(),findall(),iterfind()可以指定xpath取得想要的標籤
et.tostring()可以直接取得xml字串的bytes資料
修改xml
append():附加元素
insert():插入元素
remove():移除元素
set():設定元素屬性
如果想要一邊讀取一邊剖析,可以使用iterparse()
針對標籤的’start’,’end’,’start-ns’,’end-ns’事件發生時進行相對應的處裡
111.
utc時間 >世界協調時間
unix時間 > utc時間1970年1月1日 00:00:00為起點經過的秒數
目前的時間即使是gmt或api日期時間描述都是指utc時間
秒的單位定義是基於tai(銫原子幅射震動次數)
eposh:某個特定時間的起點,時間軸上某一瞬間
ex unix epoch選為utc時間1970/1/1 00:00:00
一年的秒數不是用365*24*60*60
ex.可以用time模組取得時間
tm_isdst目前時區是否處於日光節約時間 1是0否-1未知
import time
print(time.gmtime(0)) #utc時間1970年
print(time.time())
回傳struct_time實例
time.gmtime()是取得目前時間
time.localtime()可以取得目前所在時區時間
112.剖析時間字串
可以用strptime()函式
第一個參數放時間字串
第二個放格式設定
回傳一個struct_time物件
可用格式可參考time.strftime(()說明
strftime()接收一個strust_time實例,可以自訂日期格式
ex.
d = time.strptime('2016-05-26', '%y-%m-%d')
print(d)
如果有struct_time物件想轉換成秒數可以用mktime()
print(time.mktime(d))
自訂格式
print(time.strftime('%d-%m-%y', d))
113.時間字串格式
ctime():不指定數字會用time()取得的值(秒數)
ctime(secs)是asctime(localtime(secs))的封裝
asctime():可取得struct_time實例,不指定就使用localtime()回傳值
取得一個簡單的時間字串描述
ex.
print(time.ctime())
print(time.asctime())
>>> mon dec 16 17:33:18 2019
114.datetime模組
datetime():日期&時間
date():只有日期
time():只有時間
預設沒有時區資訊,單純用來表示日期或時間概念
會判斷基本範圍,有錯會拋出valueerror例外
ex.
import datetime
d = datetime.date(1975, 5, 26)
print(d.year, d.month, d.day)
t = datetime.time(11, 41, 35)
print(t.hour, t.minute, t.second, t.microsecond)
dt = datetime.datetime(1975, 5, 26, 11, 41, 35)
print(dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second)
使用今天日期建立datetime或date實例
from datetime import datetime, date
print(datetime.today())
print(date.today())
print(datetime.now())
print(datetime.utcnow())
>>>
2019-12-16 11:16:53.171571
2019-12-16
2019-12-16 11:16:53.171570
2019-12-16 03:16:53.171570
時間字串描述跟剖析
date跟time會用T隔開
datetime.now().isoformat()
>>> 2019-12-16T11:35:40.502158
也可以自行指定
datetime.now().isoformat(' ')
>>> 2019-12-16 11:35:40.502158
115.時間運算
可以用datetime類別的timedelta方法
有很多時間單位可以選,用整數或浮點數
ex.
print(datetime.now() + timedelta(weeks = 3, days= 5, hours = 8,minutes= 35))
如果要考慮日光節約時間
可以使用pytz模組
再用normalize()修正時間
或是建議用utc來進行時間的儲存或操作,因為utc是絕對時間,不考量日光節約時間,要使用當地時區的場合時,再用datetime實例的astimezone做轉換
116.logger
可以直接建立logging.logger類別實例,但是建議用logging.getlogger()取得
一般來說一個模組只需要一個logger實例
呼叫的時候可以指定名稱,相同名稱下取得的logger會是同一個實體
通常會使用__name__(在模組中就是模組名稱)
log層級
|
debug |
10 |
|
info |
20 |
|
warning |
30 |
|
error |
40 |
|
critical |
50 |
|
notset |
0 |
預設只有大於30的才會輸出,所以只看得到warning以上的
logger本身有setlevel()可以設定,但是logger有階層關係,每個logger處理完自己的日誌動作後,會再委託父logger處理,所以不改變父logger的組態情況下,只能設定更嚴格的層級
要調整根logger的組態可以用logging.basicconfig()
ex.
import logging
logging.basicconfig(level = logging.debug)
logger = logging.getlogger(__name__)
logger.log(logging.debug, 'debug 訊息')
logger.log(logging.info, 'info 訊息')
logger.log(logging.warning, 'warning 訊息')
logger.log(logging.error, 'error 訊息')
logger.log(logging.critical, 'critical 訊息')
除了log()方法指定等級
還可以用debug(),info(),warning(),error(),critical(),exception()
117.log輸出至檔案
預設會輸出到sys.stderr
父logger指定檔案名稱,子logger如果沒有設定處理器就會輸出到這個
logging.basicconfig(filename ='xxx.log')
子logger處理器
logger.addhandler(logging.filehandler(bbb.log'))
子logger處理器>父logger處理器
處理器可參考logging.handlers模組
118.格式化錯誤文字
可以使用logging.formatter搭配logging.streamhandler()自訂想顯示的錯誤訊息
119.過濾log錯誤訊息
可以繼承logging.filter並定義filter(record)方法
120.正規表達式
import re模組
ex. import re
re.split(r'\d','justin1monica2irene')
>>> ['justin', 'monica', 'irene']
前面記得加r表示式原始字串,就不用溢出字元
分組&參考
((a)(b(c)))
有4個分組,遇到的左括號來計數
1. ((a)(b(c)))
2.(a)
3.(b(c))
4.(c)
分組回頭參考時在\加上分組計數,表示參考第幾個分組的比對結果
ex.(\d\d)\1 表示要輸入4個數字,前2後2必須相同 >>1212
建立pattern物件,可重複使用
regex = re,compile(‘正規表達’)
可以指定flags參數 例如不分大小寫
ex.regex = re.compile(r’dog’,re.ignorcase)
也可以嵌入旗標表示法embeded flag expression
re.ignorcase的是(?i)
以上寫法等同於regex = re.compile(r’(?i)dog’)
比對方法
finditer():傳回一個iterable物件,每次迭代都得到一個match物件,可以用group()來取得符合的字串
search():找第一個符合的字串
match():只會在字串開頭比對
findall():會以清單找到各分組
sub():做字串取代
121.os模組
取得目錄資訊
import os
取得目前工作目錄os.getcwd()
切換工作目錄os.chdir(‘路徑’)
取得指定目錄下檔案或目錄os.listdir()
或os.scandir()傳回iterable的os.direntry實例 (is_dir(),is_file()方法)
建立目錄os.mkdir()
對目錄改名os.rename()
移除目錄os.rmdir()
移除檔案os.remove()
路徑的合併 os.path.join() 自動判斷要用\或/來做路徑區隔
122.debugger指令
指定想除錯的檔案
>>>python –m pdb xxx.py
l:列出程式碼
b 行數:要下中斷點的地方 再執行c (continue)
p 變數名稱:查看變數
n :step over
s:step into
r:step out
b:查看中斷點
cl 中斷點號碼:清除中斷點
l start, end:指定顯示哪一行
unt: until 直接執行程式到指定行數
q:離開pdb
restart:重新運行
可以把pdb.set_trace()直接寫在原始碼中
用repl執行程式的時候,可以除錯
發生錯誤的時候可以用pdb.pm()回到上一步
123.測試工具
assert陳述
doctest模組:找尋類似互動環境的文字片段,執行並驗證程式
unittest模組:pyunit,junit的實現
第三方測試工具(nose,pytest)
124.assert
語法
assert_stmt ::=”assert” expression [“,” expression]
相當於
if __debug__ :
if not expression: raise assertionerror
__debug__是內建變數,一般情況下會是true,如果執行需要最佳化時(python -o)則會是false
125.doctest
一方面是測試程式碼,也可以用來確認docstrings的內容沒有過期
只要撰寫repl形式的文件就可以了
用法:在’’’區塊中寫呼叫方法 跟結果
ex.
if __name__ == '__main__':
import doctest
doctest.testmod()
只有執行模組的時候會測試
要顯示細節可以用>>>python xxx.py –v
也可以用讀文字檔的形式
ex.
if __name__ == '__main__':
import doctest
doctest.testfile("util_doctest.txt")
126.unittest單元測試模組
或稱”pyunit” 是junit的python語言實現
要繼承unittest.testcase類別
單元測試要定義在test開頭的方法中
python執行的時候會自動找出方法並執行
ex.python –m unittest calc_test
名詞解釋
測試案例:測試的最小單元
測試設備:執行一個或多個測試前必要的預備資源,以及相關的清除資源動作
測試套件:一組測試案例、測試套件或兩者的結合
測試執行器:負責執行測試並提供測試結果的元件
如果有定義setup()方法>>執行每個test開頭方法前都會呼叫
如果有定義teardown()方法>>執行每個test開頭方法後都會呼叫
可以用來做每次單元測試前後的資源建立與銷毀
測試套件可以把不同測試案例組在一起
ex.
testcase中的某些測試方法
suite = unittest.testsuite()
suite.addtest(testcase(‘test_plus’))
suite.addtest(testcase(‘test_minus’))
或是用list
tests = [‘test_plus’, ‘test_minus’]
suite = unittest.ttestsuite(map(testcase, tests))
或是自動載入
suite = unittest.testloader().loadtestfromtestcase(xxx)
執行測試
suite = …….
unittest.texttestrunner(verbosity=2).run(suite)
verbosity可以顯示更詳細資料
127.timeit模組 測試效能
timeit.timeit(字串表示的程式片段,準備測試的材料)
會回傳執行秒數
效能是整體程式結合後的執行考量,並不是單一元素快慢的問題,也不是憑空猜測,而是要有實際的評測做依據
timeit預設是執行100萬次取平均,可以透過number參數控制
ex.
>>>timeit.timeit('strs=[str(n) for n in range(99)]', number = 10000)
>>> timeit.timeit('strs=(str(n) for n in range(99))', number = 10000)
>>> timeit.timeit('",".join([str(n) for n in range(99)])', number = 10000)
>>> timeit.timeit('",".join((str(n) for n in range(99)))', number = 10000)
128.執行緒模組
import threading
ex.threading.thread(target = 要執行的函式, args = (xx,))
target指定start()方法要執行的函式
args表示指定給函式的引數,使用tuple
必要的話可以繼承threading.thread,在__init__()呼叫super. __init__()
並在類別中定義run()方法實作執行緒功能,不過不建議這作法
python直譯器同時間只允許一個執行緒,所以不是真的平行處理
只是有時候切換速度快到感覺像同時處理
也就是目前的thread需要等待某個阻斷作業完成時,會先執行另一個執行緒
129.
執行緒適用的場合就是非計算密集的場合,與其等待阻斷作業完成不如先執行其他的
對於計算密集的任務,使用執行緒不見得會提高處理效率,反而因為必須切換執行緒耗費不必要的成本,使效率變差
130.如果一個thread被建立時,指定daemon參數是true,在所有非daemon執行緒都結束時程式就會直接終止
適用背景執行的任務
131.插入執行緒
可以用join(),會先等被加入的執行緒完成才會執行原本的
也可以加上時間指定最多處理幾秒
132.執行緒鎖定
threading.lock只有兩種狀態:鎖定與未鎖定
非鎖定狀態下可以用acquire()方法進入鎖定狀態
此時再呼叫就會被阻斷,直到其他地方呼叫release()使lock物件成為未鎖定
如果不是在鎖定狀態呼叫release()會拋出error
ex.
lock = threading.lock()
lock.acquire()
try:
程式區塊
finally:
lock.release()
或是搭配情境管理器
with lock:
程式區塊
其他鎖定機制
threading.rlock可重入鎖
可以重複呼叫同一個實例的acquire()方法
但是release()也要同樣次數才會釋放
133.condition
threading.condition()
透過aquire()取得鎖定後,需要在特定條件符合之前等待,可以呼叫wait()方法,會釋放鎖定,如果其他執行緒完成條件可以呼叫notify()方法,通知等待條件的thread可以取得鎖定,會從上次wait的地方繼續執行
notify()不能預期是哪個會被通知,或是可以呼叫notifyall(),會通知全部在等態的爭取鎖定
134.如果需要一進一出,在執行緒之間交換資料的方式,可以用queue.queue
建立實例可以指定容量
put():插入資料
get()取得資料
135.subprocess模組可以讓你在執行python的過程中產生新的子行程subprocess.run()
stdout=subprocess.pipe可以讓執行結果轉到程式內部
透過p.stdout讀取
ex.
p = subprocess.run(['python', 'hi.py'], input = b'justin\n', stdout = subprocess.pipe)
p.stdout
run()底層是透過popen()實作的
會傳回一個popen()實例,可以透過communite()指定input
communite()回傳一個tuple,分別是標準輸出與錯誤的結果
136.想要以子行程執行函式,使用類似threading的api可以使用multiprocessing模組
multiprocessing.process()
也有target參數跟args
如果需要共享狀態,可以用multiprocessing.queue()
執行結果用put()方法置入
get()取得結果
multiprocessing 可以建立worker pool
利用pool實例派送任務,取得multiprocessing.pool.asyncresult實例,完成後取得結果
ex.
with multiprocessing.pool(2) as pool:
#派送任務
results = [pool.apply_async(foo, (filename,))
for filename in filenames]
#取得結果
count = sum(result.get() for result in results)
print(count)
137.
一個物件可以被稱為描述器(descriptor)要有三個方法
def __get__(self, instance, owner):
def __set__(self, instance, value):
def __delete__(self, instance):
描述屬性的取得、設定、刪除要怎麼處理
三個方法都具備稱為資料描述器
若只有__get__()方法的稱為非資料描述器
資料描述器可以攔截對實例的屬性取得、設定跟刪除行為
非資料描述器是用來攔截透過實例取得類別屬性時的行為
138.定義__slots__
如果想控制可以指定給物件的屬性名稱,可以定義類別時指定__slots__
這屬性要是字串清單,列出可指定給物件的屬性名稱
這些屬性會存在類別的__dict__中,但要先指定值才能存取
但是要注意類別建構的實例不會有__dict__屬性
或是你自己把__dict__包含在__slots__中
這樣如果指定的屬性不在__slots__就會被放到__dict__裡面
__slots__裡面的屬性會被實作成描述器
最好被當成類別屬性來使用
父類別的__slots__只能透過父類取得
子類相同
139.取得屬性的順序
實例的__getattribute__()>資料描述器的__get__()>實例的__dict__>非資料描述器的__get__()>實例的__getattr__()
__getattribute__()會攔截所有對屬性的尋找
__getattr__()是作為尋找屬性的最後一個機會
140.設定屬性的順序
實例的__setattr__()>資料描述器的__set__()>實例的__dict__
__setattr__()會攔截所有對屬性的設定
141.刪除屬性的順序
實例的__delattr__()>資料描述器的__delete__()>實例的__dict__
142.函式裝飾器本質就是一個函式可接受函式並回傳函式
python的裝飾器可以用@標註
ex.
def sidedish1(meal):
return lambda: meal() + 30
@sidedish1
def friedchicken():
return 49.0
也可以堆疊裝飾器,會從下往上執行
如果裝飾器需要帶有參數,用來作為裝飾器的函式,必須先以指定的參數執行一次,傳回一個函式物件再來裝飾指定的函式
ex.
@deco(‘param’)
def func():
pass
實際執行時
func = deco(‘param’)(func)
143.類別裝飾器
同函式裝飾器,但是標註在class上,接受類別並傳回類別
要注意裝飾器跟被裝飾的類別要定義相同方法
如果類別上定義__call__()方法,建構的實例可以用()傳入引數,此時會呼叫__call__()方法
ex.
class sidedish1:
def __init__(self, func):
self.func = func
def __call__(self):
return self.func() + 30
@sidedish1
def friedchicken():
return 49.0
>>> friedchicken()
>>>79
144.方法裝飾器
可以對類別上的方法進行裝飾
選擇使用函式或類別來實作
方法的第一個參數總是類別的實例本身
145.物件是類別的實例,類別是type的實例,如果有方法能介入type建立實例與初始化的過程,就可以改變類別的行為>>meta類別
一個繼承type的類別可以作為meta類別
metaclass是個協定,python剖析完類別定義後會使用指定的metaclass來進來類別的建構與初始化
__call__()方法預測會呼叫__new__()跟__init__()方法
藉由metaclass = metaclass的協定,可在類別定義剖析完後繞送至指定的meta類別,可以定義meta類別的__new__()方法,決定類別如何建立,定義meta類別的__init__(),則可以決定類別如何初始,定義__call__()方法決定使用類別來建構物件時該如何進行物件的建立與初始
146.相對匯入套件
同個package有abc.py跟def模組
要在def匯入abc可以寫from . import abc
如果想在import pkg1 時直接使用pkg1.abc模組或套件中其他模組
可以在pkg1的__init__.py中寫
from . import abc