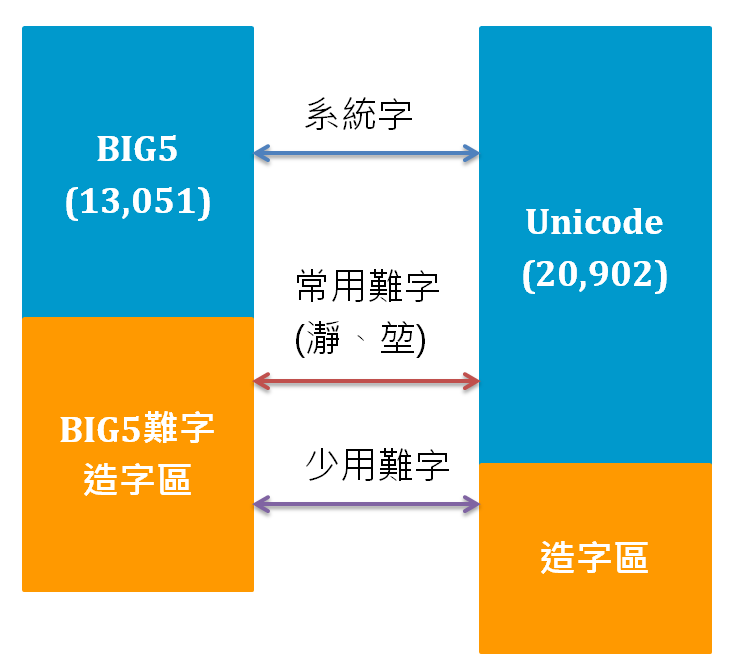
要將BIG5中被定義成難字但Unicode中有支援的系統字寫入資料庫,筆記兩個關鍵:
- 寫入值時的前置詞N(表示Unicode)
- 資料庫欄位資料型別NCHAR、NVARCHAR(Unicode)
中文儲存時的編碼系統選擇
在繁體中文定序的SQL Server環境下,儲存中文姓名欄位時,字碼頁通常會有兩個選擇:
- BIG-5
- Unicode(UCS2)
由於Unicode 2.0 編碼可以支援到20,902個中文字,而BIG5編碼則只支援字數只有13,051個字,為了避免AP需要處理到造字客製的問題,習慣在使用中文字時,直接使用Unicode編碼,儲存時也用Unicode編碼,減少需要轉碼的機會。
測試中文難字寫入
水字旁加上安靜的"瀞"在BIG-5中需要造字,在Unicode則在標準的系統字碼區就有支援,為了將這類型的字順利寫到資料庫中,嘗試以下幾種 字串欄位編碼型別 x t-sql有無Unicode前置詞 範例組合:
1.這邊簡單建立一個資料表,其中內含兩個欄位C1及C2,C1採用Varchar(因為預設定序是Chinese_Taiwan_Stroke_CI_AS,所以會用BIG5儲存),C2採用Nvarchar(Unicode儲存)。
CREATE TABLE TESTWORD(
RID INT IDENTITY,
C1 varchar(10),
C2 nvarchar(10)
)
2.在SSMS查詢視窗中寫入資料兩次,第一次在T-Sql不帶前置詞N寫入Unicode字串中的值:瀞,第二次則帶前置詞N,標示寫入的字串是Unicode。
INSERT INTO TESTWORD
VALUES ('瀞', '瀞')
INSERT INTO TESTWORD
VALUES (N'瀞', N'瀞')
*當我們在查詢視窗鍵入"瀞"時,她就是Unicode編碼了。
3.查詢寫入後的內碼
SELECT
C1,CONVERT(VARBINARY, C1) AS C1BINARY,
C2,CONVERT(VARBINARY, C2) AS C2BINARY
FROM TESTWORD
查詢結果集

{kind=link}
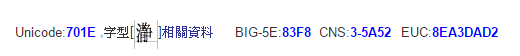
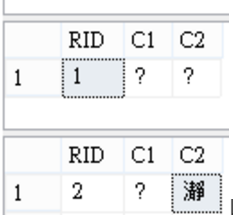
看來只有N x N 的組合成功寫入了。
(0x3F 為問號?的內碼)
沒有前置詞N:
- 欄位C1:案例資料庫會以BIG5編碼系統儲存,但SQL沒有BIG5造字的對照,SQL沒辦法將T-SQL語法內的Unicode字串轉換BIG5造字區,所以轉換成問號了。
- 欄位C2:資料型別是NVARCHAR(Unicode),但因為字串值"瀞"沒有加上前置詞N,會被誤判成BIG5而進行轉換,寫入前就是問號了。
有前置詞N:
- 欄位C1.語法是Unicode,順利通過護照查驗,出關之後要儲存成BIG-5,需要轉換,但SQL並不知道造字的對照,還是沒辦法將Unicode系統字[瀞] 轉換到BIG-5造字區字碼,寫入後結果還是問號。
- 欄位C2.寫入時加上前置詞N,中間不會轉碼,則可以正確將Unicode[瀞]寫入Unicode!!
(參考CNS11643網站,701E是瀞的內碼,因為位元組順序的選擇(高低位字碼),呈現是0x1E70)
查詢資料時
查詢C1:VARCHAR欄位
SELECT * FROM TESTWORD
WHERE C1 = '瀞'
SELECT * FROM TESTWORD
WHERE C1 = N'瀞'
執行結果:

- 沒有前置詞N:因為SQL還是看不懂怎麼從Unicode語法中的[瀞]字串轉成BIG-5造字區字碼,因此只能拿問號?去資料庫比較,因此查詢到2筆C1是問號的結果集。
- 有前置詞N: 用Unicode的內容來查C1欄位,因為C1欄位值都是問號,因此查不到資料。
查詢C2:NVARCHAR欄位
SELECT * FROM TESTWORD
WHERE C2 = '瀞'
SELECT * FROM TESTWORD
WHERE C2 = N'瀞'
執行結果:
- 沒有前置詞N:因為SQL還是看不懂怎麼從Unicode語法中的[瀞]字串轉成BIG-5造字區字碼,因此只能拿問號?去資料庫比較,可以查詢到1筆C2是問號?的資料列。
- 有前字詞N:查詢條件內的字碼及欄位字碼相符,才能查詢到正確資料列。
這一篇將BIG5難字寫入Unicode中並進行查詢,下一篇來實作將BIG5難字寫入BIG5字碼(VARCHAR/CHAR)欄位。