中文博大精深,剛好負責的資訊系統會儲存客戶的中文姓名和地址,而中文姓名關係著八字五行、三才五格還有市場熱門度,取一個很命中缺什麼補什麼的名字是命理老師的專業,所以系統中時常會出現許多特別的古文字或是自創字也是相當合理自然的一件事。
曾碰過幾家客戶,內部大多系統使用BIG5,BIG5難字個數從數百到數千都有,不過Unicode 2.0比BIG5多支援了7,851個中文字,用上Unicode的data Type(NCHAR、NTEXT..)都能解掉中文字儲存上的問題,即使客戶也用上Unicode造字區,也有6,217個造字區能使用,但最近同事在一家客戶碰到了造字使用上了Unicode補充字集(Supplementary Character),這個快要還給百敬老師的技術,今天來重溫補充字集的儲存方式。
什麼是補充字集
1996年Unicode 2.0,也就是我們常稱的UCS-2編碼,他使用了16-bit value (也就是2 Byte)儲存字碼,標準範圍 U+0000 to U+FFFF,區域內共支援了20,902個中文字,後來為了支援更多語系的文字,新的編碼UTF-16使用了2個16-bit value (也就是4 Byte)儲存字碼,儲存範圍從 U+10000 to U+10FFFF,這個範圍的字,也就是我們稱的補充字集(supplementary characters),不過雖然範圍很大,但也不是全部使用在中文上,而且中文也有繁簡區域的使用。
簡單畫一個長條圖來示意各種編碼系統支援中文字數統計,橘色區域就是補充字集區。
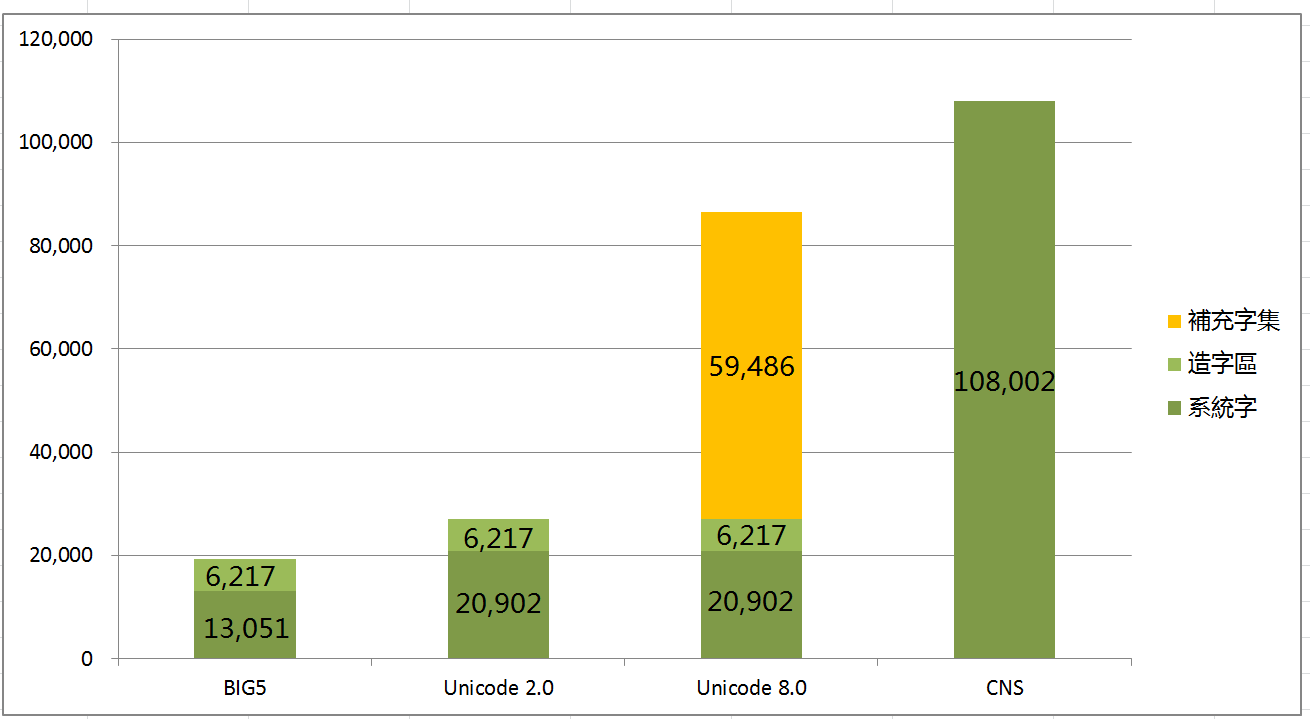
- Unicode 2.0是1996年版
- CNS11643也就是俗稱的國家標準碼,國標碼。
- Unicode 8.0是2014第一修訂版
補充字集支援
是不是可以儲存補充字集與定序(Collate)是否選擇到支援的定序有關,我們在建立資料庫時,通常會依照SQL Instance的預設定序,而Instance在安裝時會依照Windows定序帶出來作為預設。
以下我們分別使用對照組和實驗組觀察兩個資料庫是否可以寫入補充字。
- 對照組:Chinese_Taiwan_Stroke_CI_AS
- 實驗組:Chinese_Taiwan_Stroke_90_CI_AS_SC
對照組模擬:
這邊我們直接選台灣繁體中文最常見的Chinese_Taiwan_Stroke_CI_AS。
CREATE DATABASE [DB1]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'DB1', FILENAME = N'C:\temp\db\DB1.mdf' , SIZE = 5120KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'DB1_log', FILENAME = N'C:\temp\db\DB1_log.ldf' , SIZE = 2048KB , FILEGROWTH = 10%)
COLLATE Chinese_Taiwan_Stroke_CI_AS
GO
定序(Collate)是一種用來決定比較及排序的規則,以Chinese_Taiwan_Stroke_CI_AS來說:
- Chinese_Taiwan: 如果資料行是儲存varchar 、char,是以BIG5編碼儲存。
- Stroke: 按照筆畫排序,另一種中文的排序是按照ㄅㄆㄇㄈ。
- CI: case insensitive,大小寫視為相同。
- AS: Accent sensitive,腔調字視為不同,在繁體中文裡不會碰到,歐語系就很多。
建立資料表
use db1
if object_id('db1.dbo.t1') is not null drop table t1
CREATE TABLE T1(
C1 NVARCHAR(10),
C2 VARCHAR(10)
)
來寫入一個補充字和系統字。
下面這個中文字念ㄦˋ,門閂多一橫,是補充字的成員。
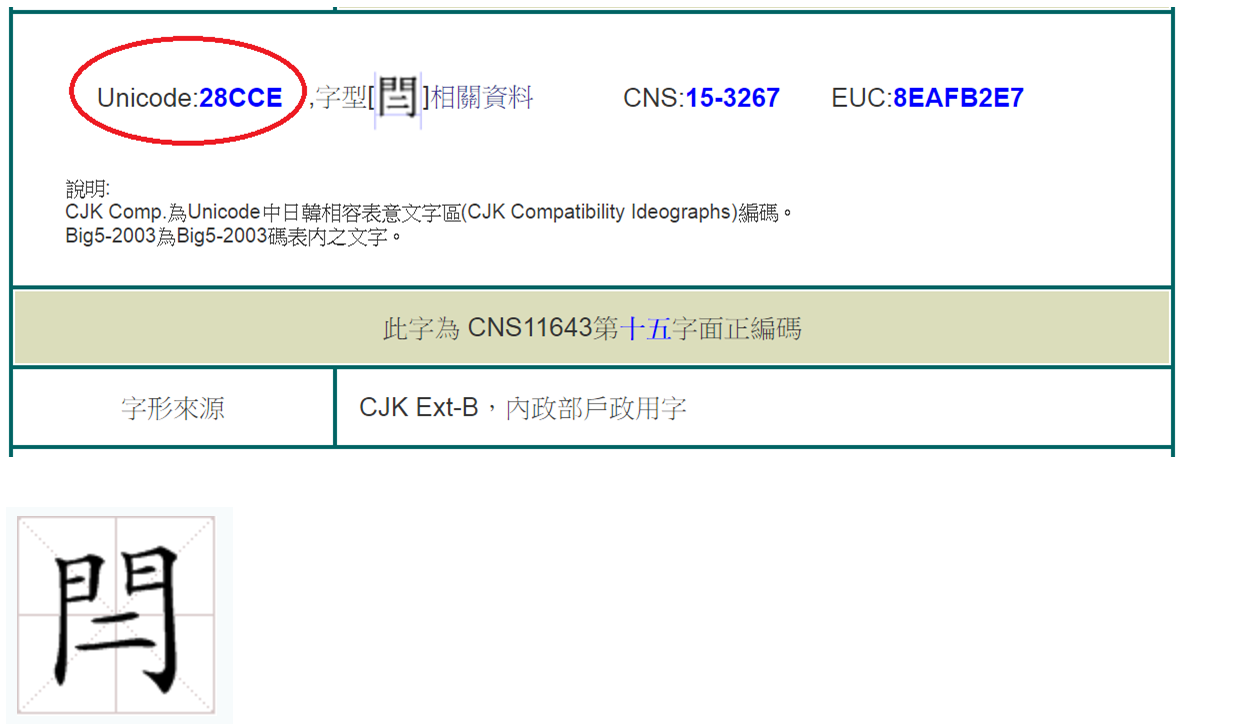
寫入後進行查詢
INSERT INTO T1 VALUES(NCHAR(0x28CCE),'1')
INSERT INTO T1 VALUES(NCHAR(0x8863),'2')
SELECT * from t1
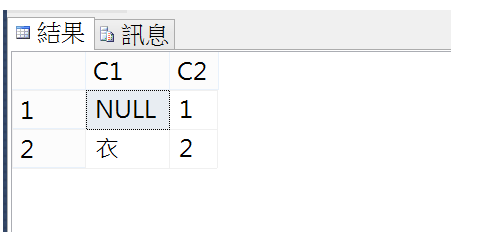
第一個補充字:門閂多一橫[ㄦˋ]果然無法轉換,因此寫入資料表時是Null值,第二個衣服的[衣]則是系統字,輕鬆的寫入。
支援補充字的繁體中文定序
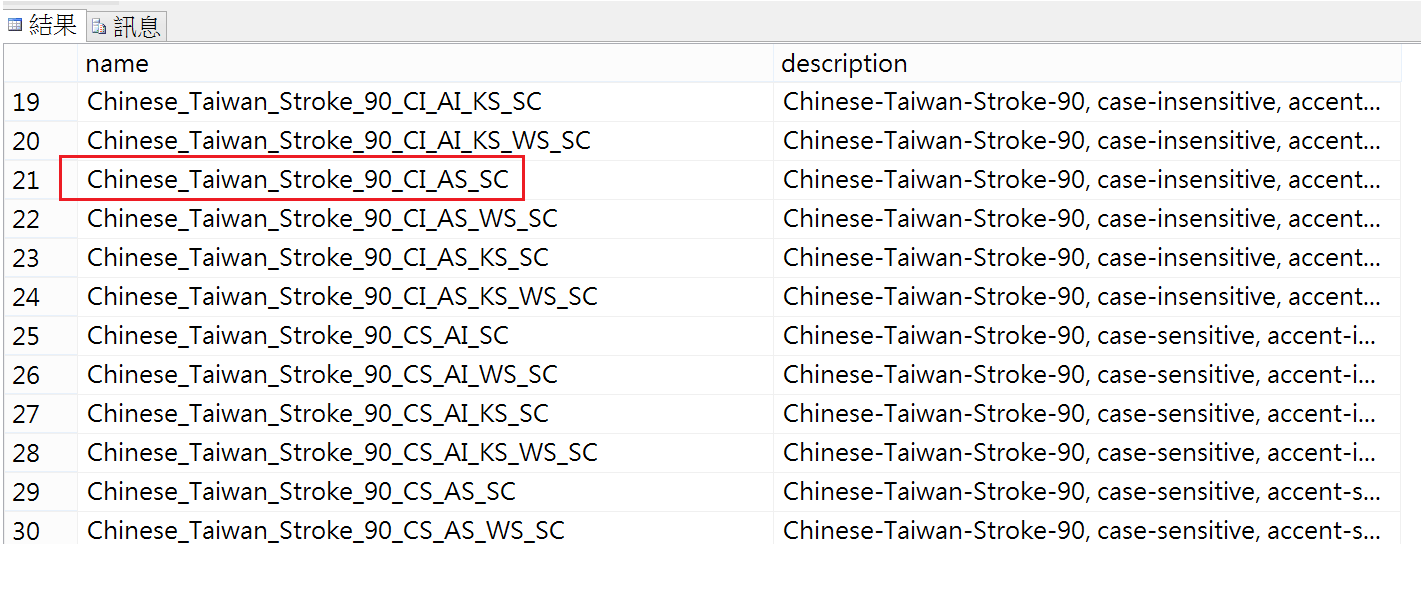
因為要使用unicode補充字集,我們必須把定序改成_SC結尾的定序,像是支援繁體中文的有32種
SELECT name, description FROM fn_helpcollations()
where name like '%_SC'
and name like '%Taiwan%'
實驗組模擬:
好,那我們重新建立一個新資料庫來試試。
CREATE DATABASE [DB2]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'DB1', FILENAME = N'C:\temp\db\DB2.mdf' , SIZE = 5120KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'DB1_log', FILENAME = N'C:\temp\db\DB2_log.ldf' , SIZE = 2048KB , FILEGROWTH = 10%)
COLLATE Chinese_Taiwan_Stroke_90_CI_AS_SC
GO
建立資料表並且寫入後進行查詢
use db2
if object_id('db1.dbo.t1') is not null drop table t1
CREATE TABLE T1(
C1 NVARCHAR(10),
C2 VARCHAR(10)
)
INSERT INTO T1 VALUES(NCHAR(0x28CCE),'1')
SELECT * from t1
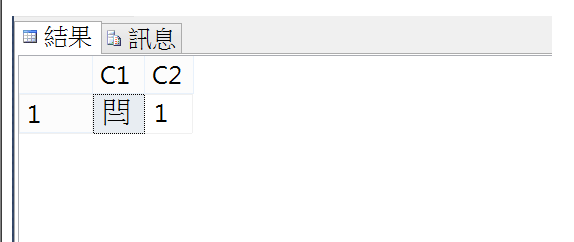
正確顯示補充字集ㄦˋ了。
小結:
- 所以儲存補充Unicode字集關鍵就是新建一個資料庫,然後選_sc結尾的定序名稱。
- 補充Application的部分,一般來說,我們會使用UTF8處理字串,但如果要使用Unicode補充字集時,需要改用UTF-32儲存(每個字佔4Byte)。
後記:
tempdb 定序衝突(collation conflict)