網站爬蟲發生HTTP 403 Forbidden
近期需要蒐集食譜資料
為了減少時間人工蒐集時間
因此使用網頁爬蟲方法來取得資料
使用HtmlAgilityPack來爬資料
首先要將資料取回來
需要使用WebClient將網頁資料取回來再做解析動作
結果發生以下錯誤
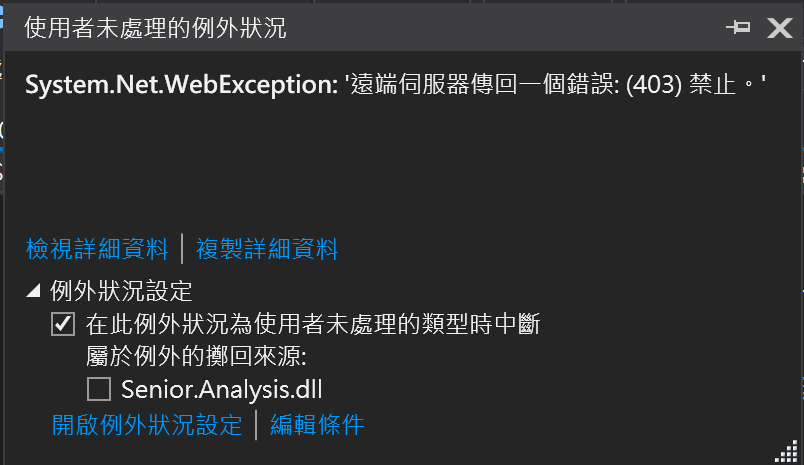
錯誤原因
使用WebClinet下載網頁時候Request header無帶User-Agent
解決方式
於程式中加入以下參數
_webClient.Headers.Add(HttpRequestHeader.UserAgent, "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko");
結論
若是以人工方式將網頁另存成html然後再進行爬蟲作業會正常取得資料,因為在瀏覽進該網站時候,Request的標頭是有帶User Agent,因此另存的網頁資料是正常的,若要以程式方式進行爬蟲作業,需要於Request Header上加上參數,才能正常將資料取回
參考資料
https://stackoverflow.com/questions/3272067/webclient-403-forbidden
http://www.petekcchen.com/2010/10/get-http403-using-webclient.html
https://ithelp.ithome.com.tw/questions/10190169?sc=rss.qu
http://shaurong.blogspot.com/2017/03/useragent.html