發現自己不瞭解Index所以想要記錄一下....
索引作爲提高SQL server查詢效能途徑之一,通常來説也是最快看到效果,最有效的,所以在遇到資料庫查詢效能問題的時候往往是第一個出現在DBA或Developer腦海裏。正確建置的索引能提高query查詢資料的效能(速度),減少query花費的資源。
當一個資料表(Table)沒有叢集索引時,我們稱之為Heap(堆叠)。堆叠資料表的資料不是按照資料新增的順序做排序,所以在查詢語法時SQL server需要掃描資料表裏的每一筆資料,這個動作就是資料表掃描(Table Scan)。
當一個資料表有索引時,在資料存在Data page時就是依照索引的鍵值來排序並儲存。所以 SQL Server 將基於該索引鍵值和結構來定位 (透過指標) 資料位置,簡單來說只搜尋必要的資料頁,而這些資料頁已經包含使用者最終所需要的資料結果集,這樣的操作就稱為索引搜尋 (Index Seek)。
SQL server 索引大多數都是採用B-Tree結構。What is B-Tree?
下圖引用 https://www.red-gate.com/simple-talk/sql/learn-sql-server/sql-server-index-basics/
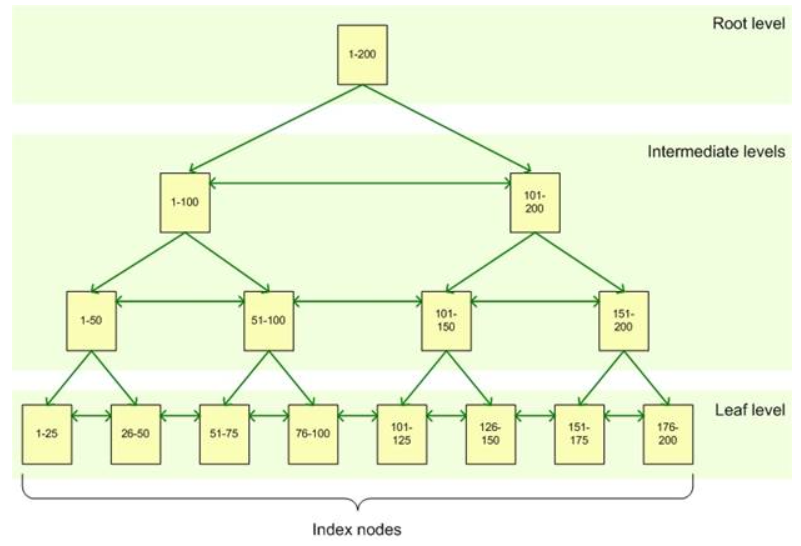
當資料表建置叢集索引時,資料會依照叢集索引鍵值順序來存放,所以一張資料表,檢視表(view)衹能有一個叢集索引。Clustered index 把實際資料存在索引的Leaf-Level。當資料表設立Primary key時,SQL server會自動建立叢集索引。
非叢集索引在分葉層級并不會存放是資料,而是存放row locator,這個row locator會指到實際資料存放的位置,這代表使用非叢集索引時,Query Engine需要多一步來找到實際資料。非叢集索引并不會真的把資料排序,所以一個資料表可以有多個非叢集索引。
索引雖然有很多的好處,但是在設計和建置時需要多注意。
1.因爲索引其實很占空間(Disk space),雖然現在硬碟很便宜..
2.當索引欄位資料被更新時,索引也會被自動更新,這會帶來額外的開銷,並影響效能。
3.索引需要維護,依據索引破碎率(index fragmentation)重建(rebuild) 或 重組(reorganise)。
4.索引應該建立在資料重複性不高的欄位。
參考:
https://blogs.technet.microsoft.com/technet_taiwan/2015/01/22/tsql-3/#b
https://www.red-gate.com/simple-talk/sql/learn-sql-server/sql-server-index-basics/
https://blog.sqlauthority.com/2010/07/04/sql-server-index-levels-page-count-record-count-and-dmv-%C2%A0sys-dm_db_index_physical_stats/