持續學習中.....
SQL server Query Optimizer(下稱Q.O) 使用 distribution statistics 來爲您的Query 定義出一個良好的執行計劃。在瞭解統計資料后,會幫助你改善及提升Query的效能問題。
當Q.O 建立一個Query Plan時會需要使用到統計資料,因爲統計資料提供了相關rows中,值(value)分佈的資訊。這樣的資訊能夠幫助Q.O 有效地預估執行結果的行數(Estimated of rows)或基數(Cardinality),並建立出一個效能好的執行計劃。舉個例子:Q.O會利用統計資料針對某個Query決定使用Index Scan/Index Seek, 如果沒有了統計資料,Q.O很難建立出好的執行計劃。
針對大部分資料表或Indexed View裏的特定Column,Q.O會負責建立以及更新大部分的統計資料。每一個Statistic 是一個資料表層級的物件,儲存了該統計資料裏第一個欄位的資料分佈狀況。如果統計資料建立在多個欄位上,那些相關的統計資料被稱爲密度(densities),密度在查詢優化裏扮演著重要的角色,但這不在我們這次的討論範圍内(XDD。
SQL server 利用直方圖來呈現在某個欄位中資料分佈的狀況(統計資料)。當你的Query的效能如你預期,那或許你不需要擔心/關心統計資料的直方圖,但如果你想要最大化查詢的效能或者解決一些效能的問題,那瞭解統計資料是如何被使用的或許能夠幫上忙。
當我們在資料表/indexed view 建立索引時,SQL server會自動建立該欄位的統計資料。例如說我們有一個table 叫Customer,當然建立customer時我們順手給了它一個Primary key欄位CustId。當Customer資料表被建立時,SQL server會自動在Custid上建立統計資料。
我們可以利用 SP_HELPSTATS 來獲取某個資料表上的統計資料。
--EXEC SP_HELPSTATS '<TableName>','ALL'
EXEC SP_HELPSTATS 'Customer','ALL'
或者用以下這段SQL
SELECT s.stats_id StatsID,
s.name StatsName,
sc.stats_column_id StatsColID,
c.name ColumnName
FROM sys.stats s
INNER JOIN sys.stats_columns sc
ON s.object_id = sc.object_id AND s.stats_id = sc.stats_id
INNER JOIN sys.columns c
ON sc.object_id = c.object_id AND sc.column_id = c.column_id
WHERE OBJECT_NAME(s.object_id) = 'Customer'
ORDER BY s.stats_id, sc.column_id;
兩段語法執行結果如下:
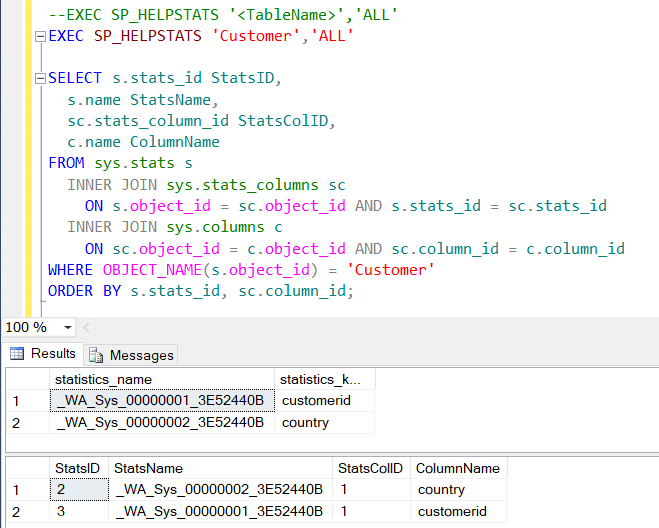
代表說我們在Selectivity table下的country和customerid欄位上各有一個統計資料。
除了在建索引時SQL server會自動幫你建立統計資料,當你在Query Predicate(謂詞)裏包含一個沒有統計資料的欄位時,SQL server也會為那個欄位建立統計資料。
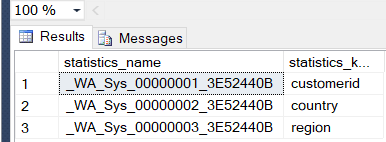
一開始Customer table上衹有兩個統計資料 : country 和customerid.
當我們下了這段Query后
SQL server會幫我們在region欄位上也建立統計資料(當 db option AUTO_CREATE_STATISTICS is on)。
我們可以利用DBCC SHOW_STATISTICS 來看到 統計資料直方圖。
語法如下:
--EXEC SP_HELPSTATS '<TableName>','ALL'
EXEC SP_HELPSTATS 'Customer','ALL'
--statistics_name statistics_keys
--_WA_Sys_00000001_3E52440B customerid
--_WA_Sys_00000002_3E52440B country
--_WA_Sys_00000003_3E52440B region
--DBCC SHOW_STATISTICS(<TableName>,'<StatisticName>')
DBCC SHOW_STATISTICS(Customer,'_WA_Sys_00000002_3E52440B')
GO
結果如下:
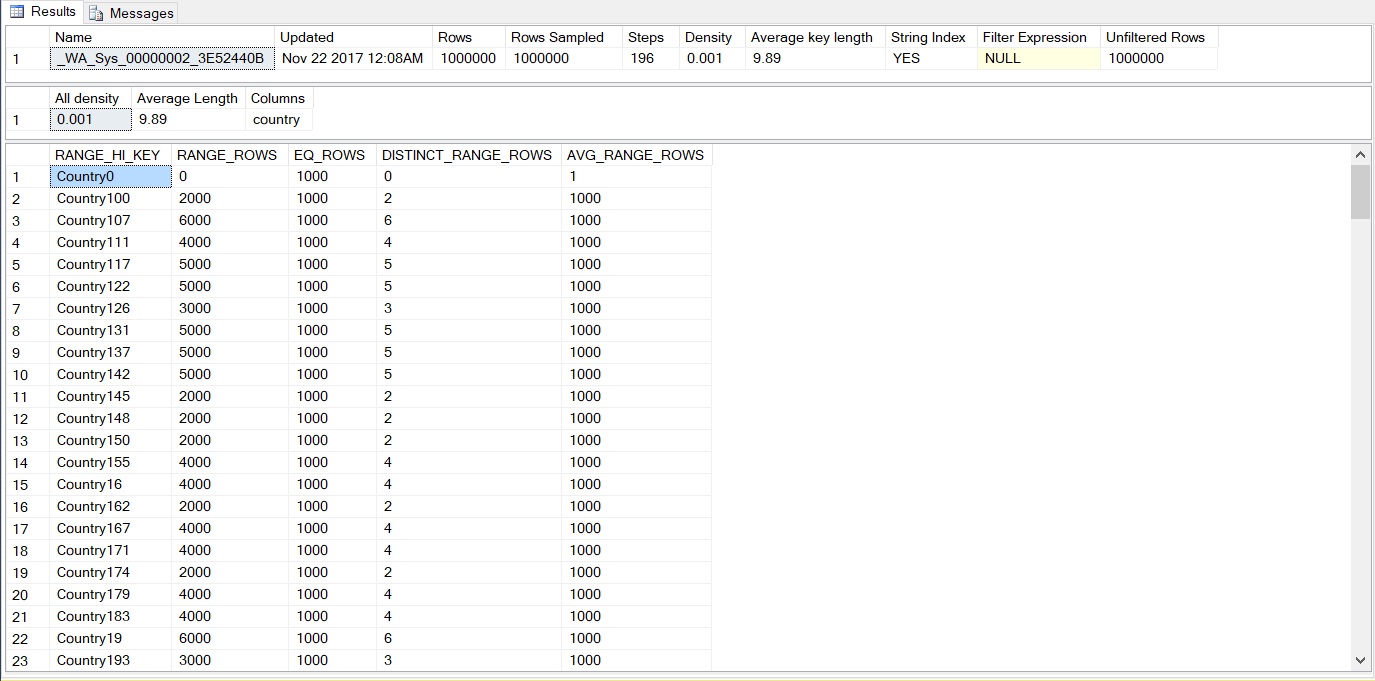
回傳結果分爲三個部分:
- Header -> 包含了統計資料名稱,更新時間,取樣的筆數,直方圖分爲幾個Steps(區間)
- Densities -> 該欄位根據density formula計算出來的密度。密度越低,選擇性(selectivity)越高。
- 直方圖 -> 利用分隔區間顯示該欄位的資料分佈。(最多200個區間)
以我們的例子來説,我們的直方圖被分成了196個區間,每一個區間代表了一個範圍(廢話?
接下來的説明會利用以下這張圖來説明,
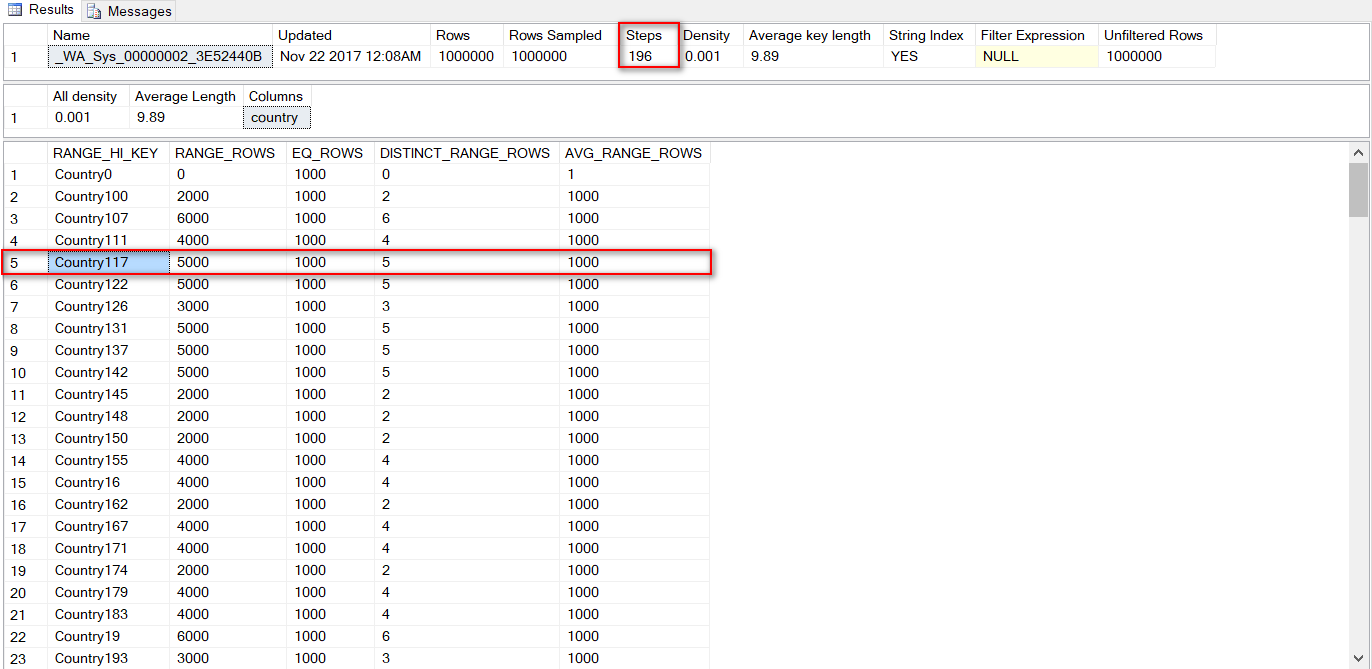
RANGE_HI_KEY => 每個steps的值,紅框内的值為Country117 => 這個row 顯示了 從Country111 +1 到 Country117内所有的資料的分佈。
RANGE_ROWS => 代表從Country111 +1 到 Country117-1 裏面一共有幾筆。
EQ_ROWS => 代表這個區間值等於 Country117的筆數。
DISTINCT_RANGE_ROWS => 代表這個區間裏面有几個特殊/單一(Unique)值。
AVG_RANGE_ROWS => 代表這個區間每個特殊值平均有幾筆。
讓我們繼續看下去,我下了一個簡單的查詢語法(值剛好等於某一個RANGE_HI_KEY)
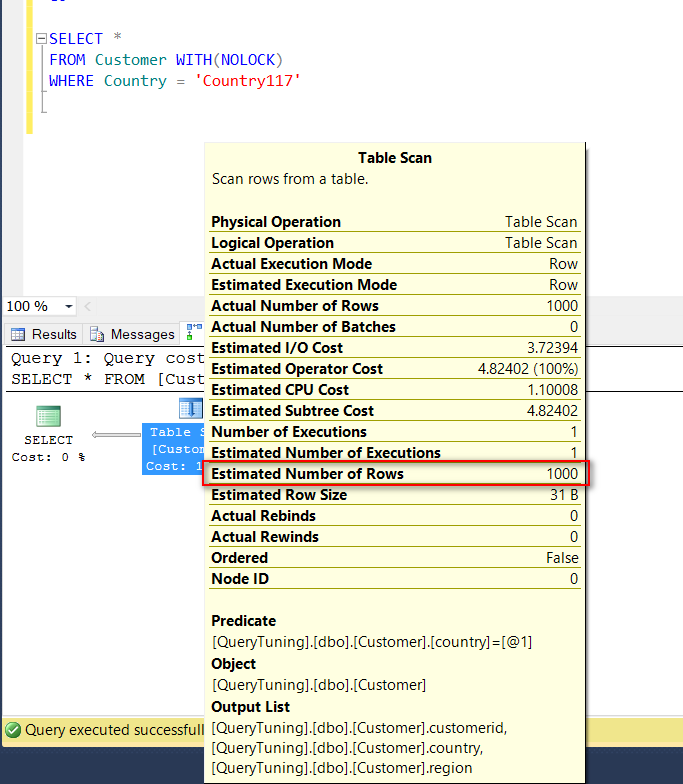
可以看到 這個語法的執行計劃中的TableScan operator的預估回傳筆數剛好等於上上圖Country117對應的1000筆,實際回傳筆數也是1000筆,沒有任何的誤判。
那如果今天where condition的值不在RANGE_HI_KEY上會發生什麽事呢?
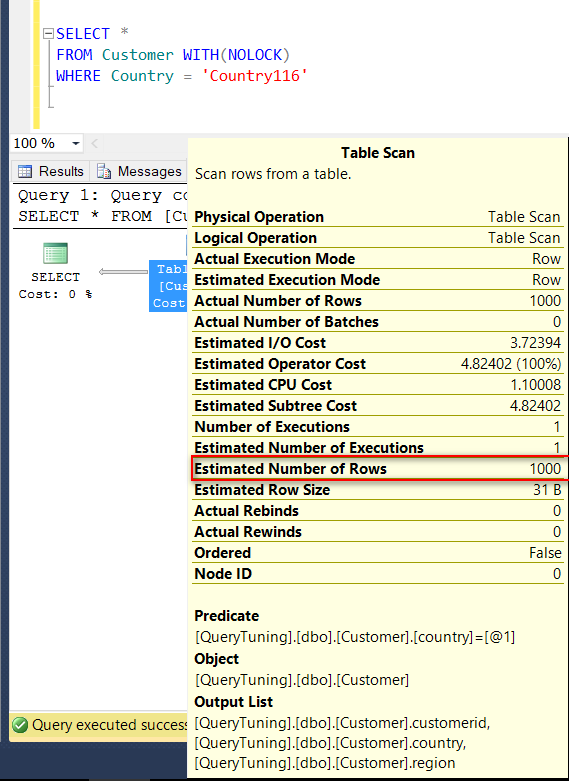
因爲資料表裏的資料被設計過,所以預估回傳和實際回傳筆數跟上一個語法一樣都是1000,
但這個預估的算法為 RANGE_ROWS / DISTINCT_RANGE_ROWS( in this case 5000 / 5 = 1000) => AVG_RANGE_ROWS。
-----
基本的部分就先到這邊,因爲太深奧的我還不懂...如果有什麽錯誤,再麻煩大大門指教~
參考鏈接:: https://www.red-gate.com/simple-talk/sql/performance/sql-server-statistics-basics/