資料多到算不完嗎?沒錢買超高運算效能的電腦嗎?
把多台電腦串起來吧!!
本文以Cloudera的Cloudera Manager作為部署工具,
將Spark部署在4台電腦,並以Python實作平行運算。
當今Big Data的時代,資料多的跟什麼一樣,咱們做資料科學的,常常程式執行下去就是好幾個小時起跳,甚至好幾天一個禮拜都有可能。
那要如何在這樣的狀況下縮短執行時間呢?最直接的方法當然就是砸錢買高效能的機器,但不是大家都這麼有錢嘛~所以集合手邊的電腦來增強運算效能就變成加速的方法之一。
而我之所以會寫這篇文章呢......是因為專案要將別人的程式平行化,所以記下過程,以方便將來自己及有需要的人有跡可循。
- Spark是當今火紅的平行運算框架,其基於記憶體的運算方式比起Hadoop MapReduce速度快上超多。Spark目前支援Python、R、Java、Scala語言。
- Cloudera Manager是Cloudera發行的整合部署工具,使用它可以快速架設環境到你的機器上。
- CDH是Cloudera以Hadoop基礎的商業化(沒錯就是商業化,可是我很窮所以用免費版XD...)發行版,其中包含Spark、Hive等應用。
以下省略一千字
作業系統:Ubuntu 桌面版本 16.04
Python版本:Python 2.7
使用工具: Cloudera Manager、CDH
詳細資訊可以參考Cloudera的官方網站https://www.cloudera.com/documentation/enterprise/5-9-x/topics/cdh_intro.html
前置作業
首先呢準備好你的機器,這裡用的是4台實體機(我用過虛擬機,但資源不夠直接卡死......),4台皆有固定IP(區網IP好像也可以我沒試過)。
這邊注意,各機帳號密碼請務必設定一樣,以方便Cloudera Manager安裝CDH!!!
然後把OS灌成Ubuntu,Windows應該也是可以,不過聽說Windows狀況比較多。
1.在所有主機上安裝SSH並保證可以遠端登入,開啟terminal輸入以下指令安裝SSH。
-
sudo apt-get install ssh
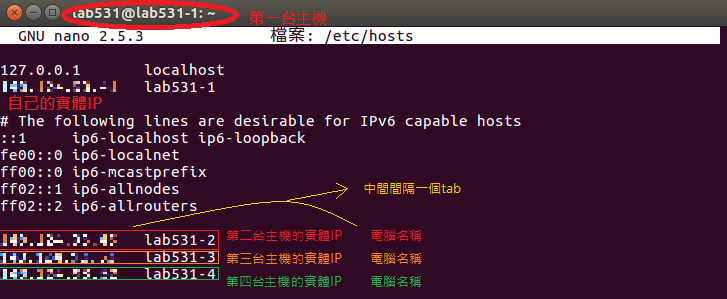
2.在所有主機上修改 /etc/hosts 文件,將自己的主機與其他主機的實體IP和名稱寫進去。
每台主機都要,假設你現在有A、B、C、D四台主機,那麼
在A主機就必須寫上自己的實體IP及其他B、C、D三台主機的實體IP;
在B主機就必須寫上自己的實體IP及其他A、C、D三台主機的實體IP;
在C主機就必須寫上自己的實體IP及其他A、B、D三台主機的實體IP;
在D主機就必須寫上自己的實體IP及其他A、B、C三台主機的實體IP;
以第一台主機為例:
3.在所有主機上開啟terminal輸入以下指令以設定root帳密
-
sudo passwd root
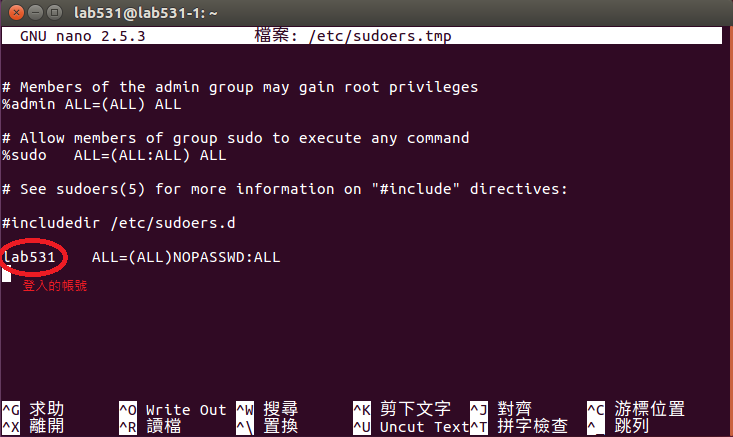
4.在所有主機上開啟terminal輸入以下指令以設定設定權限
-
sudo visudo
在最後一行加入 [帳號] ALL=(ALL)NOPASSWD:ALL
5.在所有主機上開啟terminal輸入以下指令以安裝JDK
因為Cloudera出的工具不會幫你在所有主機上安裝JDK所以必須自己手動安裝(Cloudera Manager只會安裝JDK在第一台主機上)
這邊我是安裝Oracle的JDK
-
sudo add-apt-repository ppa:webupd8team/java
-
sudo apt-get update
-
sudo apt-get install oracle-java8-installer
oracle-java8-installer為Oracle JDK 8,有其他需求者請自行更改~
然後就是同意一些協議......然後就開始安裝啦~~
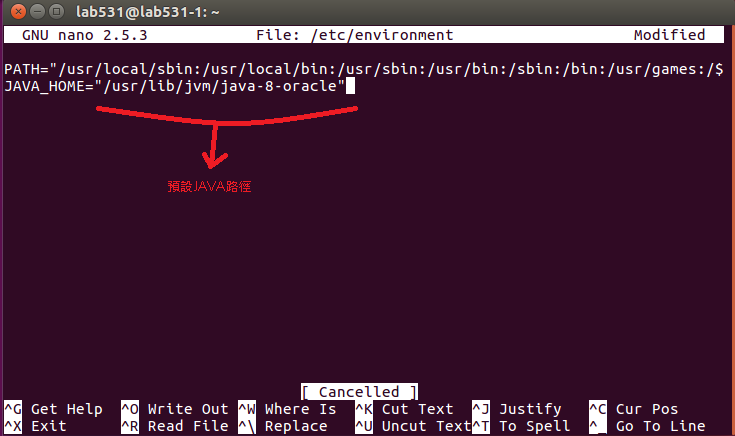
6.在所有主機上修改 /etc/environment 文件,以設定環境變數
每台主機都要,加上JAVA_HOME環境變數
預設為 /usr/lib/jvm/java-8-oracle
改完後,因為要讓環境變數生效,請將所有主機重新啟動
1.下載安裝Cloudera Manager
(說是第一台啦,阿你隨便挑一台就好XD)
在第一台主機開啟terminal輸入以下指令以下載檔案
-
wget https://archive.cloudera.com/cm5/installer/5.15.0/cloudera-manager-installer.bin
5.15.0 是版本號
在第一台主機開啟terminal輸入以下指令以修改權限
-
chmod u+x cloudera-manager-installer.bin
在第一台主機開啟terminal輸入以下指令以開始安裝
-
sudo ./cloudera-manager-installer.bin
接下來呢就是一路"下一步"
最後開啟你的browser,連上預設網址localhost:7180就可以進入登入畫面囉~
這邊帳號密碼預設都是admin
2.用Cloudera Manager部署安裝CDH
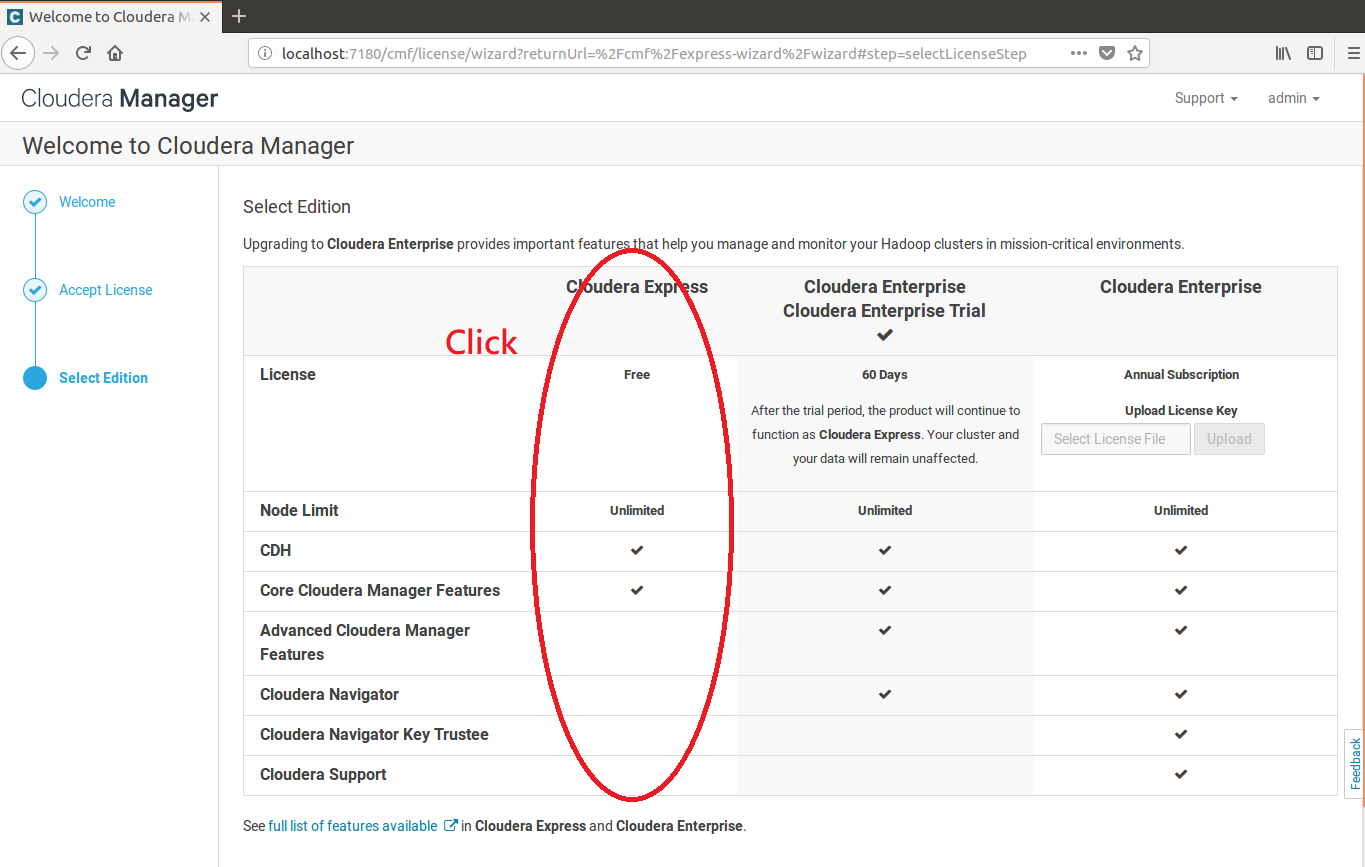
1.登入後就是一路"下一步",但是到Select Edition頁的時候......
選擇版本,這邊我就選擇免費版的Cloudera Express
然後繼續"下一步"......
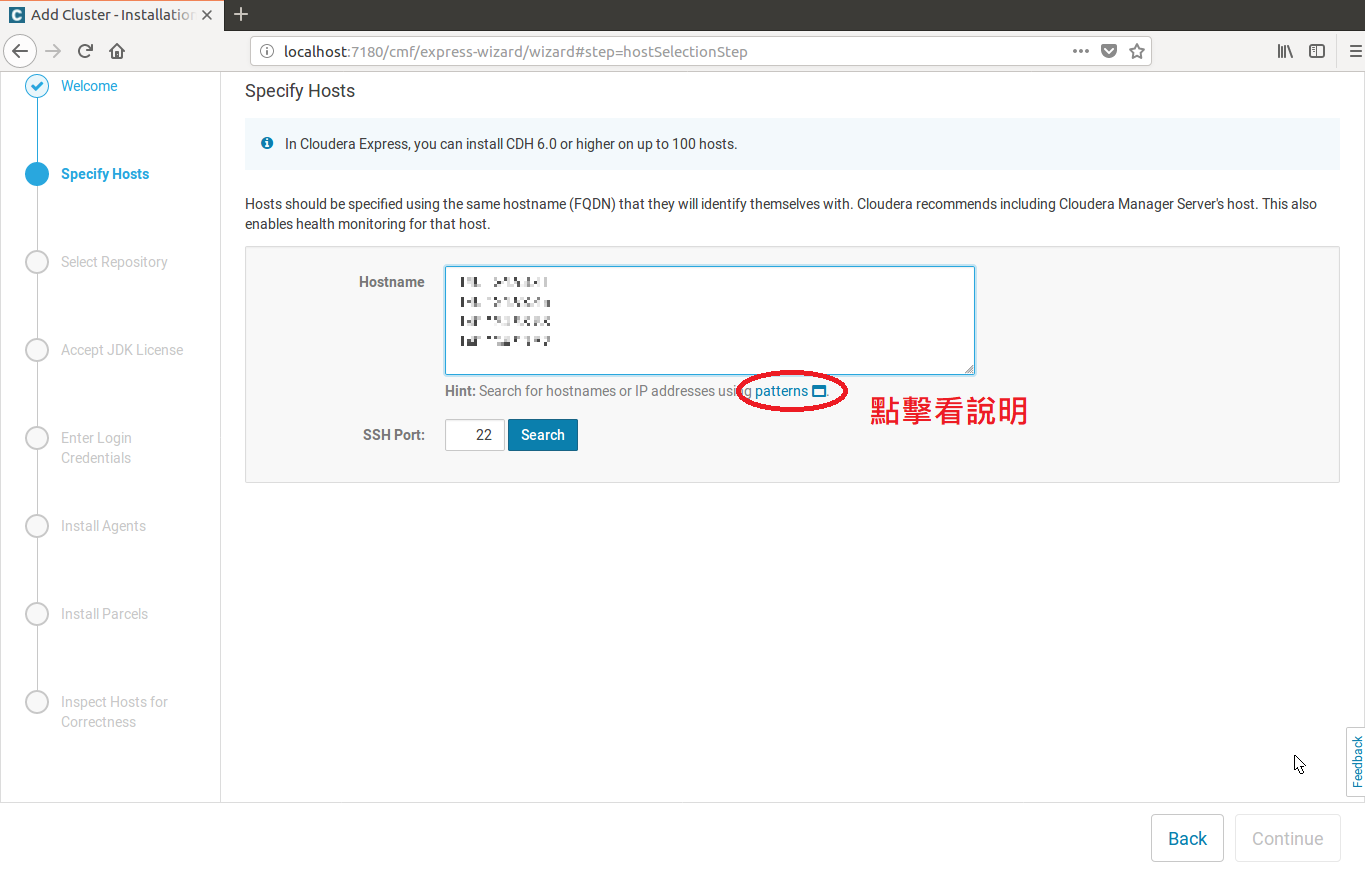
2.到了Specify Hosts頁面的時候得輸入你所以機器的IP
這邊可以用patterns的方式去輸入,但我這邊只有四台所以就直接輸入
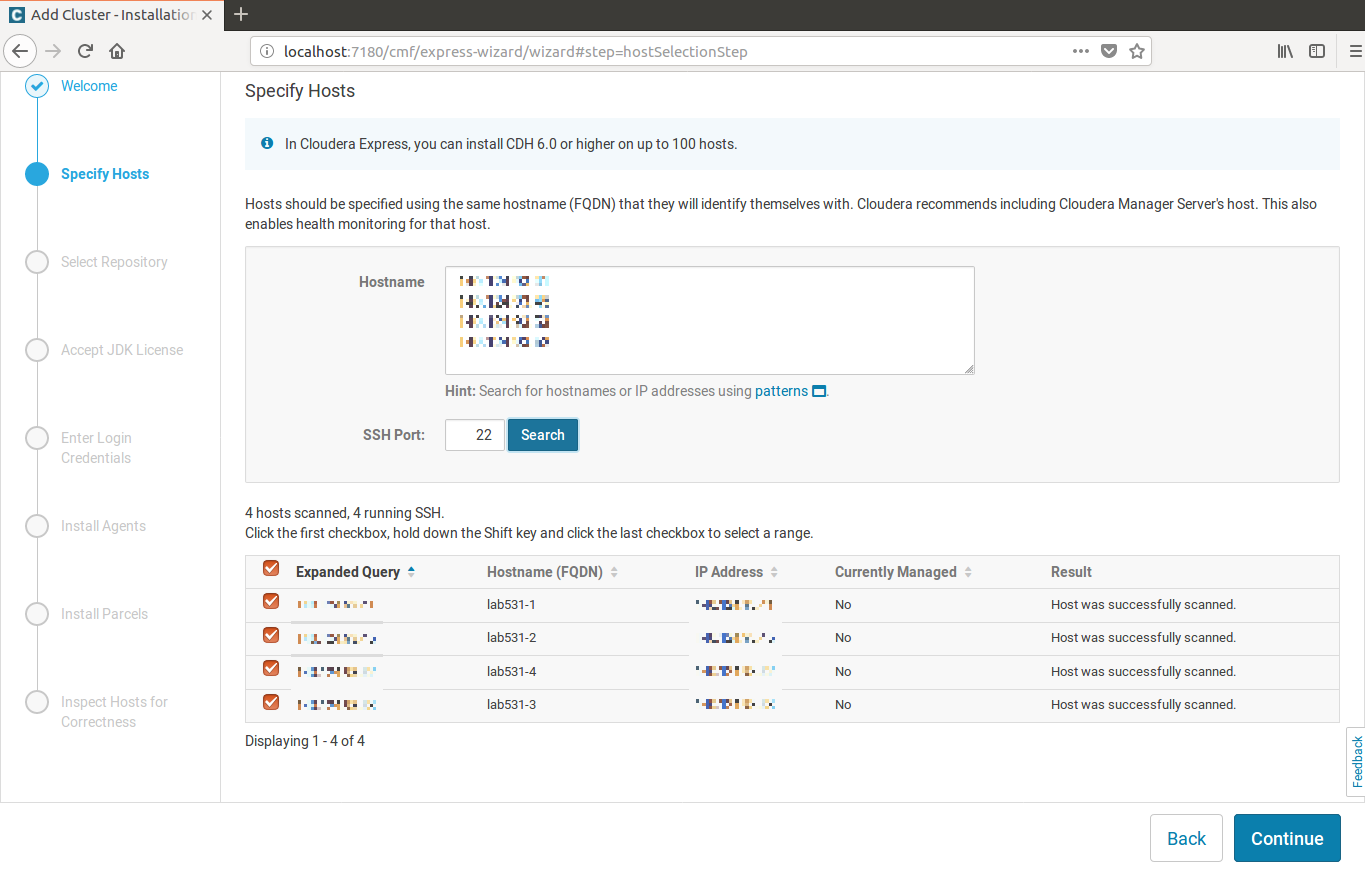
 按search可以找到所有主機,選取所有主機並繼續下一步......
按search可以找到所有主機,選取所有主機並繼續下一步......
3.到了Accept JDK License頁的時候,不要勾選安裝JDK
不要勾選安裝JDK
不要勾選安裝JDK
不要勾選安裝JDK
因為這個只會安裝在第一台,而且我們已經在所有主機手動安裝過JDK了
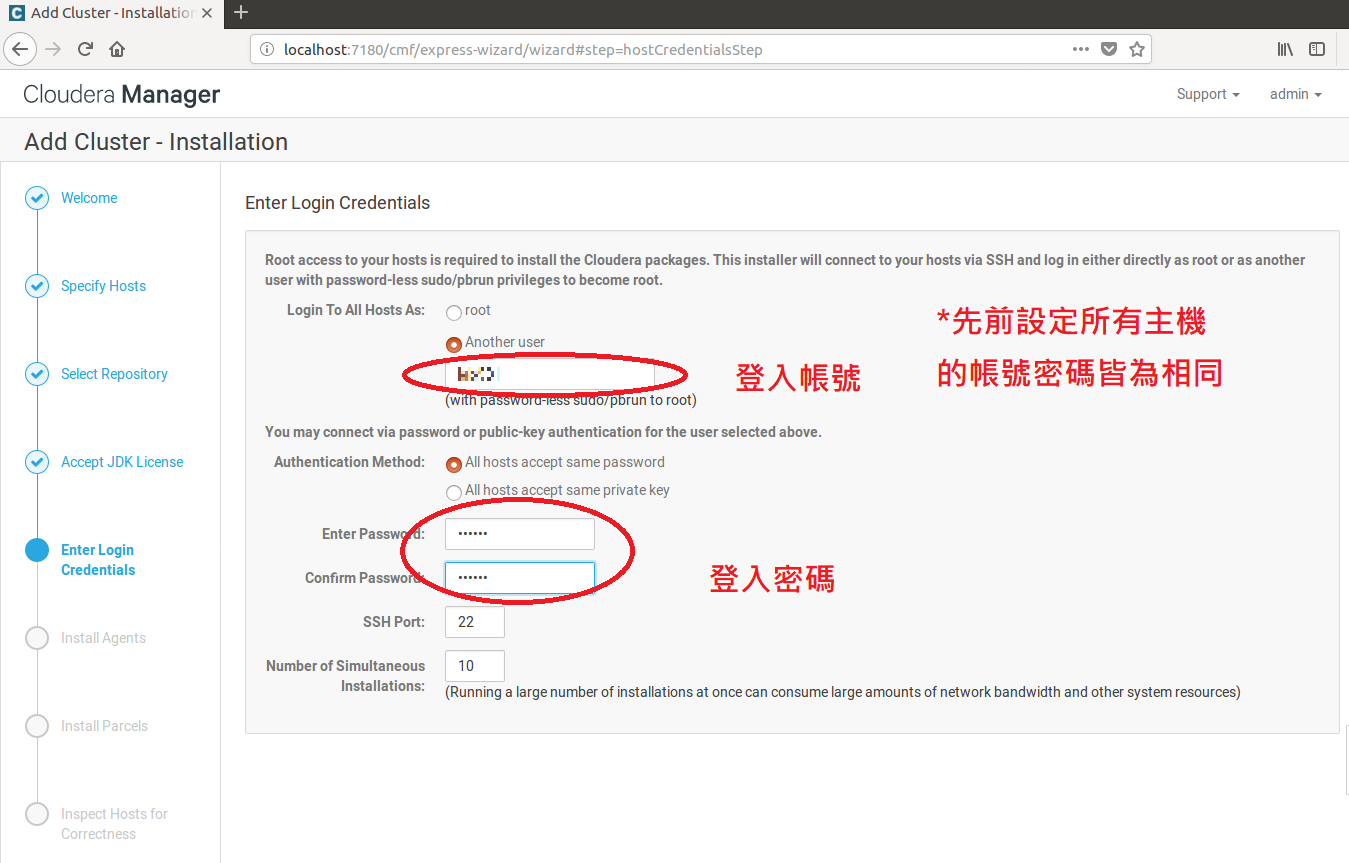
4.到了Enter Login Credentials頁的時候......
輸入用於登入各主機的帳號密碼,然後繼續
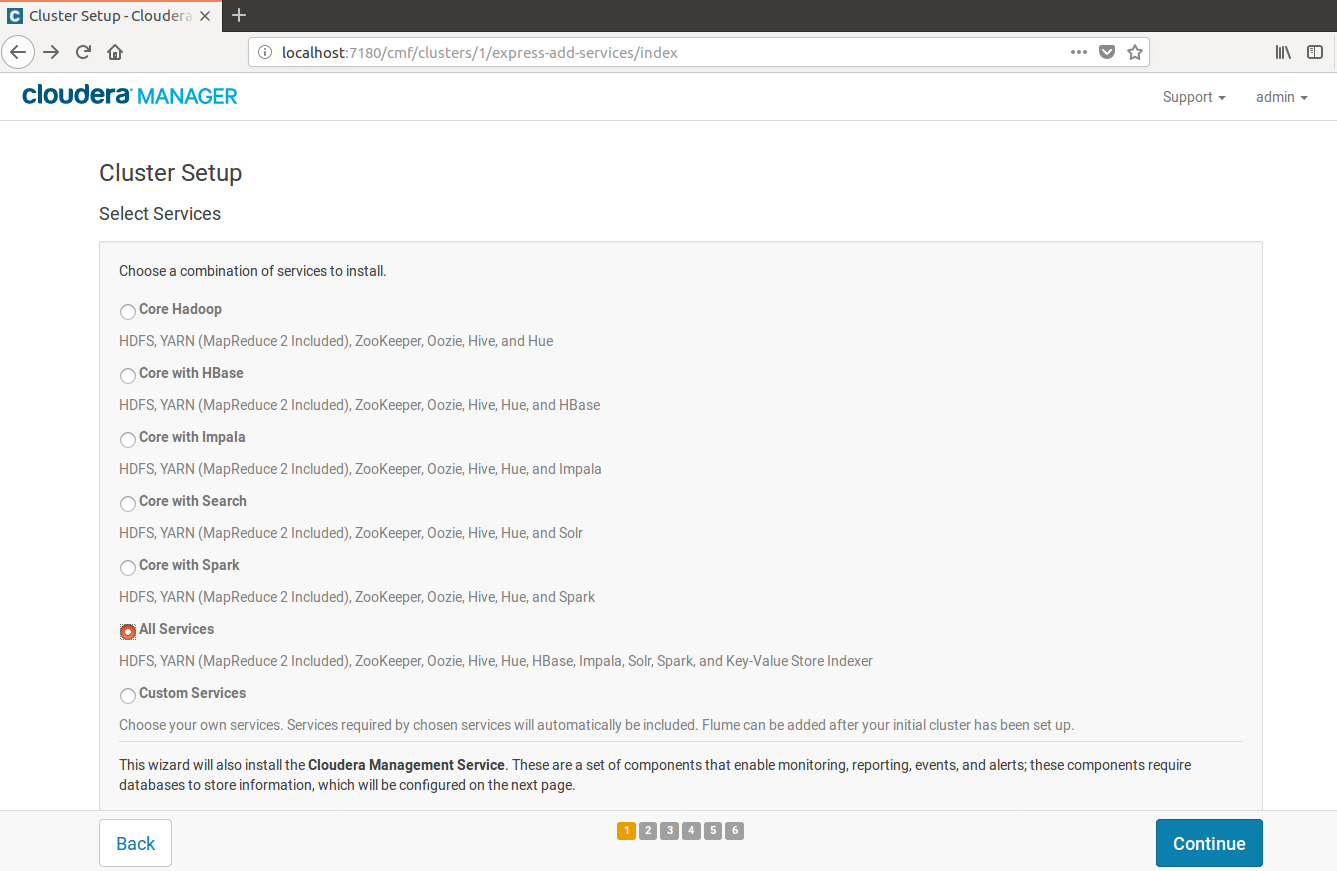
4.安裝服務
到Cluster Setup Select Service頁的時候,選擇你要的服務
這邊我選ALL Service,然後繼續
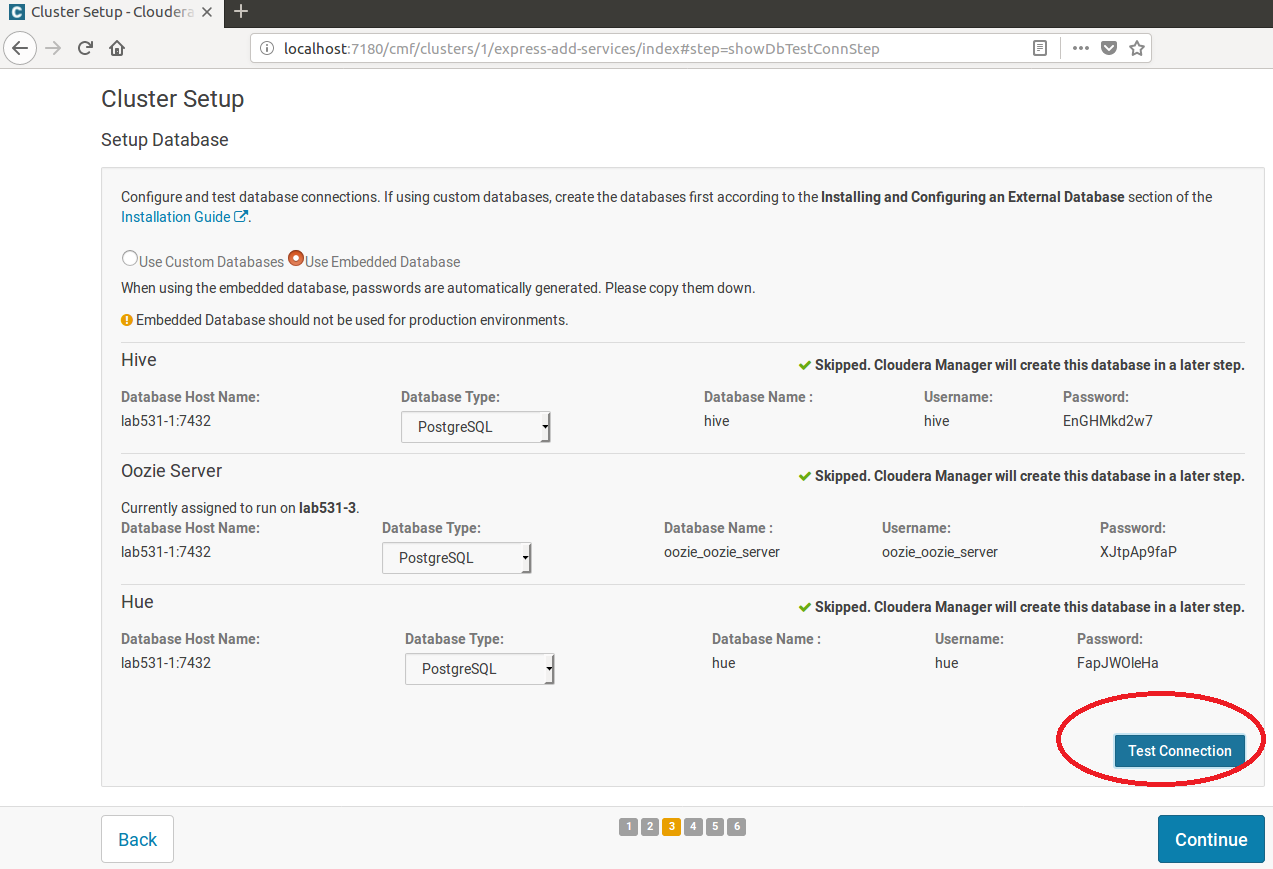
5.安裝Database
到Cluster Setup Setup Database頁的時候,要先按測試連線才能繼續......
 然後一直繼續......就完成了
然後一直繼續......就完成了
整個安裝過程只有前置作業比較眉角比較多
後續用Cloudera的工具安裝時,大部分都是按"繼續"即可~
3.第一支Spark程式
使用HUE執行python程式
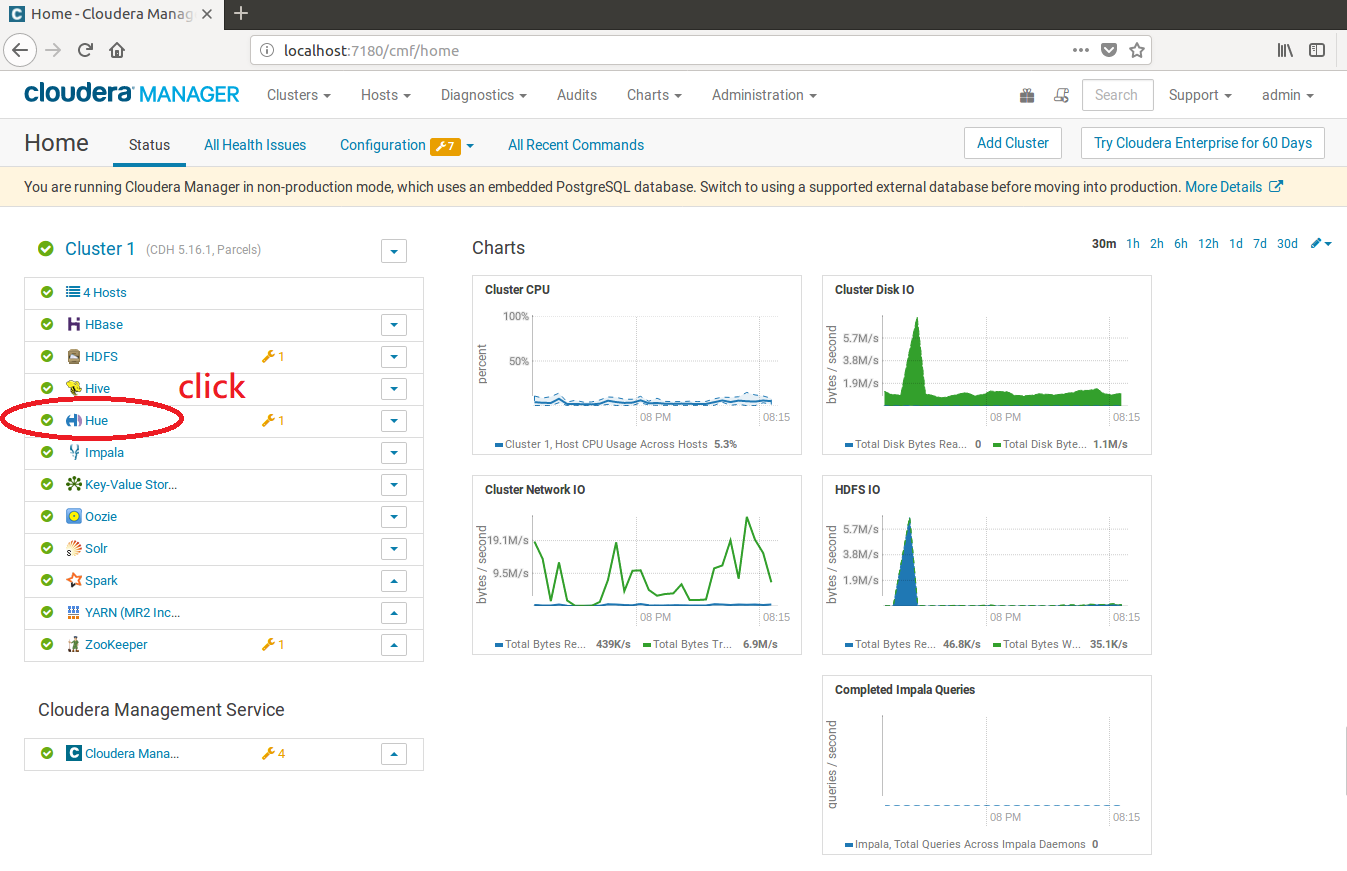
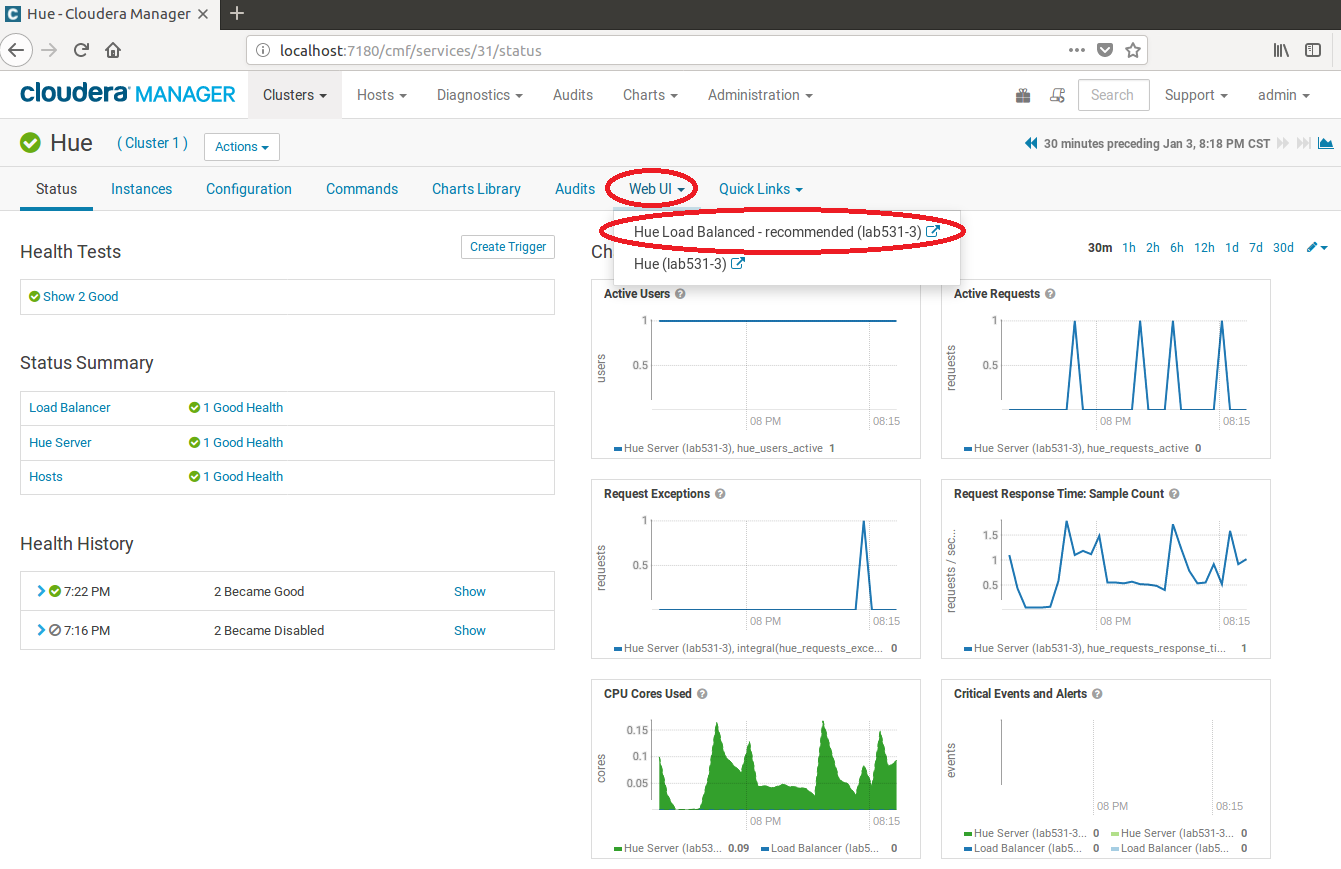
然後點擊Web UI下拉選單,點擊Hue Load Balanced-recommended
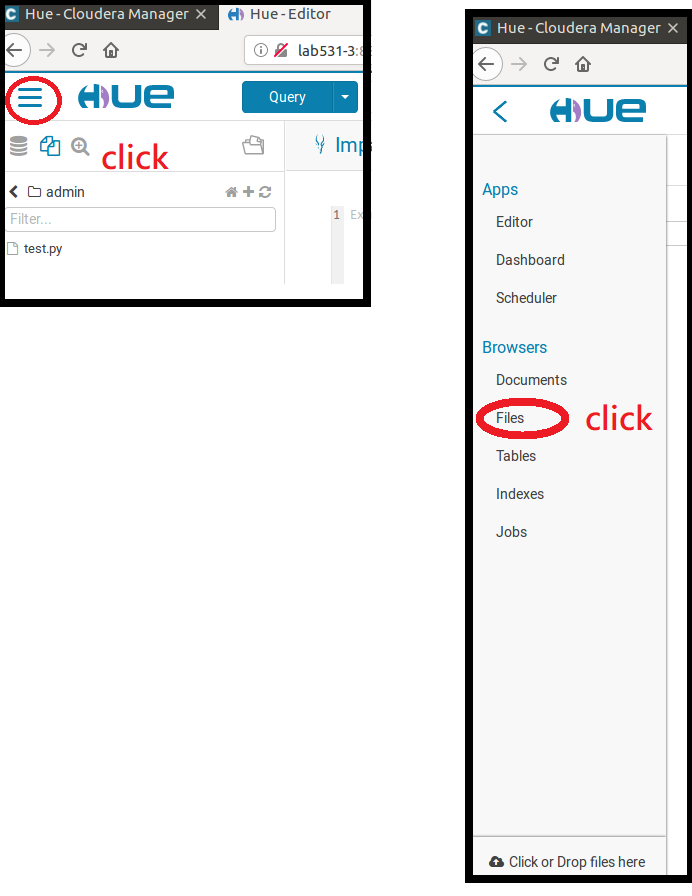
典擊左上角的按鈕打開選單,然後點擊Files
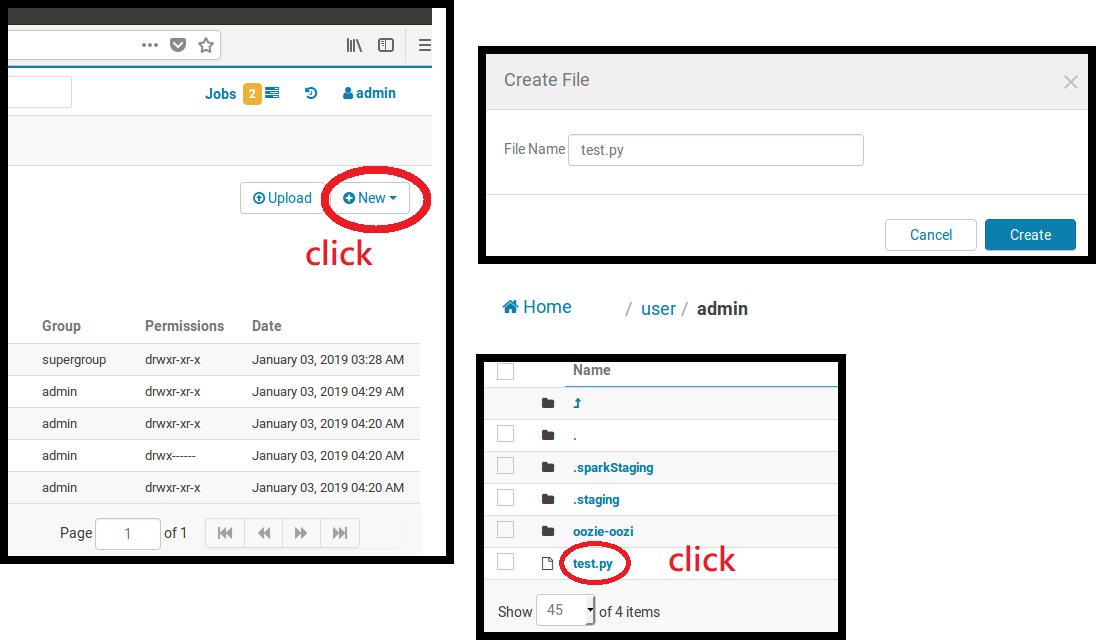
新增檔案,取名為test.py,並點擊該檔案
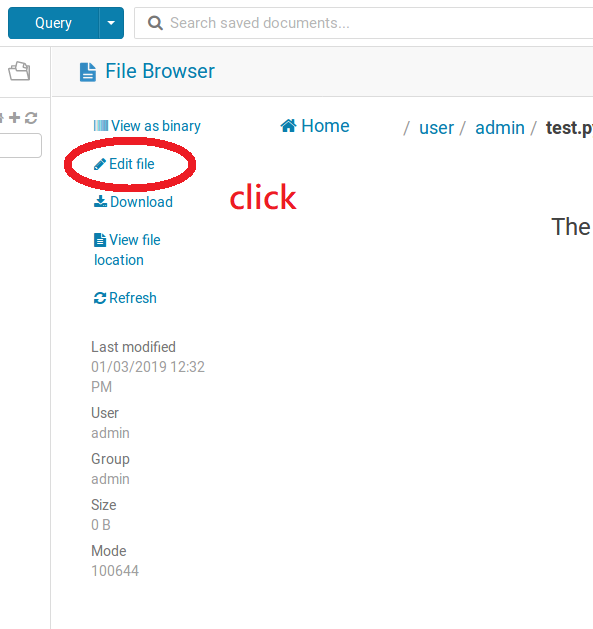
點擊Edit file可以邊擊檔案,然後就可以寫你的python code了
 這邊寫一個簡單的範例
這邊寫一個簡單的範例
-
from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf() sc = SparkContext(conf=conf) intRDD = sc.parallelize([3,1,2,5,5]) tmp = intRDD.map(lambda x:x+1).collect() print (tmp) sc.stop()
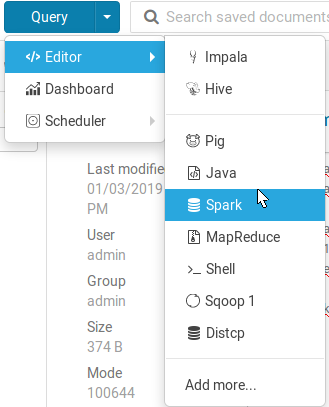
然後點擊Query>Editor>Spark
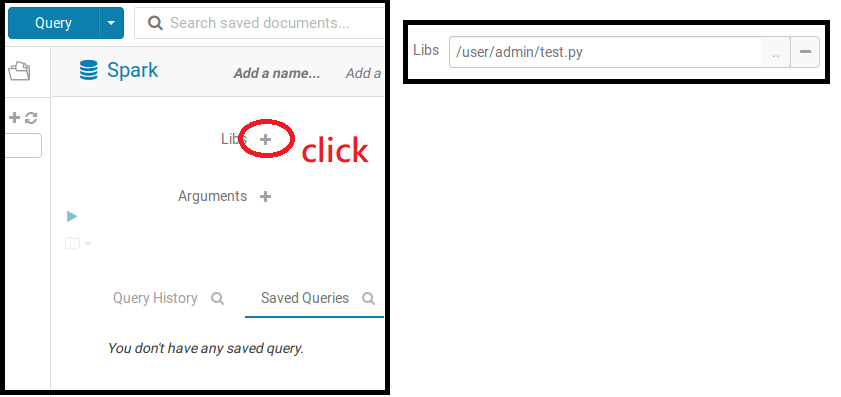
點擊Libs旁邊的加號,並選擇你的.py檔案路徑
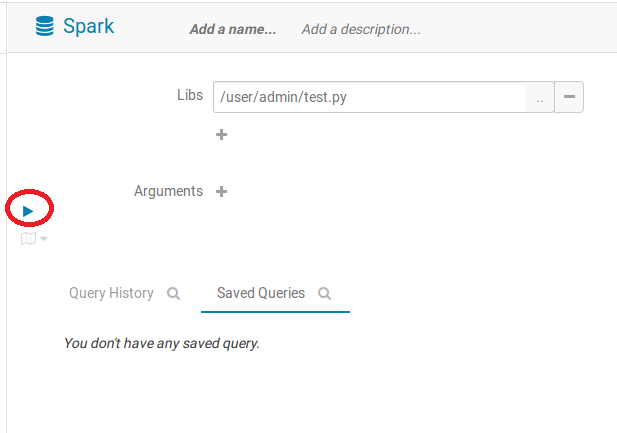
點擊藍色三角形就可以執行啦~
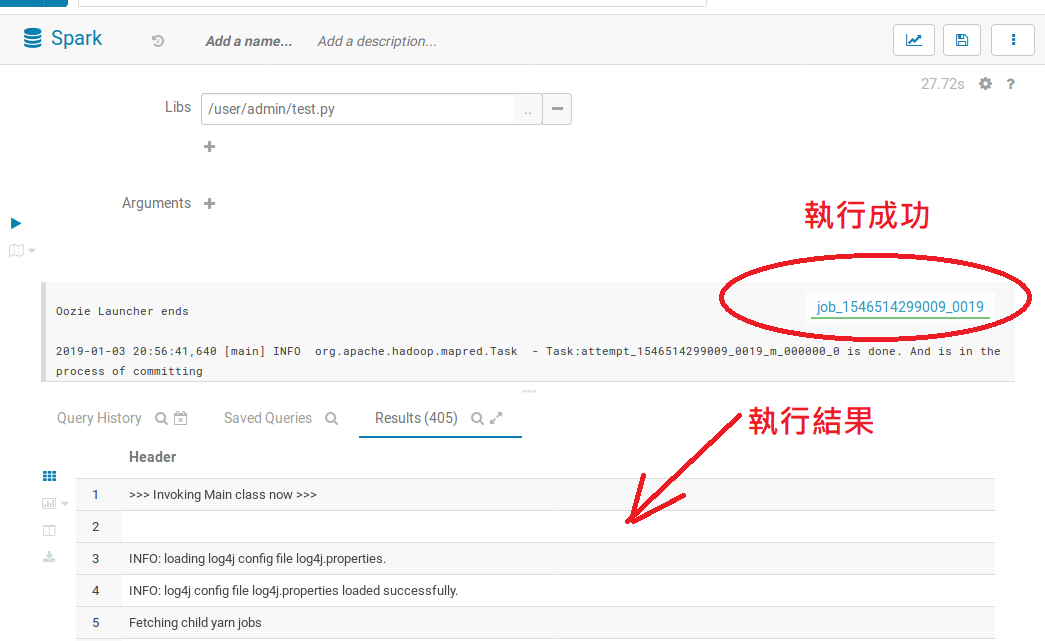
執行成果會是綠色的,結果則會顯示在以下的log中
除了HUE還提供排成的方式執行你的程式