你知道嗎?其實機器學習早已歷經了二次冰河時期,資深一點的教授可能對它是恨多過於愛。誰知幸運的輪盤竟然逆轉,讓我們見證到給電腦資料,它就能學會一個或多個模型來解決問題的光輝時代。我們把鏡頭拉到身邊,二十年前用Win NT寫的程式,隨著時間已經不能用了。而今iPhone內建的AI仿生晶片,可以讓你微光中拍出好照片…很多人都擔AI會搶走我們的工作,希望它能像千囍年的電子商務先泡沫一波,再改善我們的生活。究竟AI是一場恐佈片?還是勵志片?就讓我們繼續看下去…
一、前言:
大家都很關心 AI的發展的近況,個人的觀察 AI 從許多獨角獸的異軍突起,到首間破產的AI公司,再到學術業的大爆發(截自2019年底AI論文每天可達 300篇的高峰,這個驚人的發表數字真的很火熱),這個上升、下降、又上升的趨勢像極了股市的頭部趨勢。再加上GPU與矩陣運算晶片的硬體技術成熟,讓AI由學術界的白熱化進入產業的普及化,不曉得你打算繼續觀望?還是你打算捲起袖子,開始寫出你人生中的第一個神經網路?
接續前幾篇介紹的一些 Machine Learning的技術(Microsoft AI Overview、SQL Server的演算法、微軟AI圖形化的開發工具…),接下來我們要繼續往深度學習來推進,甚至是移花接木的遷移式學習或是人臉辨識的應用,本文將會帶領大家來初探類神經網路(ANN/DNN待會會解釋這個名詞的定義)這個演算法。
類神經網路(如上圖)當初就是模仿人類的神經網路的架構來設計的,所以會有神經元、傳導層級(可以有淺層或深層)、閾值(決定是否要激活)。其次是發展至今除了能處理數值型的廻歸與類別型的分類問題,又不斷發展了擅長處理影像的捲積神經網路(CNN)、處理時序的遞延神經網路(RNN)、創造內容的生成對抗神經網路(GAN)…等家族。
二、目標:
本文將會示範,極簡版(六行就可以寫完)以及進階版(更大彈性的API函式可用在多種用途的應用上),來帶大家入門。
三、定義:
早在GPU不普及的15年前左右,要跑個二層都已經要花上1~3天的時間代價。在當時,三層就已經算是深層神經網路 Deep nerual network(簡稱 DNN)了;但是現在有了GPU,再加上微軟貢獻的 Residual function殘餘函式,讓神經網路卡關在二十幾層無法再更深層的問題得以突破,甚至在學術上或是在火力展示時是可以跑到上千層,但實務上受限於邊際效應(投入了更多的資源但卻是得到遞減產量的結果),大家在考量時間與GPU成本後還是只會選擇五十層或是一百五十層這個範圍的模型深度。
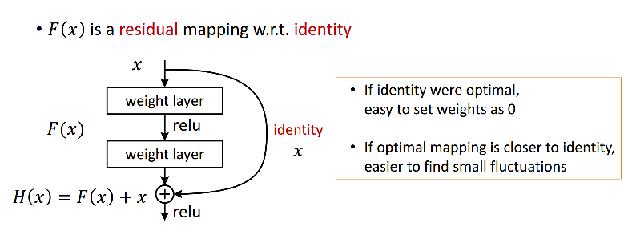
在上圖中的 Residual function可以有效解決梯度消失或是梯度爆炸的問題,眾所皆知機器學習就是透過 Gradient descenct 不需要把所有的可能都算過,就能應用數學梯度(斜率)在踏出每一步的學習(下面會再談到 Learning rate)時,快速地修正方向儘快地逼近最佳解(最小錯誤率)。但是隨著神經網路要解決更複雜的問題,模型愈來愈深與更大型的架構就會遇到矩陣相乘太多的負作用,假設有一個五層的NN,而且每層的權重都是 0.3,所以經過5次的相乘就後,數字已經小到 0.00243,你就會發現原始 0.3 的權重,傳到五層後,已經完全沒有作用了,我們稱之為「梯度消失」。反之亦然,當數字大於1,連續相乘也有被放大為巨值的風險,我們稱之為「梯度爆炸」。總之,透過新的方法,可以把連續相乘變成類似連續相加的結果,讓梯度可以有效地傳遞,進而實現更深的模型。
與非深度學習的傳統演算法相比:
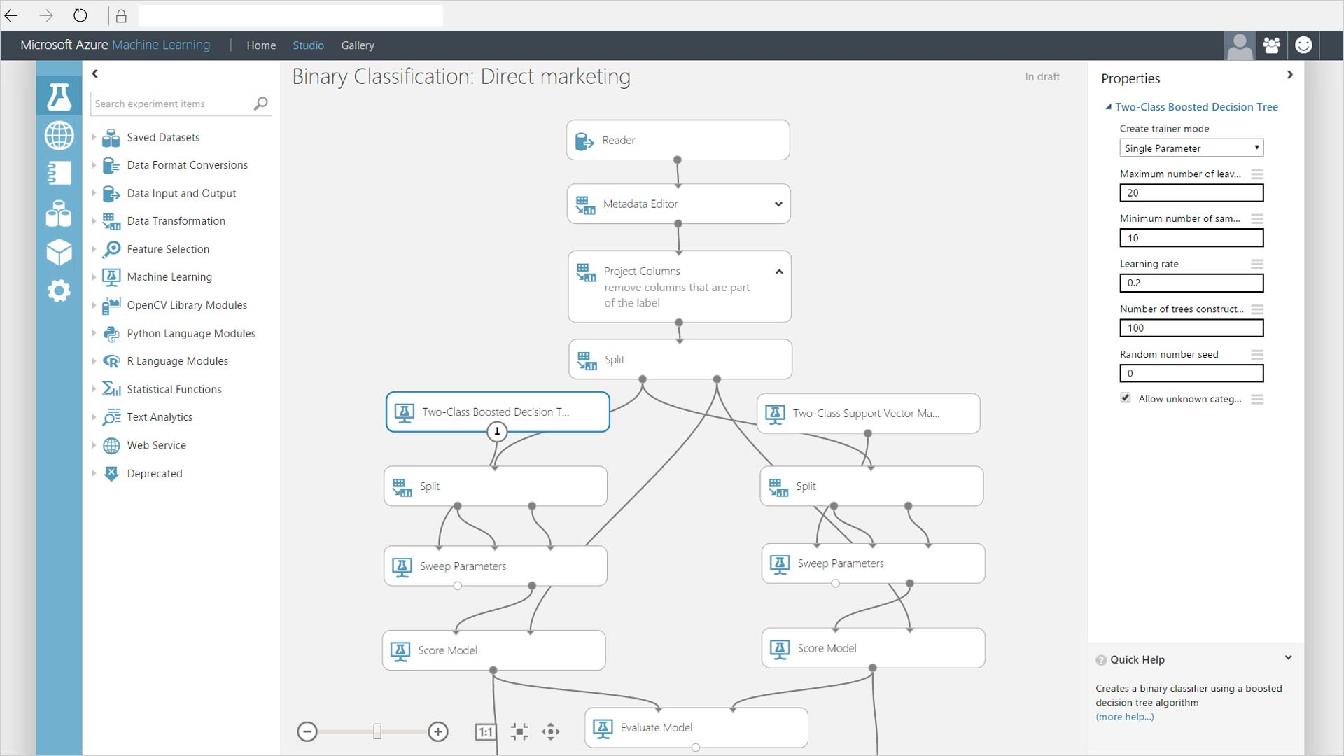
比起傳統或是經典的演算法,它少了許多特徵工程的工作(以下圖的GUI來看,工作流程會比較少),直接把欄位轉成數字,連同答案一起丟進ANN模型中,它就自己會學習了,所以它還是歸屬於監督式學習的分支。但是相對地,它也帶來了較高運算成本(時間與GPU的成本)的負作用,例如浮點數的矩陣運算、以萬計(百萬參數是NN的常態)起跳的複雜參數、不易解釋(雖然像 Grad-CAM 可以用來解釋 NN家族中的某些演算法,但並非全面)…
四、類神經網路的應用:
- 我們先從它的輸入/輸出來看:輸入很簡單,就是矩陣。對電腦來說不過就是型別轉換,增加維度的動作,還算簡單。至於輸出:它可以輸出成數值、分類、方程式…這三種。
- 舉例來說,想預測明天股票是上漲還是下跌(分類)或是指數多少(數值),這個問題(雖然人類是問一個問題,但對電腦是二個問題)。或者當你去參加一個活動時,會從手機中上傳一張或多張照片至社群網路上,此時會需要自動判斷裡面有哪幾個你的朋友(分類)?並且標記出他們的位置(數值)。讓你可以不需一個一個的輸入選取與操作,然後就能直接被辨識出來並且 Tag他。
若是你在2~3年前就曾經有接觸過AI,當時的運算力與開發平台只能支援單一問題的處理能力,他們會跟你說,請你準備一個好的問題來做AI。但即使是現在,問一個好的問題還很重要,我指的是資料要乾淨,資料量不夠或是不平衡(用萬分之一資料去訓練分類模型)的問題,已經有新的方法(例如遷移式學習、imblance data處理手法)來克服。 - 相信前二個輸出值比較好理解,但最後一個方程式輸出,又不能吃,又不能幫我計算所得稅,它究竟有什麼用?不要小看它,它可是要實現人類遠大的夢想的絕妙神器,例如小至漫畫人物的肖像或造型的創造、雙十一的 DM創造,大至自駕車、自駕太空船…都可以透過增強化學習來實現
- 想要AI 更加普及就會需要能佈署到更小的 Mobile裝置上,目前正由軟體與硬體二個面向,方興未艾如火如荼地在發展。例如 MobileNet、Knowledge distillation(用大模型來訓練小模型的一種遷移式學習)、GPU vs. FPGA vs. ASIC...
五、類神經網路內部機制:
A. 以神經網路的架構來說,它一定會有輸入層與輸出層,就像坐高鐵會有南港站起點,左營站終點一樣,你的問題才有一個脈絡與方向。在每一層中,會有N個神經元,在相同一層的神經元會有權重的交享,而不同層的神經元會有交互式的相鄰溝通。至於方向性,它一開始會從 input 開始往右邊學習,到底之後它會反方向由右往左再學回來。這叫做 back propagation,它能有效地解決了模型一但加深會造成中間層權重更新不易的問題。就像我們小時候學習英文一樣,如果你能一邊聽英文一邊開口複誦英文,效果絕對會比只聽英文來的好。
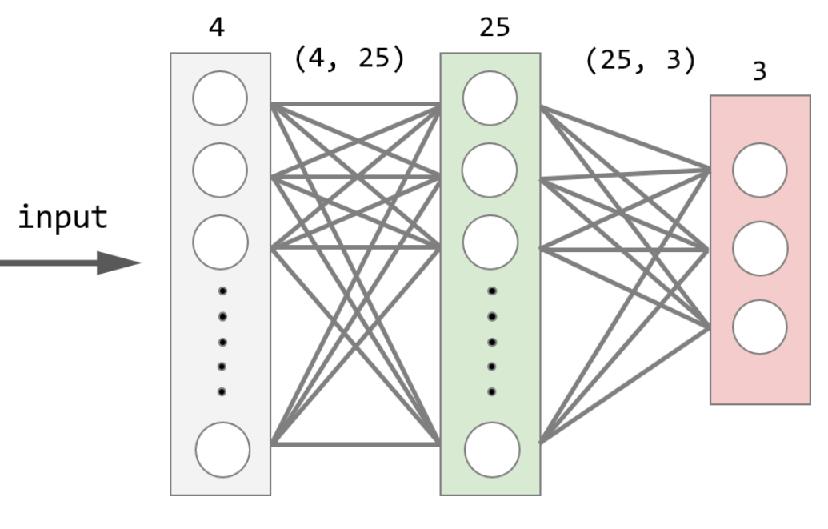
B. 激活函式 Activation function(又稱為最佳化函式),它是掌管每個神經元是否要將特徵值的閾值,有的是較小範圍 0~1;也有的是較大範圍 -1~1;有線性(直直的一條斜線);也有非線性(各種斜率不同的S曲線)可以用來解決不同的廻歸、分類、機率分佈的呈現…等問題。參數包含了Sigmoid(0~1但結果大多二極化,不是0就是1,適合二分法)、Tanh(-1~1)、Relu( Rectified Linear Units 0~無限大)、Softmax(0~1而且機率總合=1,適合多目標[二類以上]的分類)、、
至於為何會需要閾值決定要不要讓某個特徵通過,舉個白話一些的例子,有一隻小狗用牠的牙齒在跟你玩,牠並沒有咬痛你,你的神經會跟你說 還不會痛(未達閾值)可以繼續玩下去。但是,萬一牠咬得很大力達到了閾值,你的神經會告訴你,需適時地收回你的手,保護自己的。所以這個函式在 ANN/DNN中是扮演著極為關鍵成敗的意義,而且在不同的位置,可能會有不同的考量。
為何很關鍵呢?如果一個企業是下達成本第一 Cost down的信念,在每個岡位,從行銷決定市場定位、採購下單、警衛放行入倉、製造…等環節,大家都很認真地在執行,總經理在一個季度後發現大家雖然很努力但賺的卻不多,他可能會要求大家有更好的產出,但終究只是窮忙一場。如果一個企業是擁抱著「在精不在多」的工藝精神,在每個岡位,則會提出如何做的更精緻更到位的作法,在一個季度後,總經理可能會因為大家不錯的產能,先是提撥盈餘發放員工福利之後,接著會也要求大家能有更好的產出。結果行銷部門評估了全球市場,員工將有更多地機會去競足更高單價的市場或是更大的世界舞台,在過程中你的眼界、能力得到更大的提升,即使離開這家公司。上下游以及同業都搶著邀請你去工作。
以分類問題為例,假設我要輸出明天的股市是上漲?還是下跌?在最後的 output 這一層我需要放置一個神經元,並且設定softmax或是其他函式,將上一層所傳入的數值,可以轉換成可以協助人類決策的資訊。以下圖為例,最小值為0.1最大值為2.6的四個數值,如果你能給總經理0~100%的機率,他可能不需要問你 0.1/2.6分別代表什麼意義,就能做出決策。看了以上例子,是不是覺得激活函式很重要呢?但是事情沒這麼簡單,Mind set對了只是有一個好的出發點,神經網路要運行的好,還有其他細節要考慮…

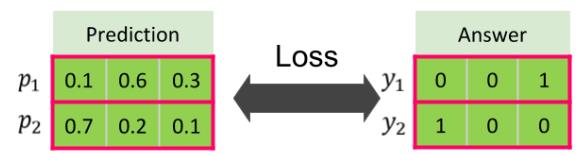
C. 損失函式 Loss function,(如下圖)它的目的是要讓輸出層與答案愈接近愈好,所以你必需很清楚你要解決的問題類型來做選擇。舉一些常見的,在廻歸問題,我們會選擇 mean_squared_error(簡稱為 mse);如果是分類問題,二擇一的問題,我們會選擇 binary_crossentropy,若是多擇一,我們會選擇 categorical_crossentropy。至於其他的參數像是 logcosh、kullback_leibler_divergence、poisson、cosine_proximity就留給大家去探索了
D. 優化器 Optimizer 用來調整模型對抗雜訊的能力,或是可以想像你在騎腳踏車打算要來翻越高高低低的山谷,然後你會需要配備變速裝置,讓你可以省力地在上坡與下坡之間從容以對(對付學習率的問題上)。參數包含了SGD(Stochastic Gradient Descent又稱為 Mini batch是這個參數的預設值)、AdaGrad、RSMprop、Adam,其中後面二個方法能夠參考前面的學習來修改後面的 Learning rate,以達到類似取 Log的效果,讓你的等高線由橢圓型變成較集中的同心圓,換句話說,能幫你把越野賽變成室內賽。
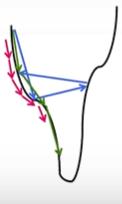
至於 Learning rate就是前面所提到要執行 Gradient descenct(我簡稱為GD)的相輔相成動作,以登山來說,假設我要去嘉明湖。當我從登山口出發,會有許多岔路 GD類似我的地圖,epoches 就是我打算要走過 N回合的母計劃。在下圖中,分別是三種去抵達嘉明湖的策略,紅色是小步走;藍色是大步走;綠色是適中走。紅色是單一回合已經走完了,但是卻離目標還有一段距離(錯誤率太高,是不好的模型訓練結果);藍色是太大步,然後在二岸中間一直彈來彈去,活像是剎不住車的蜘蛛人,白做工;唯有中庸之道的綠色,但這個值存在理想的國度。
在每個子計劃中,一般來說應該是「愈前面愈大步,愈後面愈小步」、「地形愈平緩愈大步,愈陡峭愈小步」才合理。而近期的優化器在設計時,就已經實現了這個精神,只是愈後面的方法愈能記住前面的步伐做更動態的調整,感覺優化器本身也像是一個演算法模組。所以目前我會推薦 RSMprop、Adam,但將來可能還會有更好的作法…
F. 評估模型 Metrics 用來評估模型成效的方法,參數的預設值是Accuracy,另外你也視問題來選擇 binary_accuracy、categorical_accuracy、sparse_categorical_accuracy、top_k_categorical_accracy來評估你的模型。
[非必要] 至於 Evaluate也是評估,但它是整體評估。在神經網路的的訓練中,我通常會在 Fit 這個訓練指令中,設定 Verbose = True,它就會比較細節地印出 Training 與 Validation的過程,好讓我可以判斷是否有 under fitting/ over fitting的不好現象?
G. 回呼函式 Callbacks 在訓練的過程中有許多岔路,例如 Log file 留下所需的訓練記錄;EarlyStopping 可以做到,在發現苗頭不對就馬上停下來,以免浪費運算資源與時間;CheckPoint 在多回合的 epoches中留下最好的一個模型;TensorBoard 應用GUI的介面來檢視模型的設計、參數、資料流、成效…
六、類神經網路簡易型實作:透過下面的程式,前面先載入套件與資料,然後用主要的六行來完成模型的建模,最後再用一行來預測。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
…
model = keras.Sequential()
model.add(layers.Dense(30, activation='relu',input_shape=(30,)))
model.add(layers.Dense(3, activation='sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.SGD(learning_rate=0.1),
metrics=['acc'])
model_history = model.fit(x=x_train, y=y_train,
batch_size=32,
epochs=50,
validation_data=(x_valid, y_valid),
shuffle=True)
y_pred = model.predict(x_test)這六行就是DNN的精髓:
- 請先在…的下方找到 keras.Sequential() 這一行,它的意思是讓系統先載入Sequential 這個模型,有了它,你可以輕易地實現機器學習,甚至再擴展到其他神經網路家族的應用。
- 接著是逐層地加入你的模型,在 model.add(layers.Dense(30, activation='sigmoid',input_shape=(30,))) 這一行加入了第一層的神經網路,我們給定了Dense神經元Unit =30所以的單位數量,好讓它可以接收30 個維度的欄位資訊,以一對一的方式,一個神經元學習一個欄位。
而 activation='relu' 激活函式,Relu是一個避免梯度消失的好選擇,它可以讓負值=0,正值正常地傳遞給下一層神經元來學習。 - 在 model.add(layers.Dense(1, activation='sigmoid'))這一行設定輸出,讓神經網路最終可以用一個神經元來告訴我們,它所預測的答案。
- 在 model.summary() 這一行,可以讓我們在編譯模型之前,先印出整個模型各層的資訊,以及參數,資料維度的變化。
- 若我們看完後這二層的神經網路,如果沒有要修改,接著可以繼續 model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.SGD (learning_rate= 0.1), metrics=['acc']) 在編譯模型時,透過指定損失函式、最佳化函式、成效衡量的指標,來確立訓練目標與求解方法。
- 最後 model_history = model.fit(x=x_train, y=y_train,batch_size=32,epochs=50,validation_data=(x_valid, y_valid),shuffle=True) 透過 fit 指令開始執行機器學習,x就是訓練資料,y就是答案,batch size是考量資料筆數與記憶體後,給定的批次訓練數量,至於 epoches(在 python中有許多應該要加 es的複數,在這個程式被發明時就錯了,大家也是一直將錯就錯用下去,即使它的版本還一直在更新,千萬別執著在單字上,不然你會執行不下去) validation data像是期中考,你要事先撥一些資料來給模型考試,以免它強記,考古題背太兇,會無法舉一反三,解決不了實務上的問題。shuffle 是要不要隨機,這個與重現性有關。
七、類神經網路泛用型實作:跟上面是一樣的流程(包含參數)。在程式碼中,前面先載入套件與資料,然後中間實作模型的建模,最後再用一行來預測。
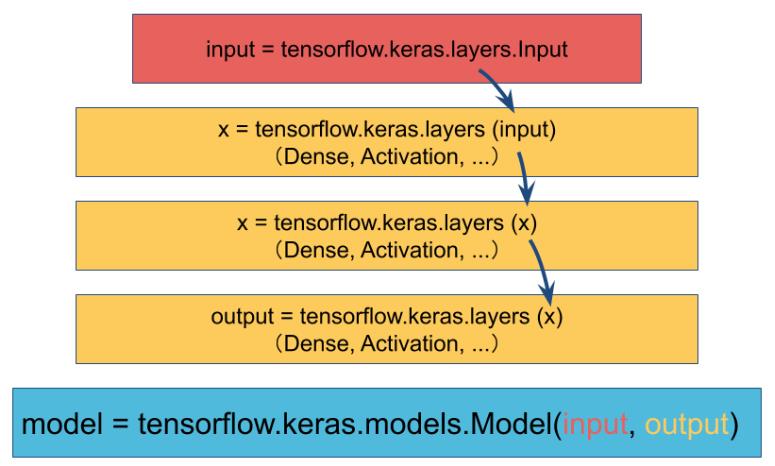
我們來比較上述簡易型與泛用型的寫法,前者使用的是 Keras的Sequential 套件,而後者使用 Functional API。
為何會說「後者會比簡易型在彈性上有更大的發揮空間」?以前面的例子來說,當你想要預測明天的股市是漲還是跌?以及明天的指數為何?在DNN中不管是廻歸還是分類問題都要轉換成數值型態,但選擇前者,你需要維護二份程式碼分別去跑不同的演算法,因為它只能接受單一的輸出,並且也只能做單一的輸出。
然後選擇後者,你只需要把 output寫二次,一次是輸出成分類;一次是輸出成廻歸。就可以在同一個Cell中維護你的程式邏輯,雖然模型比起前者大一些,但是它是能處理多重輸入與多重輸出的高彈性架構。
八、其他:本文只是探討以神經網路來建模,其實只佔了ML流程的一個小單元。若有興趣,還可以參考ML Mastery這一篇做延伸閱讀…
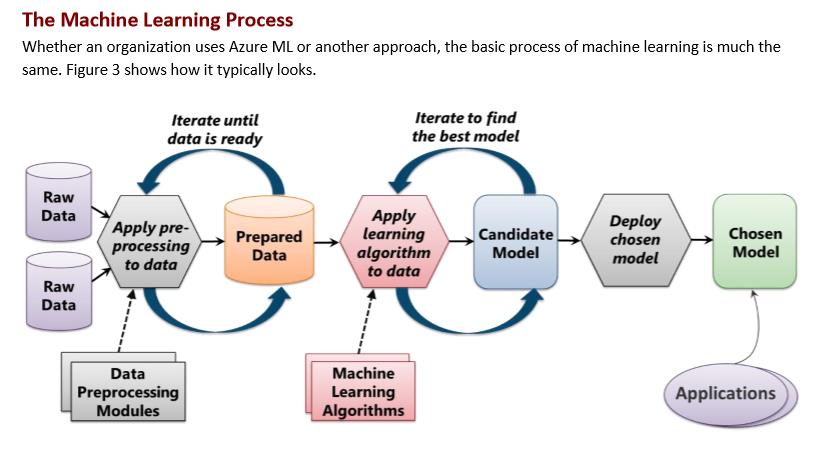
如果拉到更高的層級來看,從軟體生命週期的角度:
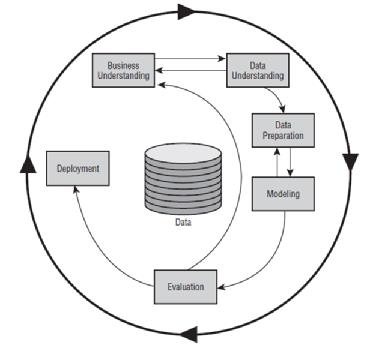
九、結論:
ANN/DNN在大數據的雲端AI時代是一個不錯的解決方案(懶人包),你僅需要準備好資料與GPU,在沒有做什麼特徵工程的前題下(在上圖可以跳過 Data understanding與Data preparation),只要你的設計理念是正確的,就能快速地訓練出一個簡易而效果也不錯的模型(比起傳統的演算法),進而能解決身邊的問題。
其次在本文中預測股價只能算是一個說教的範例,因為在現實生活中,影響股價的因子實在是太多。從全球經濟面、台灣本身的經濟/政策/景氣面…若我們僅能收集到歷史交易或是技術面的資料,即使訓練出一個神經網路,也只能說:它是一個矇著眼睛的超人,距離要拿AI來致富還有一陣距離。所幸台灣目前已經有一些新創公司在做量化AI交易,然後傳統券商也開始跟進。我們挑出其中的一個期貨AI交易來了解(期貨的影響因子比股票少很多),聽說除了勝率高,甚至還能達到 30%的獲利水準,值得大家研究看看。
補充:
[非必需] 如果你有聽過 Decay並且想用在模型的訓練,但就跟上面介紹的很像。不管是 Weight decay還是 Learning rate decay 其實都已經內建在這些新的參數之中。以前者來看,事實上 L2 regularization 就等於是權重的衰減,但你又會遇到,到底要選 L1還是 L2的 regularilation,幸運的你是可以使用二合一的 ElasticNet 懶人包。至於後者,不管是學習率的線性衰減或是指數衰減,在新的參數中都已經內建在裡面了。
李秉錡 Christian Lee
Once worked at Microsoft Taiwan