你的公司朝人工智慧在發展了嗎?這是近幾年最夯的議題。但是要回答這個問題之前,要知道人工智慧發展至今已經超過50年,所以你明白現身何處嗎?
其實人工智慧並不是新的東西,它已經歷經了三個世代的發展,正在光明地朝向第四個世代在邁進。微軟除了在地端發展機器學習,其實它更積極地發展雲端的機器學習,打算應用它近乎無窮資源的公有雲來協助企業,可以用更經濟更彈性的方式做好數位轉型…

一、前言:
- 第一世代是資料分析的世代,基礎於Kilobyte至Megabyte等級的儲存裝置,將規則透過 hardcode的方式,讓電腦依據規則來做事。又由於規則是窮舉不完的,所以人類很快就放棄了!
- 接著到了第二世代,來到了資料採礦的模型世代,啤酒與尿布的購物籃分析便是當時著名的例子。此時已經可以透過監督式學習(先由人工判斷特徵值,再靠人力標記答案),或是非監督式學習(給大量的已標記答案,再由電腦提取特徵值)。在這個時代已經能儲存 Gigabyte到Terabyte等級的大量數據。雖然當時的演算法已經大鳴大放地在大量發展,但受限於運算能力、資料前置處理(緩解掉錯誤值、極端值或遺漏值對模型的不良引響),當時僅能處理結構化的資料與較少數的應用情境。例如基礎於巴賽爾資本協定(金融海嘯的濫傷),讓銀行即使花大錢做資料採礦也要把信用風險模型完善。
- 直到GPU的問世,讓第三個世代中的深度學習得以商業化。此時的儲存裝置的級別來到了 Terabyte到Petabyte等級,運用GPU在浮點運算的優勢,除了能加速當前演算的作業時間,並且還可以平行地運行不同的候選演算法,取得最佳解。例如,著名的世界圍棋棋王的人機對戰 AlphaGo就是以 CNN演算法戰勝人類的。
- 隨著資料儲存量推向 Petabyte到Exabyte等級,號稱 Auto ML自動機器學習的第四世代已經靜悄稍問世了。在這個世代中,惱人的資料前置處理、演算法的選擇、資料集的分割,甚至是演算法中參數的調整,都能有電腦的幫忙,只要你能提供運算力。所幸身處於雲端時代的我們,現在只要有預算,剩下的就是能不能找到好的應用題目來做Machine Learning?
**若你對於演算法有興趣,我之前有寫一篇 SQL Server Data mining,裡面有介紹 SQL Server所提供的五大類演算法
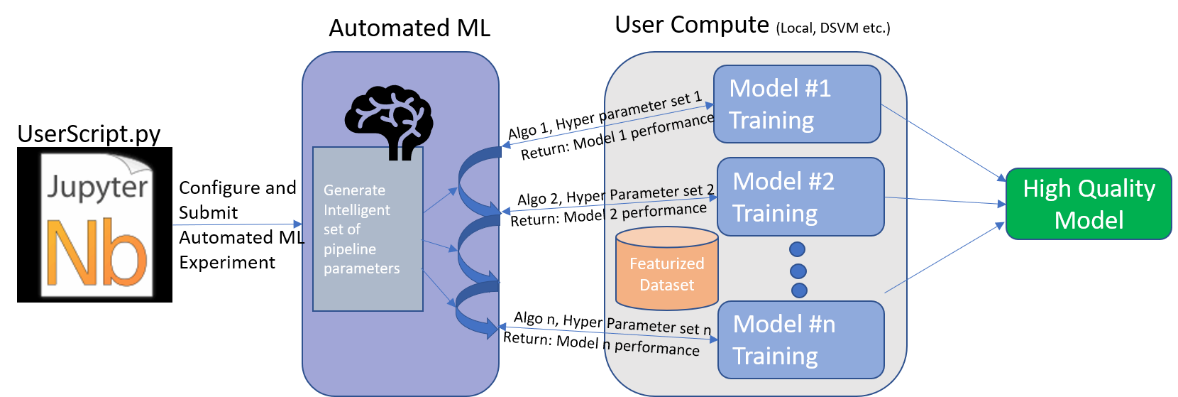
上圖是第四個世代的 Automated Machine Learning架構圖
**微軟高層體認到這個重要且舉足輕重的 AI趨勢,除了及早佈局也重兵壓在這個領域。根據 CB Insights的統計,微軟由2009至2016在五大科技大廠的專利申請件數,位居第一。
二、從統計到深度學習技術演進
- Statistics統計:這是人類最早實現一葉之秋的自動化資料運算的成就,輸入為「資料前處理(等於現在的 feature engineering,當初還沒有發明這個名詞)」,中間的處理為「資料建模」,輸出為「資料分佈、預測(後期已經能做資料的推估了)」
- Traditional machine learning:由於人類對於統計上的限制並不滿意,包含了資料集需要每一筆都要算過,運算曠日費時沒有效率;死板的輸入與輸出結構不適於複雜任務,僅能等前一個任務的輸出算出來,才能丟到下一個任務的輸入;無法處理多維度的任務,除了運算費時費力,多維度的結果呈現人類也無法理解或解釋。在大鳴大放的程式語言時代,再加上 Gradient descent (一種稱之為梯度下降法或是最陡下山法的最佳解方式,讓資料不需要全部運算過,就能快速地算出結果)、Regularization(對抗極值 outlier)…等手法,機器學習就因應而生了。此時的輸入為「特徵工程 feature engineering (如果是監督式學習,裡面會有成對的 feature vs. label)」,中間的處理「資料建模與收歛」,輸出為「預測的結果(數值、分類)」。它可以讓人隨心所欲的控制資料輸入、特徵工程(例如 Normalization)、客製化模型架構(例如權重共享的孿生模型)、輸出最終結果或是成為另一個輸入。像 Ensemble learning 就是機器學習的其中一個分支,它應用了富彈性的結構,讓同一個任務,可以動用多個不同的演算法去算,最後再將答案做彙總。並能驗證三個臭皮匠勝過一個諸葛亮的至古名言。另外 SVM (Support vector machine) 演算法可以將高維度的空間,投影至低維度的空間做呈現,來協助人類解釋複雜的事物。讓人類苦於類神經網路一直無法突破(當時還沒有 GPU),柳暗花明又一春,可以有新的舞台來發揮。也實現了比一葉之秋更進階的抽象推理(類似人類的歸納/演譯)。
- Deep learning:由於GPU的普及與應用,以及幾個關鍵的手法,讓類神經網路得以突破20~30層的限制(機器學習的 Gradient descent 雖然可以高效地算出結果,但成也蕭何敗也蕭何。層層傳遞的結構,也因為參數愈乘愈大或是愈乘愈小,而發生梯度爆炸或是梯度消失,突破的方法可以參考這一篇)。輸入為「特徵工程 feature engineering」,中間的處理「資料建模與收歛」,輸出為「預測的結果(數值、分類、方程式)」仔細看,輸出時多了一種「方程式」,是 AlphaGo 可以靠增強式學習打敗人類棋王的關鍵。至於我所謂的關鍵手法,包含了反省、遺忘、降維思考…等,所謂的反省就是 Backward propagation 讓模型可以看到 Label答案後再更新權重,類似人類一日三省吾身或是驗算的行為;遺忘就是 Drop out 強迫模型隨機放棄一半的權重,重新強迫再次學習,類似人類滿招損,謙受益的空杯歸零心態;降維思考這一門高深的學問,例如捲積 convolution + 池化 pooling 特徵提取,先學點/線/面、學邊緣/輪廓、學器官/部位…;又例如 Representation leaning 表徵學習,就是透過編碼 encorder + 解碼 decorder 特徵提取,由正常視野學習改成鳥瞰學習,再翻回正常視野對答案,像極了人類的「腦補」…林林總總的關鍵手法,讓深度學習的成效可以更加貼近萬物之靈的神奇大腦,繼續往更抽象的人類推理層次去邁進。
三、AI的流程
以 Azure Machine Learning Studio為例(使用其他工具也是大同小異),以下將介紹常用的流程:
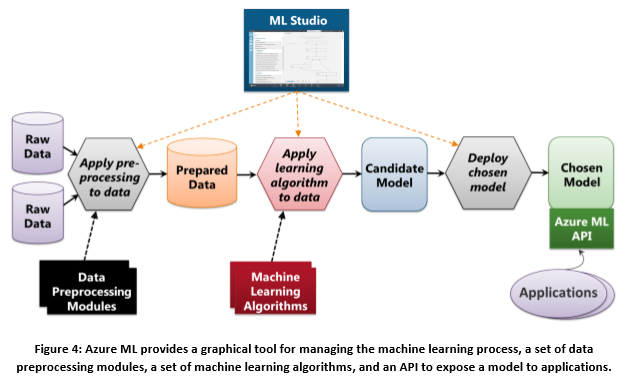
- 原始資料:包含文字檔(TXT,CSV...各種Log)、Excel檔、資料庫、音檔、影片…等
- 資料前置處理:包含壓縮/解壓縮、資料組合或拆分(以Tab、空白、逗號)、例外值/遺漏值處理、剔除用不到的欄位、日期時間的處理、小數點進位或刪去、代碼與文字置換、訓練集與驗證集切分、影音檔轉格式、影片Flame訊框裁切或組合、商業邏輯檢查與過濾(例如身份證第一碼為 A)…等
- 整理好的資料:能以表格呈現的資料,才能檢視與挑選特徵值
- 選擇演算法:依據原始資料的特性以及要解決的問題(例如分類、分群、因果關係、最佳解)去挑選適合的演算法
- 候選模型:將剛才資料前置處理中做好的訓練集與驗證集切分中的訓練集,例如90%的訓練集去訓練候選的模型,當模型訓練好,就會將結果(Target Value)寫入剛才"整理好的資料"表格式的呈現中,接著還要將驗證集去檢驗這個模型的準確性
- 佈署選中的模型:若是底層是 R或是Python就能直接被前端呼叫,若不是,則是可以佈署成 Web Service被前端的程式(包含Excel)來呼叫
四、微軟的AI 解決方案
1、AI平台:裡面包含了人工智慧(或稱為機器學習)服務/基礎建設/工具,細節可以參考官網(英文)做延伸的閱讀
我們先由 Azure AI Service開始
所謂 Azure AI Service 指的是在雲端的Saas服務,由左至右分別是Cognitive Services認知服務(Rrebuild AI)、Bot Service機器人服務(Conversational AI)、Azure Machine Learning機器學習(Custom AI)
**認知服務:這個服務就像是人類的五官的延伸,但是你不用養一堆科學家,直接就可以呼叫微軟的API來使用。它是一系列事先訓練好的模型,它將可以協助你辨識照片或是影片的內容、聽一段音檔分辦出這個幾個人的對話,甚至將對話的內容變成文字、同時針對不同的資料來源做查找、在人機對談的溝通中理解人類想要表達的內容…
想像一下,原本平淡無奇的應用程式、網站和 Bot,一但融入了智慧型演算法,就能與使用者透過自然的溝通方式,來查看、聆聽、述說、理解及詮釋使用者的需求。即使沒有聲名大噪,至少你的客戶都會死忠地愛上你們家。
**機器人服務:這是一個對話型的人工智慧服務,可以應用在客戶服務、網頁助手、人機互動…等應用情境。它將可以協助你建置、連線、部署及管理智慧機器人,使其在網路、應用程式、Microsoft Teams、Skype、Slack、Facebook Messenger 等管道上,與使用者自然地互動。利用完整的機器人建置環境快速入門。而且用多少付多少,不需要比照傳統的方式,先買一台伺服器才能開工,生意好要擔心系統是否能擴充,生意不好要擔心,如何降低營運成本…。
**機器學習:這是一個高度客製化的人工智慧服務,當上述二個服務的內容或是品質不能滿足你的需求時。由於前者是 PreBuild 通用型的解決方案,當我們開始發展 domain know how或是做更深入的企業應用時,就需要運用自己的資料,發展自己的模型,或是加入 Python、R之類的解決方案在自己的應用上。

接著是 Azure AI Infrastructure
上述的Saas服務雖然便利,但它就像是捷運,有許多限制(不能決定路線、不能吃東西…)。當我們在資料面、運算面有更進階的需求時,會需要考量 Iaas或 Paas的運算資源。
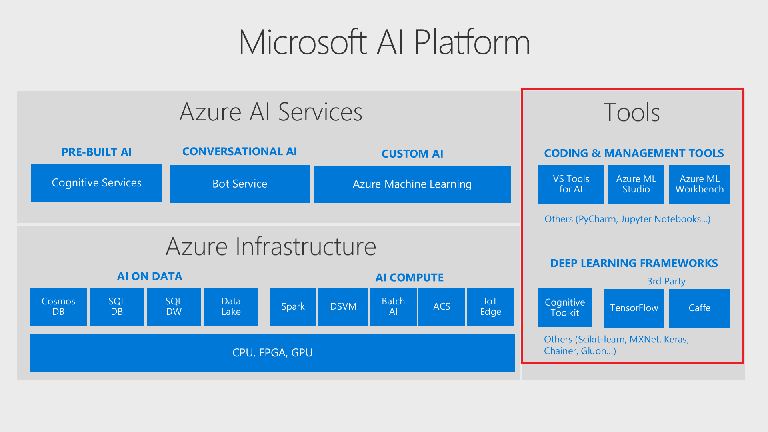
**AI on Data:包含兼具成本與安全管理的泛型 Data Lake(裡面包括了大數據處理/儲存/分析,三種類型的應用)、關聯式的資料庫 SQLDB與資料倉儲SQLDW、非關聯式的 NoSQL資料庫CosmosDB
**AI Compute:包含處理大數據的Spark、微軟準備的Data scientist visual machine環境(有Windows與Linux可以選擇)、批次AI(適用於AI運算量很大,需要爭取時間來做分散式運算。可惜的是這個產品將來會被整併到Azure machine learning service中)、微軟先進的容器化服務 Azure Container Instances(它是AKS的進化版)、IoT Edge 邊際運算(適合於網路受限的工廠生產環境中)
**AI Core Infrastructure:完全掌握使用何種運算資源或是其混合比例,包含自己決定多少的 CPU、FPGA、GPU運算資源的規格,都可以在這裡得到滿足。當然,大家都知道是 GPU讓 AI邁入第三個世代的,但是它的價格還是比 CPU貴上3倍;若你沒有把握,使用 GPU讓你的專案比 CPU快上3倍,建議你還是使用熟悉的 CPU就好

上圖是CPU(中央處理器)/GPU(圖形處理器)/FPGA(可程式化閘陣列)/ASIC(積體電路)的比較,細節可以參考官網的說明

上圖是IoT Edge的使用情境
上圖是 BatchAI的系統架構
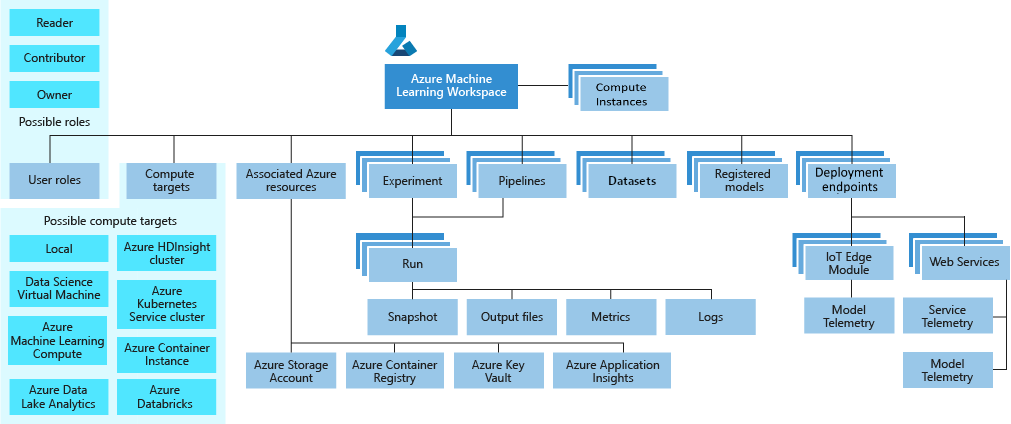
上圖是 Azure Machine Learning的架構圖
最後是 AI Tools
**開發環境:包含Visual Studio for AI、Azure Machine Learnaing Studio、Azure Machine Learnaing Workbench
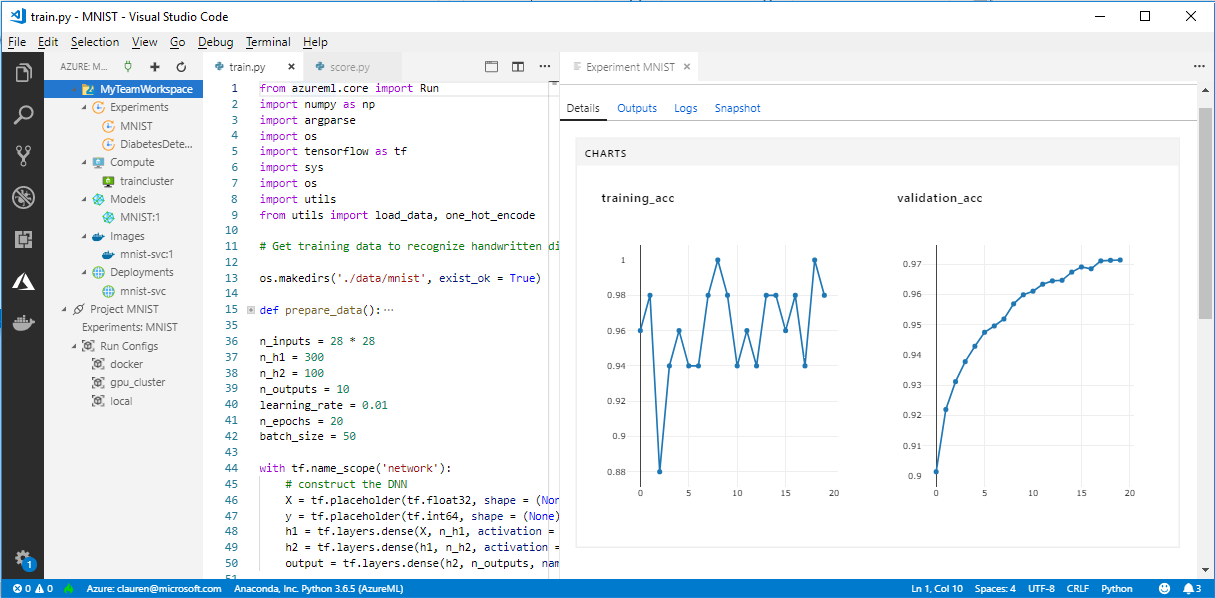
上圖是Visual Studio Code Tools for AI的 UI畫面
**深度學習 Framework環境:包含微軟認知服務的Toolkit(CNTK) 或是第三方的 TensonFlow及Caffe
基礎於微軟與 Facebook所合作的 ONNX,它是一種有利於可攜性的 AI中介模型格式,不管你是使用 Cognitive Toolkit/ Caffe2/ PyTorch 所創建出來的模型,轉換成ONNX 就可以運行在微軟雲端或是地端的解決方案上。讓想用微軟 Azure的客戶可以無痛上車,因為不用把開發的框架換掉,類似軟體工程中應用 Interface整合異質或新舊版本的手法是一樣。
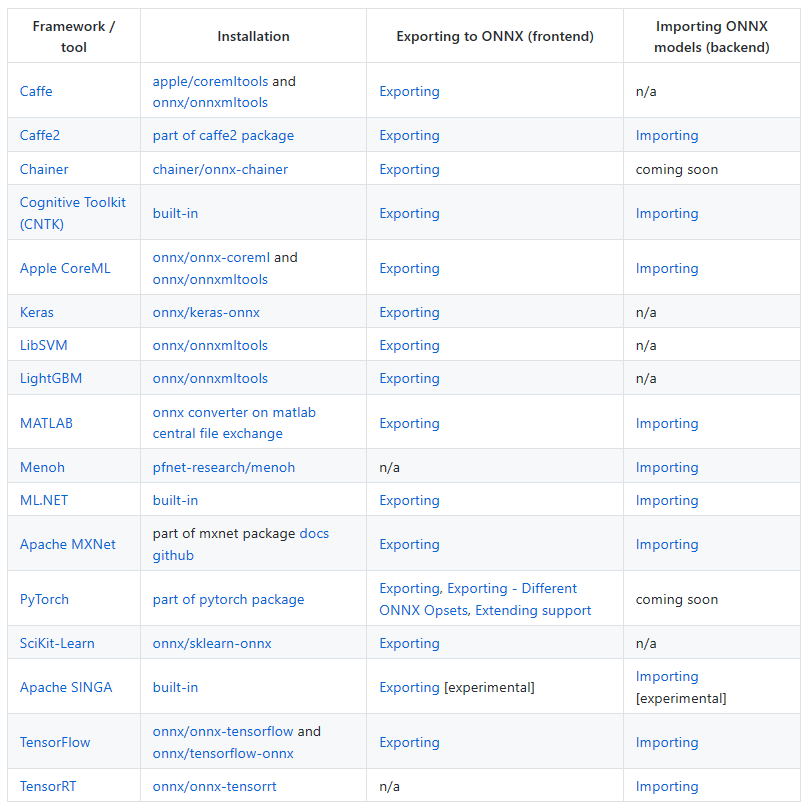
上圖是 ONNX對各家模型支援的列表,細節可以參考實作一次 https://github.com/onnx/tutorials
2、企業的資料數位資產
微軟從 1989年與 Sybase合作的 SQL Server 1.0至今的 SQL Server 2019,橫跨了三十個年頭,協助客戶處理輕量或是巨量的資料,包含了結構化與非結構化資料(影音資料)。其中最重要的就是客戶資料,尤其是客戶的行為。一但這些資料可以結合,外部的公開資料(天氣、社會趨勢、財金脈動…),將來轉換成可觀收入…
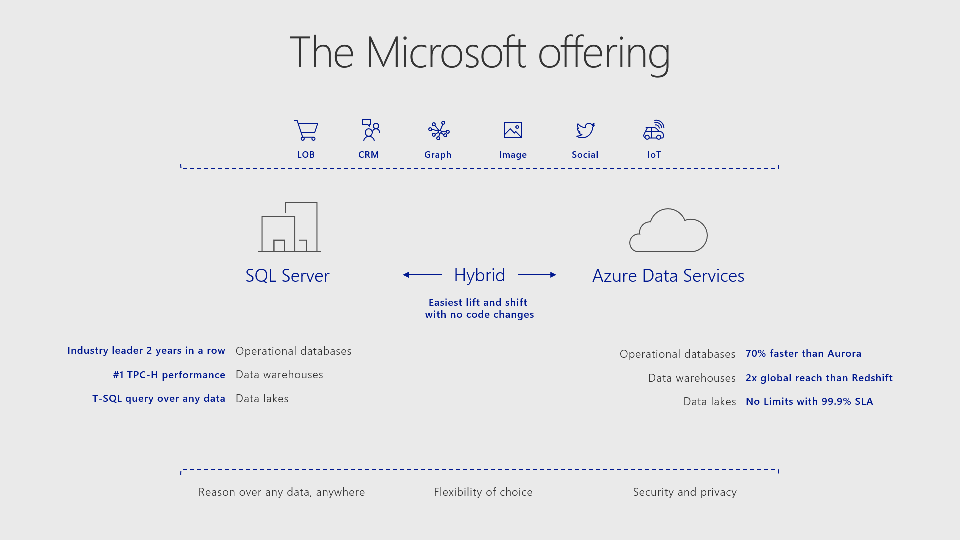
隨著時間的推進,巨量資料的儲存、處理、分析的解決方案都不斷地推陳出新,身處雲端時代的我們,是否還需要受限於「什麼都還沒有拿到就要先投資一堆硬體」舊有思維?至少新的需求或是專案,開始嚐試雲端的便利
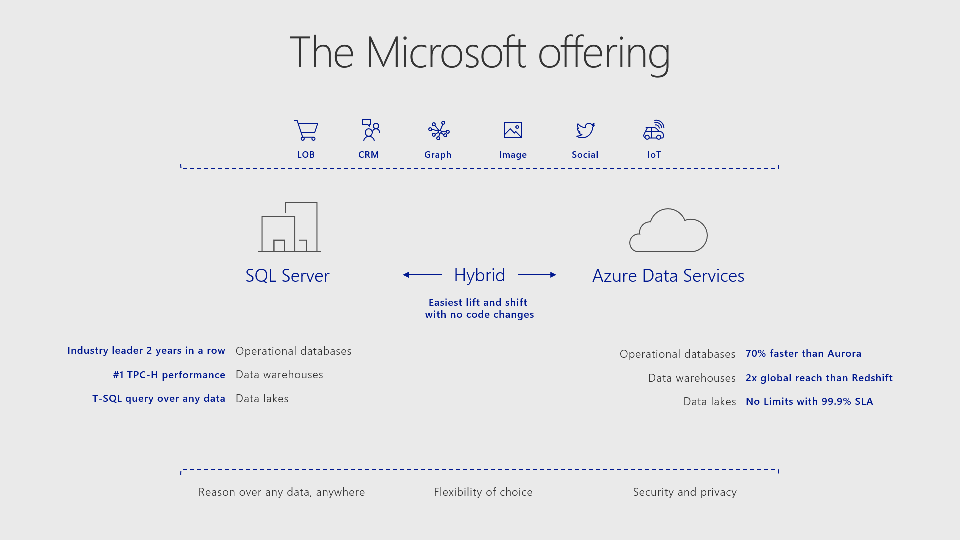
一但,我們接受了混合雲的思維,就會發現有許多潛在商機或是可優化的流程,等著我們去挖掘與開發…
所以我們可以應用擁有三十年歷史一直不斷進化的 SQL Server(我們將在第四單元來介紹),或是另外還有一個分支叫作 Windows AI,細節可以參考官網(英文)的說明,它是定位在習慣高階程式語言的族群,基礎於 DirectML框架的應用,細節可以參考官網(英文)的說明。
3、已被企業驗證過的解決方案
首先是微軟先將自家的產品都內建 AI,例如 Office系統、遊戲機、開發工具、公有雲服務、甚至是 ERP/CRM 這類的商業應用…

接著是 Azure AI Gallery (前身為Cortana Inteligence Gallery),裡面有成百上千的 Template,讓你可以參考別人的 AI專案,入門的可以參考並學習別人是怎麼做的?資深的可以參考現成的 Template加速專案的進行…
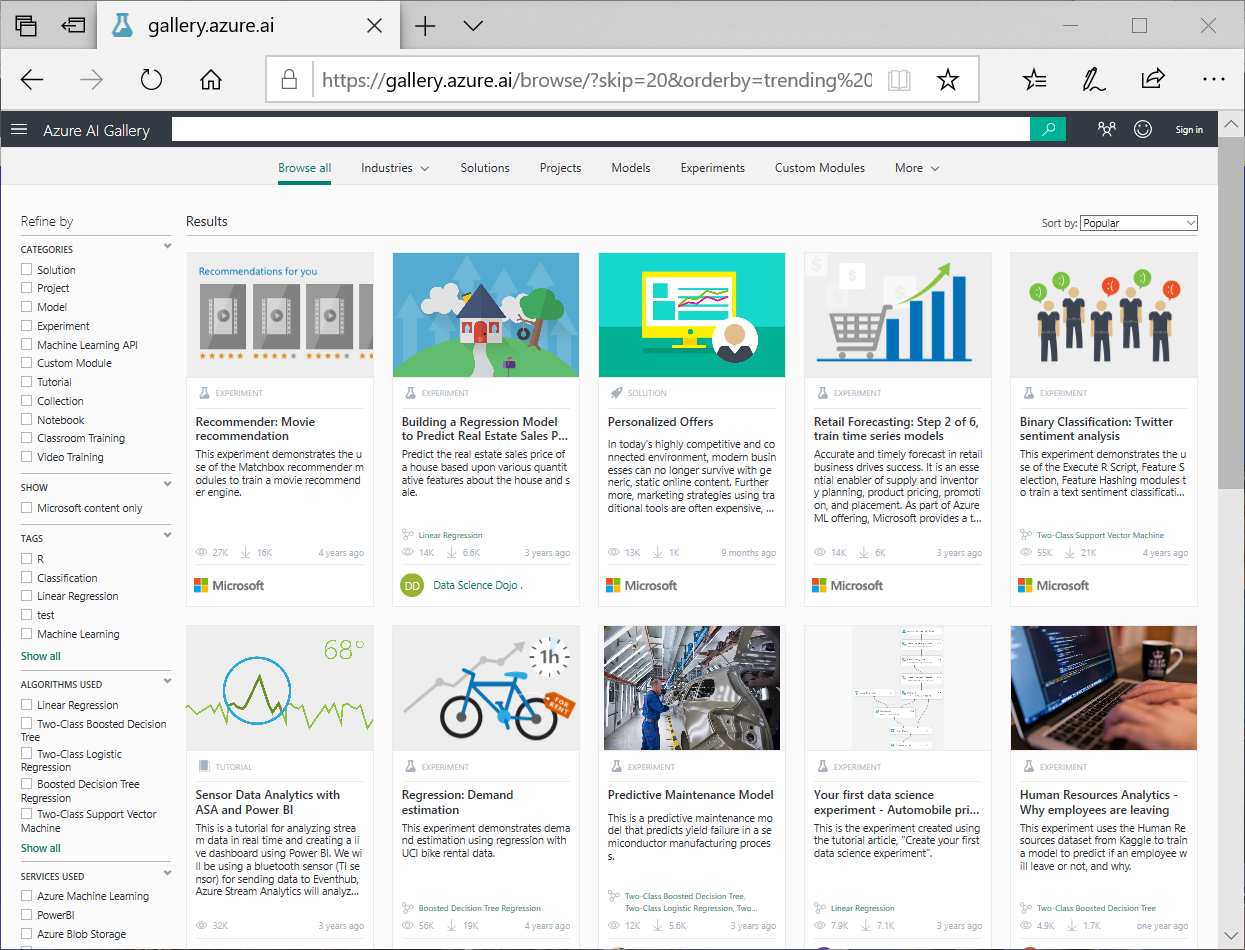
微軟的 D365 AI產品,在全球已經得到許多知名的大客戶不錯的口碑與推薦,它有 Sales Insights模組,可以提供輔助的資訊,改善決策的制定流程,甚至可以提高整體的銷售量;Customer Insights模組,可以全方面地取得客戶的相關資料,更快且更便利地實現客戶體驗的個人化;Customer Service Insights模組,將可以透過 AI驅動的分析,改善決策的制定流程,並且能主動地改善客戶滿意度…

五、SQL Server 中R Service 的演算法介紹
若是你的機器學習專案是屬於 In-Database分析,例如 Hadoop/ Teradata/ Linux/ Windows(SQL Server),對於 R/Python語言一定不陌生。以Windows / Linux工作環境為例,你的選擇可以是 SQL2016的 R Service或是 SQL2017的 Machine Learning Services(同時支援 R與Python,另外 Linux也是要這個版本才支援)。
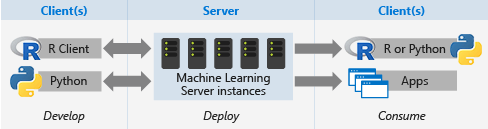
上圖是呼應剛才介紹的第二單元(AI流程),與雲端中的 Azure Machine Learning Studio一致,當我們做到流程 "F.佈署選中的模型"時,一樣是可以由 R/Python的 Client端直接呼叫 SQL Server
在資源的選擇上,若你覺得重新學習 Azure Machine Studio很麻煩,但是地端的資源不足又想利用雲端。你可以選擇純 VM的方式,請參考官方Blog(英文)中一鍵佈署 ARM的方法;或是選擇 DSVM(Data Scientist Visual Machine),請參考官網(英文)的說明。
最後,我們來談談在 SQL Server上機器學習的發展,當機器學習來到第二個世代,在2000年時大家都很熱烈地在討論 Data mining,但微軟並沒有產品可以賣,但其實是因為高層考量了功能的全面性與 Time to market若無法同時被顧及,所以 SQL2000 在上市時只能先抓住關聯式資料庫的重點,接著在嚴謹的測試後,Data mining的模組外掛在 SQL Server Analysis Services (SSAS) 終於千呼萬喚始出來,隨著 Service Pack釋出了(需要買企業版才能使用)。接著在 SQL2005發展的更加完備,企業可以透過以 Visual Studio為底層重新開發的 SQL Server Integrattion Service(SSIS),來實現 ETL (Extract /Transform /Load 資料清理與準備),以及預測分析的機器學習(其演算法包括 EM 和 K-Means 叢集模型/類神經網路/羅吉斯迴歸/線性迴歸/決策樹/貝氏機率分類分類器…等),和報表服務(SQL Server Reporting Service)在視覺化的呈現。整體來說,這是當時微軟所推出的從資料採礦整合到商業智慧的 end to end 解決方案。只需要學習 XMLA、Data Mining Extensions (DMX)便能進行較進階的開發、改善與模型的評估。
以演算法的發展來看,可惜的是,在 SQL2005之後的版本,就沒有再增加新的演算法。直到,微軟於2015年買下 Revolution R,就像突然打開任督二脈,又將機器學習推向更高的層次。當初在評估時就是看上了它超過7000個 Package,以及在它在開源、統計、學術…等領域的高滲透成就。它的演算法可以粗略分成十幾類:包含Data Step/ Descriptive Statistics/ Sampling/ Predictive Models/ Variable Selection/ Simulation/ Cluster Analysis/ Classification/ Combination

CRAN 是 Open R最主要的 Packeage平台,其他就屬 Bioconductor與 GitHub

所謂的 Open R就是免費的單執行緒版本,Revolution R就是付費的多執行緖版本。被微軟買下來之後,並不用擔心開源的部份會被私有化(變成私人財權),反而微軟會投入類似 Dot net 基金會之類的資源,協助並壯大其發展…

另外機器學習與資料庫整合還有一個好處,就是 DBA不必事先去了解 ML,只需用 StoredProcedure就可以去呼叫 ML,即可完成協同合作的任務。
李秉錡 Christian Lee
Once worked at Microsoft Taiwan