PaddleOCR應用硬傷和MiniCPM-V(已改名為MiniCPM-o)Finetune踩坑後的紀錄與分析。
MiniCPM-V 2.6 finetune準確率、Transformer架構與vLLM速度驗證。
reference:https://github.com/PaddlePaddle/PaddleOCR、https://github.com/OpenBMB/MiniCPM-o、https://modelbest.feishu.cn/wiki/LZxLwp4Lzi29vXklYLFchwN5nCf
一. 此篇網誌撰寫之背景
2024年是我目前職涯中變動最大的一年,幾年前從原本單純的AP 開發Team被主管拉去做Hadoop大數據,2024下半年開始爭取進入AI Team,也有一個超強的AI技術職主管帶領,但半年後主管離職,我在AI Team只剩3人(我+2個會AI的新人小朋友)的情況下,正式進入AI模型訓練與應用的世界,但也是因為技術主管離職,靠著自己鑽研今天我才寫得出來這篇網誌(笑)。
二. 前言
本篇與各位在網路上所搜尋到的MiniCPM-V介紹文章不同,網路上的文章大多是介紹使用MiniCPM-V pretrained model如何使用以及使用心得,本篇是將pretrained model經過finetune後在憑證OCR的場景完成end to end落地應用,並取得不錯的辨識效果。
我會先從一開始使用PaddleOCR實作後遇到的問題切入,並說明PaddleOCR無法克服的硬傷(我不是要批評PaddleOCR,的確在某些場景應用上,PaddleOCR和MiniCPM-V的準確度差不多,但PaddleOCR的推論速度大勝),最後帶到為什麼需要使用大語言模型MiniCPM-V去解OCR,同時將MiniCPM-V官方沒有說明清楚的finetune流程,以個人實作過後的經驗做分享。
文章很長東西很多,若只想看MiniCPM-V 2.6 finetune重點的可以直接跳到第五部分,但若跟我一樣屬於OCR初學者,建議從頭看完會比較有感。

三. PaddleOCR的接觸與應用
PaddleOCR其實已經問世很久也很多人使用,推論的速度也是非常的優秀,剛進AI Team的時候,技術主管帶著我們做OCR的專案也是用PaddleOCR,但隨著公司的應用場景越來越複雜,需要進一步tune模型時,其問題也慢慢浮現:
(一). 以一個OCR小白初接觸的觀點來看,finetune的相關文件似乎沒有揭露得很清楚
舉例來說我們finetune到後來發現很重要的data augment參數如CopyPaste(我們後來tune出來的模型,證實這是非常重要的參數),在官方的yml檔上也只是顯示空白,沒有告訴你要寫什麼,我跟團隊裡的小朋友花很多時間在找finetune裡的yml設定到底要怎麼寫,甚至還去讀PaddleOCR image augment的code,到處去翻網路上其他前輩的training yml檔,才兜出設定檔來。
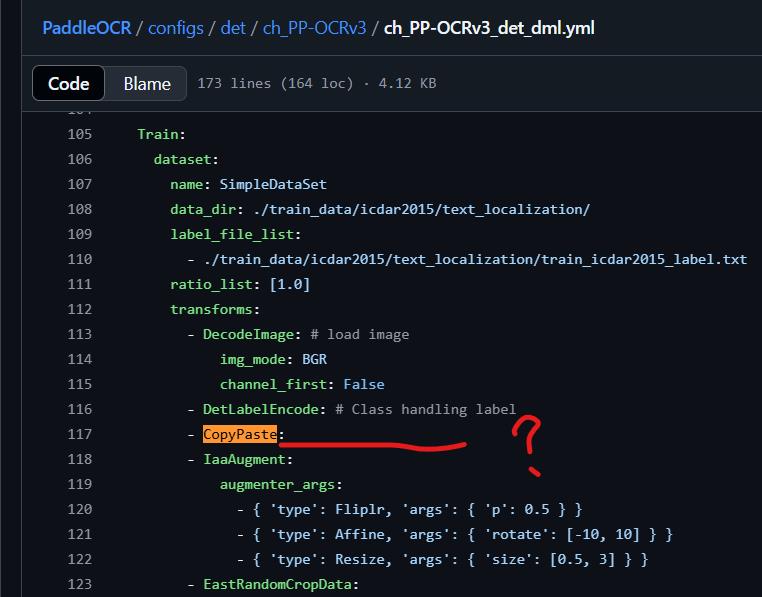
(二). 推論後的結果,回傳順序在某些狀況下會遇到問題
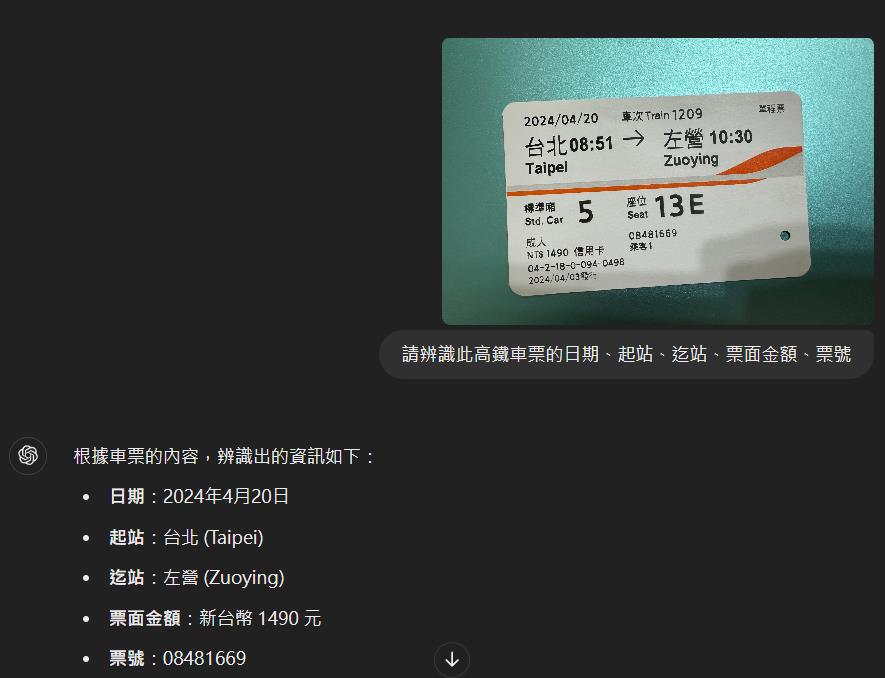
以下面這張高鐵票來說,我們想要辨識乘車日期、起訖站名、票價與票號,在PaddleOCR的detection與recgnition模型訓練上是沒有任何問題的,東西都可以正確抓到並且辨識出來,但實務上如果要回傳結果給使用者,我們必須清楚地告訴人家起站與迄站分別是哪兩個名稱,在票面上沒有任何key-value的對應情況下我們是不會知道的,僅能用站名是幾個中文字這樣的規則,以及回傳順序(PaddleOCR回傳順序是由左至右,由上而下)去將起迄站資訊取出來。
但我們可以發現下面這張高鐵票經過PaddleOCR辨識後,起訖站的順序明顯給顛倒了,這是因為PaddleOCR除了使用上述規則判斷外,也有對於列在同一行的資訊做一些處理,同一行偵測框高度差在某個門檻值內會被視作同一行,靠左邊的物件順序會在比較前面,程式碼在這裡https://github.com/PaddlePaddle/PaddleOCR/blob/main/tools/infer/predict_system.py。
但這樣的做法就會造成當圖片有些許歪斜或是內容排列不工整時,偵測框順序就會錯亂,即使你去調門檻值也無濟於事,我也有參考網路上其他大神的修改方式調整排序,遺憾的是這種做法最終沒有辦法解決因歪斜與排列不工整造成的順序錯亂問題。

(三). 偵測框大小參數det_db_unclip_ratio無法一體適用的調整問題
這項也是我們在訓練PaddleOCR要辨識多種憑證時發現的無解問題,例如下面的電子發票推論後可以發現,似乎在det_db_unclip_ratio設定為1.5的情況下會有發票號碼無法完全包覆的問題,這會造成後續rec模型在辨識偵測框裡面的字時辨識錯誤(因為東西沒有框完整),但同樣的設定在辨識高鐵票上卻沒有框框過小的問題。
此時若我們調大det_db_unclip_ratio為3.0,讓電子發票號碼可以完全框住(其實也沒完整框到),卻發現其他偵測框過大概到其他區域,沒有辦法用一個設定值cover所有的偵測框,同時det_db_unclip_ratio=3.0的設定,對高鐵票來說,偵測框又變得太大。
上述情形,尤其遇到文本中的資訊過於密集時情況會更惡化,資訊過於密集代表偵測框需要分常準確的框住你要偵測的物件上,稍有不準就會框到雜訊,造成後面的rec模型辨識度差。


(四). 模型推論完成後的資訊擷取Parsing不易
雖然PaddleOCR有KIE(Key Information Extraction)的功能,但實務上我們要辨識的東西很多是沒有key-value可以讓你這樣標的(例如臺鐵、高鐵車票),這也導致後續將資訊取出只能靠順序、關鍵字等方法去擷取,這會造成資訊擷取正確率非常不穩定,即使有key-value,也會遇到很奇琶的問題,舉例如下圖,我們辨識某票證上面有買方公司行號名稱,但實務上我們就發現有那種"買方"變成"買受人"字樣的問題。站在user的立場,我們也不能說這樣的東西是有問題的,只是case比較少,但還是要求我們要解決,但我們不可能無限制的去加關鍵字解這種問題,這會增加維運的effort。

整體來說,個人認為PaddleOCR適合應用的情形如下:
- 格式工整的文件如PDF電子檔
- 內容不會太密集的文件(像電子發票就不太適合)
- 格式與內容不太會大變動的文件(像臺鐵與高鐵票就不太適合,偶而會面臨大改版)
如果是要辨識手拍照片、政府公文、紙本車票,實際應用上會出現很多問題,尤其是像電子發票這種,每一個商家開出來的發票字型都長得不太一樣,寬度和密集度也都長得不一樣,至少我們直接用PaddleOCR試過之後,真的是不太適合,可能在推論前必須要教育user拍攝圖片的方式以及對圖片做透視變換之類的前處理,才能有效提升正確率。
四. PaddleOCR上線後的痛苦掙扎期
前一段我們提到PaddleOCR推論完後資訊取得的問題,其實這才是整個OCR最重要的環節,如果不能精準的告訴使用你模型的人他想要辨識的字是什麼,那模型等於沒有用。第一階段PaddleOCR模型上線後,我們家小朋友一直接到前端反饋有什麼圖片裡面的字偵測不到,從log裡面看到的狀況是,一旦出現key關鍵字變動、圖片歪斜稍微多一點或是出現資料集裡較少甚至沒有的圖,就容易辨識有誤(例如電子發票的票號字型和寬度千變萬化,是我們模型最常被反應有問題的欄位,但也是user最care的欄位)。
有鑑於此,我一直在思考有沒有辦法訓練一個模型,OCR完成後可以依照我想要的格式吐結果,省去後續parsing維運的effort和風險,要快速有效的話其實直接接線上有的大語言模型API是個不錯的解法,現在的chatgpt其實OCR能力已經相當優秀,但畢竟它不是針對特定場景做finetune,吐回來的結果會有模型自己的加工,東西也不見得是正確的,最令人頭痛的是吐回來的結果中的key-value不會每次都一樣,這也會造成後續parsing的困擾。經過我們自己想要應用的場景實測,其欄位辨識正確率也才80%左右,與其他同事之前使用在其他場景統計出來的正確率差不多。
此時我們發現MiniCPM-V的存在,當時它已經從MiniCPM-V 1.0、MiniCPM-V 2.0、MiniCPM-Llama3-V 2.5一路出到MiniCPM-V 2.6,尤其2.6是個8B參數的模型,我其實不是很確定公司的機器是否效能足以使用(公司使用NVIDIA RTX 6000 Ada Generation,單卡GPU記憶體也才48G),但抱著試試看的心態,我踏上MiniCPM-V POC的旅程。
五. 開源大語言模型MiniCPM-V POC
MiniCPM-V我try過2.0、2.5、2.6這三個版本,使用的都是full-finetune(lora-finetune有try過後效果不佳就不考慮了),其中2.0的版本你照官方給的格式去做資料訓練,會遇到data fetch error的問題https://github.com/OpenBMB/MiniCPM-o/issues/652,但依照別人的issue回饋改一下程式碼一樣可以練得出來,整體來說依據公司需要的場景finetune後我自己的結論如下表:
| 模型版本 | 模型釋出時間 | 參數量 | 全量微調後效果 |
|---|---|---|---|
| MiniCPM-V 2.0 | 2024.02.01 | 2.8B | 推論速度約2秒,準確度差強人意 |
| MiniCPM-Llama3-V 2.5 | 2024.05.20 | 8B | 推論速度約4秒,準確度較2.0強,已達可實際應用等級 |
| MiniCPM-V 2.6 | 2024.08.14 | 8B | 推論速度約3秒,準確度較2.5更好,已達可實際應用等級 |
| MiniCPM-o 2.6 | 2025.01.13 | 8.67B | 2025/1/13才出來,我還沒時間try >.< |
基於以上初步POC速度上的結論,我選了MiniCPM-V 2.6往下繼續做模型的優化和使用。
(一). 模型全量finetune需參考的文件
踩了這麼多坑,最後發現其實只要看兩個地方的文件就好,分別是github上的V2.6最佳實踐以及飛書上作者寫的比較細的finetune指南。
https://github.com/OpenBMB/MiniCPM-o/blob/main/finetune/readme.md
https://modelbest.feishu.cn/wiki/LZxLwp4Lzi29vXklYLFchwN5nCf
其模型的前處理原理以及token數計算,可以參考MiniCPM-Llama3-V 2.5的部分,有詳細的解說。
https://modelbest.feishu.cn/wiki/X15nwGzqpioxlikbi2RcXDpJnjd
(二). WSL2環境準備
我是自己爭取進入AI Team的,公司沒有配有Nvidia GPU的電競筆電給我,我是用之前為了研究Yolo模型在1111檔期的時候去京東商城買了一台有RTX4060的顯卡筆電自己弄(當然這張卡是不可能訓練和使用大語言模型的,但把環境裝起來這件事情基本上還是可以的)。我是在Windows作業系統上使用WSL2安裝ubuntu 22.04後,生出docker image出來再轉移到公司的GPU Server上使用,架構基本上跟我前一篇文本糾錯網誌使用的架構是一樣的。
使用WSL2的好處就是快速且方便,且不用另外準備一台電腦安裝作業系統。但我使用了半年以上,發現其實還是有一些問題(不過都是可以克服的),通常都是發生在Windows做了例行性更新後:
- GPU可能會在工作管理員中消失,此時你在WSL2中下指令docker run -itd --gpus all時會整個hang住無法建立container,解決方法只需要去BIOS異動中選擇進階→顯示模式→選擇僅有dGPU,之後啟動Windows時就會發現GPU出現並可使用了(這個我當初也是卡好久,最後才發現是這個很瞎的問題)。
- WSL2裡面的cuda相關.so的檔案,在執行時通常需要的是軟鏈結,但可能是微軟和Nvidia在整進WSL2的時候沒弄好,有些會變成實體檔案,造成執行期間系統回報找不到.so檔(像這種狀況https://github.com/microsoft/WSL/issues/5663),可以直接在Windows路徑C:\Windows\System32\lxss\lib(宿主機ubuntu上的路徑是/mnt/c/Windows/System32/lxss/lib)下做修改,如果刪除檔案有權限問題,可以設定trustintaller後再刪除https://zhuanlan.zhihu.com/p/108569823。
- 2025/03/24更新,我發現這些軟鏈結若沒有修改就去包Image的話,會出現一個很怪的情形,在WSL這台機器上下torch.cuda.is_available()會是true,包出來的Image拿到別台GPU Server上佈署時torch.cuda.is_available()會變成false(真的是見鬼了)。
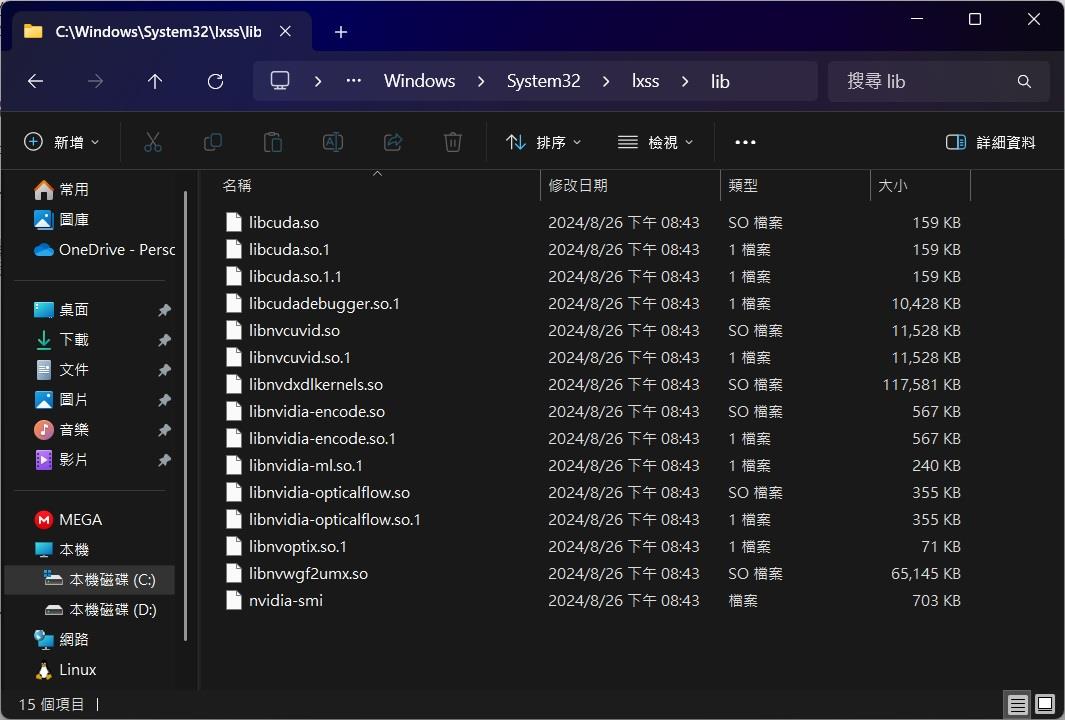
copy libnvidia-ml.so.1 libnvidia-ml.so.1.1
del libnvidia-ml.so.1
mklink libnvidia-ml.so.1 libnvidia-ml.so.1.1 #libnvidia-ml.so.1鏈結指向libnvidia-ml.so.1.1實體檔案
del libcuda.so
del libcuda.so.1
mklink libcuda.so libcuda.so.1.1
mklink libcuda.so.1 libcuda.so.1.1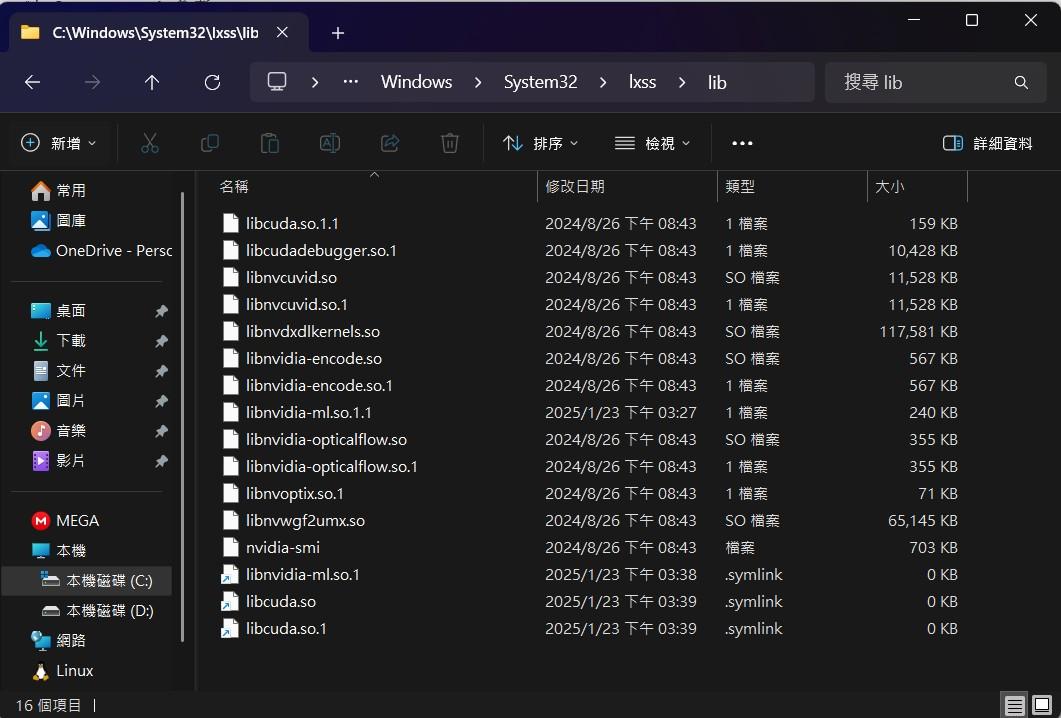
(三). 訓練環境準備
上述WSL2環境問題確認好後,就可以安心的使用docker建container出來,不過基本上你如果照官方github上面的requirements.txt去安裝是沒有辦法訓練的,因為這些環境設定都是建立在當下開發者他的環境狀態所列出來需要安裝的東西,實際上你若從乾淨的ubuntu作業系統安裝,一定是會缺東缺西,相信有在玩AI模型訓練的一定都知道,克服環境建立的坑是每個AI工程師必備的技能,我這邊就簡附我使用乾淨的ubuntu22.04 docker image從頭裝到尾有安裝的項目,照著安裝就可以訓練MiniCPM-V 2.6。
#起一個ubuntu容器
docker run -itd --gpus all --name minicpm_py3.10_training -m 32g ubuntu:22.04 bash
apt update && apt upgrade -y
apt install zip -y
apt install vim -y
apt install python3-pip -y
apt-get install wget -y
apt install libgl1-mesa-glx -y
apt-get install -y lsof
apt-get install gdb -y
apt-get install logrotate -y
apt-get install git -y
#ubuntu vi 中文亂碼解決
#加上 set encoding=utf-8
echo 'set encoding=utf-8' >> /etc/vim/vimrc
#時區安裝
DEBIAN_FRONTEND=noninteractive apt-get install -yq tzdata
TZ=Asia/Taipei
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
dpkg-reconfigure --frontend noninteractive tzdata
#miniconda安裝
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
source ~/.bashrc
conda create -n minicpm_env python=3.10 -y
conda activate minicpm_env
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
#註解掉requirements.txt裡的gradio相關套件
pip install -r requirements.txt
pip install bitsandbytes==0.44.1
pip install peft
pip install tensorboard
pip install gguf #轉gguf轉int4會用
pip install llmcompressor #模型量化使用, 可不用裝
#裝cuda
conda search -c nvidia cuda-nvcc #查詢版本對應
conda install -c nvidia cuda-nvcc==12.1.66 -y #跟著torch版本變動
conda install cuda-toolkit==12.1 -y #torch版本影響deepspeed版本, deepspeed版本影響cuda版本
#裝deepspeed compile好的版本
#https://github.com/AlongWY/deepspeed_wheels/releases/tag/v0.14.2 user pre-built deepspeed
wget https://github.com/AlongWY/deepspeed_wheels/releases/download/v0.14.2/deepspeed-0.14.2+cu121torch2.1-cp310-cp310-manylinux_2_24_x86_64.whl
pip install deepspeed-0.14.2+cu121torch2.1-cp310-cp310-manylinux_2_24_x86_64.whl
#驗deepspeed有沒有安裝成功
ds_report #這邊都要變成以下這樣才算過關
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
[WARNING] async_io requires the dev libaio .so object and headers but these were not found.
[WARNING] async_io: please install the libaio-dev package with apt
[WARNING] If libaio is already installed (perhaps from source), try setting the CFLAGS and LDFLAGS environment variables to where it can be found.
async_io ............... [YES] ...... [NO]
fused_adam ............. [YES] ...... [OKAY]
cpu_adam ............... [YES] ...... [OKAY]
cpu_adagrad ............ [YES] ...... [OKAY]
cpu_lion ............... [YES] ...... [OKAY]
#清理garbage
apt-get clean
rm -rf /var/lib/apt/lists/*
#清理pip cache
rm -rf ~/.cache
#清理conda缓存目錄中的下載的包文件、索引文件和不必要的緩存文件
conda clean --all -y
#包tar檔後壓縮
docker commit container_id minicpm_training:version5
docker save image_id minicpm_training:version5 | gzip > /tmp/minicpm_training_version5.tar.gz移轉Image到要訓練的GPU server使用docker load載入tar檔後,產生container的指令記得要加上share memory的設定(--shm-size=2G,大小可以自己決定),因為訓練中有用到NCCL套件,沒有加的話會報torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: -7)這種直觀看不出來跟share memory有關的錯….
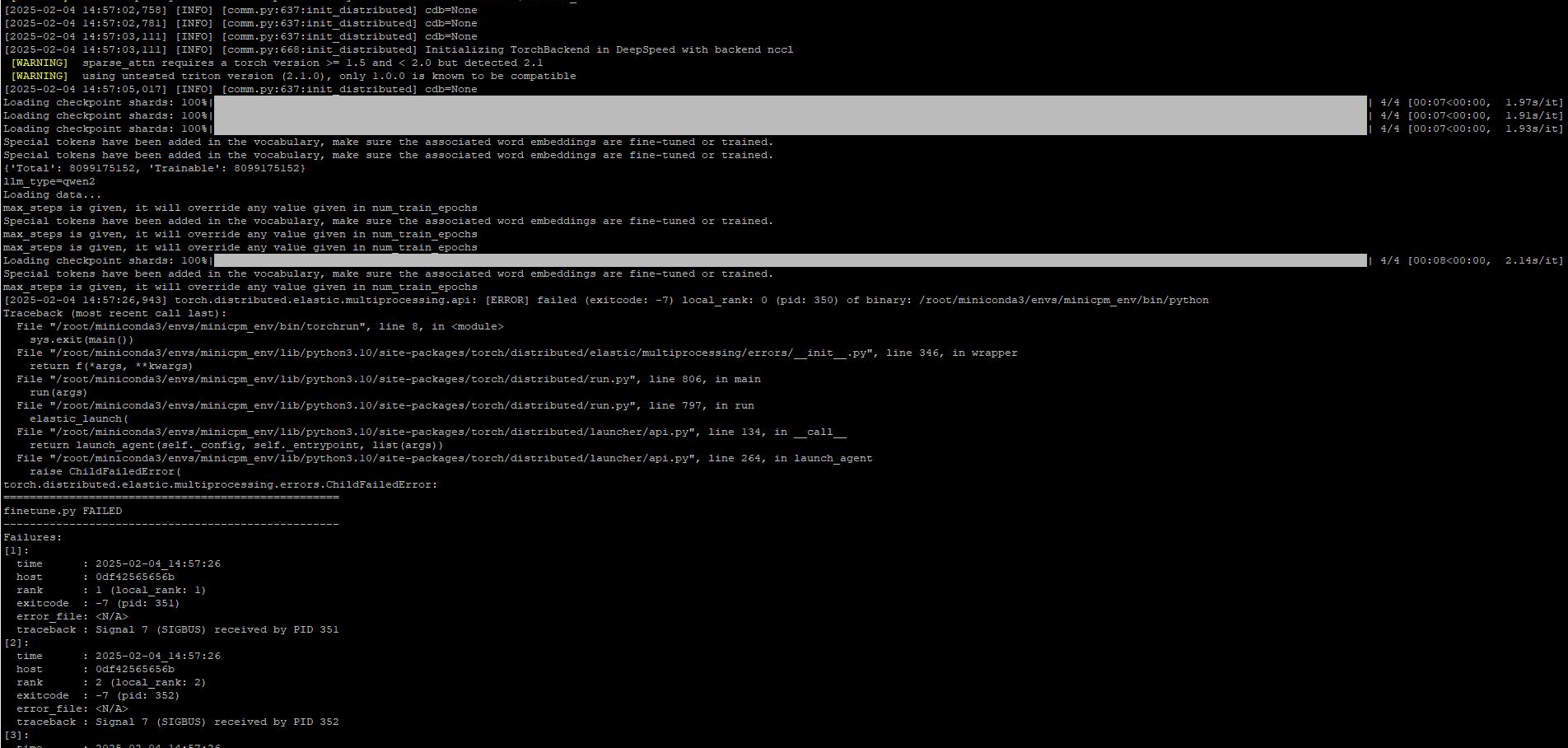
(四). 訓練資料準備
我們的目的,是要能夠輸入一張圖,請MiniCPM-V回傳我們希望取得的欄位,並且是格式化的回傳結果,好讓我們能夠依據格式化的key準確地取得對應的欄位值,若依據官方finetune上的資料sample code,我們可以改成類似像下面這樣,讓模型用標準json格式回結果:
[
{
"id": "0",
"image": "path/to/image_0.jpg",
"conversations": [
{
"role": "user",
"content": "<image>\n如果這是張高鐵票,請回傳乘車日期、起站、迄站、票面金額、票號"
},
{
"role": 'assistant",
"content": "{\"乘車日期\":\"2024-04-20\", \"起站\":\"台北\", \"迄站\":\"左營\", \"票面金額\":NT$1490, \"票號\":\"04-2-18-0-094-0498\"}"
}
]
}
]訓練資料每一張圖片都做這樣的標記格式,我這邊使用上每個類別是500張(因為我們是從PaddleOCR轉為MiniCPM-V使用,原PaddleOCR官方號稱單類別有500張即可有很好的效果)。prompt的撰寫上,因為我們不會知道輸入的是什麼樣的憑證,所以我的prompt開頭是"如果是xxx",這樣的方式可以讓模型自己去判斷這是什麼憑證(實驗到後面其實我們也發現模型的確可以針對圖片做正確的分類^ ^)。
(四). 模型訓練需要注意的參數講解/修改
官方模型全量finetune的shell檔已經寫好,路徑在這裡:
https://github.com/OpenBMB/MiniCPM-o/blob/main/finetune/finetune_ds.sh
但因為2025/01/13官方有改版,我看他們對finetune資料夾下的code都進行了更改使其支援MiniCPM-o,所以我這邊列出我網誌練2.6版使用的程式版本連結:
https://github.com/OpenBMB/MiniCPM-o/tree/2.6-sft
https://github.com/OpenBMB/MiniCPM-o/tree/8464c94a7b76615705e8a41b23ba3eb59de796b7/finetune
我們可以對這個檔案進行部分修改,調整部分參數以利我們進行模型finetune,我有調整到的參數簡列如下:
- GPUS_PER_NODE:調整GPU使用數量
- MODEL:pretrained model位置(因為公司的GPU Server無法連外網,我將模型先載下來放到local位置)
- DATA:訓練資料json檔
- EVAL:訓練過程中的測試json檔
- LLM_TYPE:在訓練不同版本模型時需要調整的參數,會影響模型訓練時前處理回傳的一些物件型態
- tune_vison:調整視覺模塊,我是要根據我的憑證辨識場景調整所以要開true
- tune_llm:調整大語言模型塊,我要求llm依據我要的格式回給我結果所以要開true
- max_slice_nums:圖片前處理時,模型要切成幾塊作處理,官方號稱1344*1344的image切9塊已有不錯的辨識率,我先不動
- max_steps:最多要練幾步,用預設的10000即可
- eval_steps:模型每多少步驗證一次,用預設的1000即可
- output_dir:checkpoint模型產出位置
- per_device_train_batch_size:模型訓練batchsize,我用NVIDIA RTX 6000 Ada測試,4卡開了cpu offloading後此參數可以開到7,8的話會OOM,但我的應用場景實測出來4的訓練效果最好
- save_steps:每幾步save出一個checkpoint
- save_total_limit:checkpoint只允許save最後幾個
- deepspeed:官方提供ds_config_zero2.json和ds_config_zero3.json兩個json設定檔,建議顯卡記憶體夠的話用ds_config_zero2.json,我使用ds_config_zero2.json後發現會OOM,將json檔內的cpu offloading打開後降低GPU memory usage即可訓練
- 前面我會加一行export CUDA_VISIBLE_DEVICES指定我要用的GPU index。
#!/bin/bash
export CUDA_VISIBLE_DEVICES=0,1,2,3
GPUS_PER_NODE=4
NNODES=1
NODE_RANK=0
MASTER_ADDR=localhost
MASTER_PORT=6001
MODEL="/MiniCPM-V/pretrained_model/MiniCPM-V-2_6"
# or openbmb/MiniCPM-V-2, openbmb/MiniCPM-Llama3-V-2_5
# ATTENTION: specify the path to your training data, which should be a json file consisting of a list of conversations.
# See the section for finetuning in README for more information.
DATA="/minicpm_dataset/train_data_done.json"
EVAL_DATA="/minicpm_dataset/eval_data_done.json"
LLM_TYPE="qwen2" # if use openbmb/MiniCPM-V-2, please set LLM_TYPE=minicpm, if use openbmb/MiniCPM-Llama3-V-2_5, please set LLM_TYPE="llama3"
MODEL_MAX_Length=2048 # if conduct multi-images sft, please set MODEL_MAX_Length=4096
DISTRIBUTED_ARGS="
--nproc_per_node $GPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT
"
torchrun $DISTRIBUTED_ARGS finetune.py \
--model_name_or_path $MODEL \
--llm_type $LLM_TYPE \
--data_path $DATA \
--eval_data_path $EVAL_DATA \
--remove_unused_columns false \
--label_names "labels" \
--prediction_loss_only false \
--bf16 true \
--bf16_full_eval true \
--fp16 false \
--fp16_full_eval false \
--do_train \
--do_eval \
--tune_vision true \
--tune_llm true \
--model_max_length $MODEL_MAX_Length \
--max_slice_nums 9 \
--max_steps 10000 \
--eval_steps 1000 \
--output_dir output/output_minicpmv26 \
--logging_dir output/output_minicpmv26 \
--logging_strategy "steps" \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "steps" \
--save_strategy "steps" \
--save_steps 2000 \
--save_total_limit 5 \
--learning_rate 1e-6 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--gradient_checkpointing true \
--deepspeed ds_config_zero2.json \
--report_to "tensorboard" 官方的finetune_ds.sh調整完後,我會再寫一個nohup的shell檔,執行後讓他在背景訓練寫log:
source ~/.zshrc
conda activate minicpm_env
nohup ./finetune_ds.sh &> train.log 2>&1 &然後訓練就可以開始了(V2.6版的忘記截圖,貼個V2.0版的代替,基本上是差不多的,差在V2.6 llm_type會顯示qwen2)
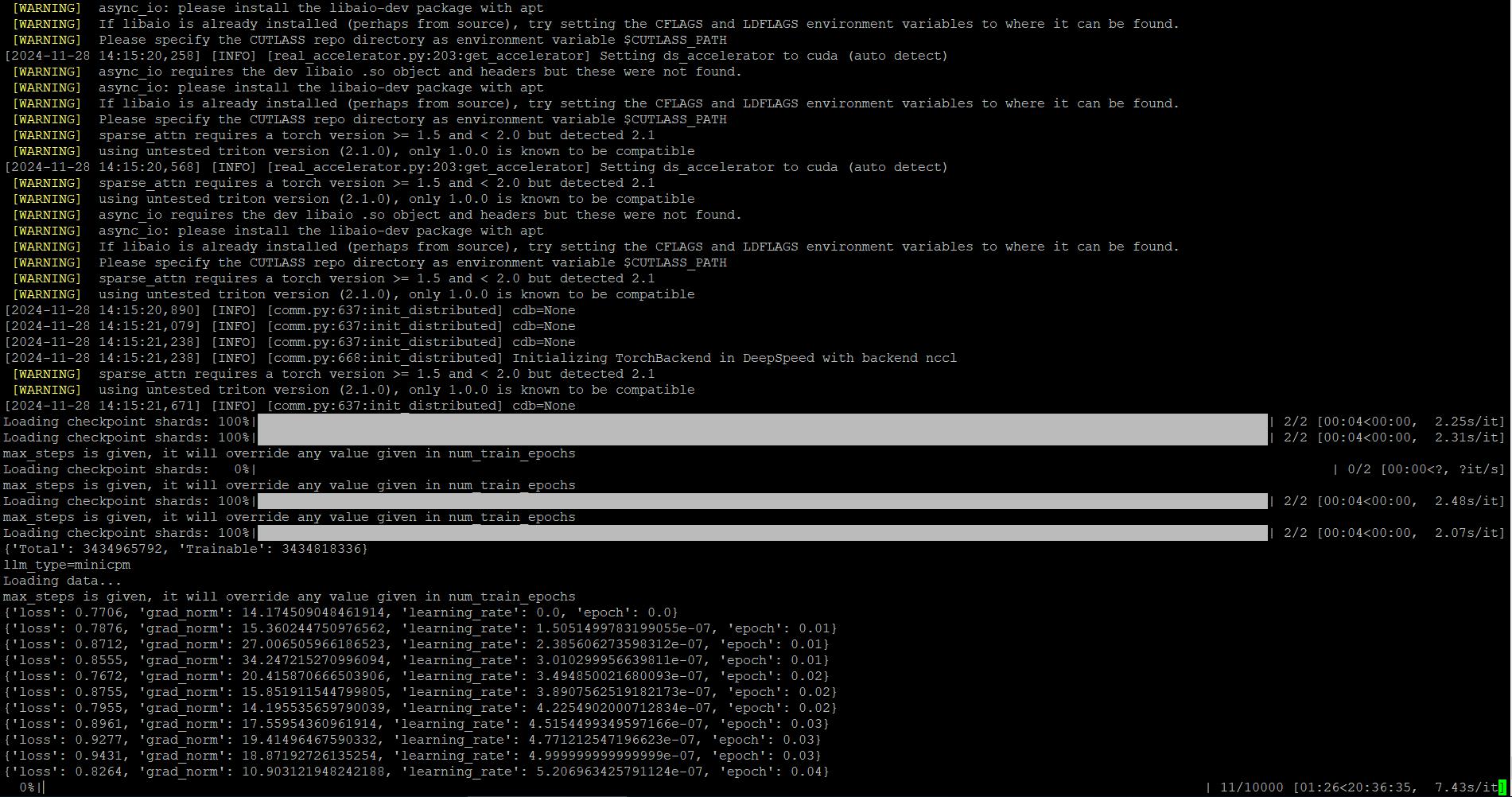
(五). 訓練完畢後的模型使用前調整
模型訓練完後的checkpoint內的模型檔案,你若直接寫code去load的話,會報MiniCPMVTokenizerFast object has no attribute image_processor的錯誤,看起來是官方在finetune過程中code沒有寫好導致模型產出時有缺檔https://github.com/OpenBMB/MiniCPM-o/issues/408,我這邊的解決方法是直接將原pretrained model資料夾中的檔案複製過去即可。
https://huggingface.co/openbmb/MiniCPM-V-2_6/blob/main/preprocessor_config.json
https://huggingface.co/openbmb/MiniCPM-V-2_6/blob/main/processing_minicpmv.py
https://huggingface.co/openbmb/MiniCPM-V-2_6/blob/main/image_processing_minicpmv.py

(六). 模型準確率、Transformer架構與vLLM架構推論速度
訓練的step中得到的checkpoint模型,原則上要在一定step數以上,模型回給你的結果才會照你的prompt中寫的json格式回,太前面step的模型容易不照格式回給你,以我前面寫的範例中,我都是直接取用checkpoint-10000的模型來做驗證使用,得到的結果都是我要的json格式。
簡列我的訓練結果如下,我是依憑證的欄位正確率與憑證正確率(單一憑證辨識全對的比率)來做驗證,辨識憑證數量基本上都有50張以上,欄位數不一:
| 欄位正確率 | 憑證正確率 | |
|---|---|---|
| 憑證A | 99.66% | 98% |
| 憑證B | 98.8% | 94% |
| 憑證C | 98.57% | 92% |
| 憑證D | 99.71% | 97.97% |
| 憑證E | 99% | 94% |
| 憑證F | 99.65% | 98.29% |
和之前的PaddleOCR正確率比較,憑證正確率基本上都拉到九成以上,這對user來說爽度是很足夠的,因為這代表辨識出來的結果幾乎都會是對的^ ^。
推論速度依照官方說明使用vllm會最快:

我選用0.6.5版本,官方號稱速度提升不少https://news.miracleplus.com/share_link/39977,最後與Transformer架構比較數據如下:
基本上用vLLM讓整體推論速度提升12%以上,單張憑證推論速度穩穩的壓到3秒以下,憑證推論速度不一是因為有的憑證需要辨識的欄位比較多一點。
| Transformer框架推論速度 | vLLM框架(0.6.5)推論速度 | vLLM框架使用後速度提升 | |
|---|---|---|---|
| 憑證A | 2.46 | 2.12 | ↑ 13.8% |
| 憑證B | 2.235 | 1.916 | ↑ 14.2% |
| 憑證C | 3.089 | 2.668 | ↑ 13.6% |
| 憑證D | 2.992 | 2.623 | ↑ 12.3% |
| 憑證E | 2.354 | 2.035 | ↑ 13.5% |
| 憑證F | 2.174 | 1.81 | ↑ 16.7% |
最後,我和管GPU機器的同事有做進一步的速度測試,發現CPU時脈會大大影響推論的速度,我們在猜應該是跟GPU推論前程式會做圖片切割前處理的關係,這段使用的是CPU,未來若公司可以採購推論用的機器,也許速度上可以進一步的提升。