1.爬蟲基礎工
2.抓取<title></title>
3.抓出標籤內的文字
1.爬蟲基礎工
目標位置:https://www.yannick.com.tw/shop/productlist?Item1=01&Item2=0102&Item3=010203
#目標位置:https://www.yannick.com.tw/shop/productlist?Item1=01&Item2=0102&Item3=010203
import requests
from bs4 import BeautifulSoup
resp = requests.get('https://www.yannick.com.tw/shop/productlist?Item1=01&Item2=0102&Item3=010203')
print(resp) #<Response [200]> 請求成功回200,請求失敗回404
soup = BeautifulSoup(resp.text, 'html.parser')
#整張HTML
print(soup)
# 輸出排版後的 HTML 程式碼
print(soup.prettify())整張html已被我們抓回來了。

2.抓取<title></title>
import requests
from bs4 import BeautifulSoup
resp = requests.get('https://www.yannick.com.tw/shop/productlist?Item1=01&Item2=0102&Item3=010203')
#print(resp) #<Response [200]>
soup = BeautifulSoup(resp.text, 'html.parser')
#整張HTML
#print(soup)
# 輸出排版後的 HTML 程式碼
#print(soup.prettify())
# 網頁標題 HTML 標籤
title_tag = soup.title
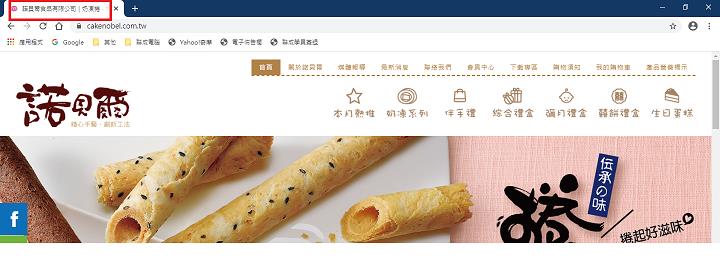
print(title_tag)#印出<title>食品有限公司</title>
# 網頁的標題文字
print(title_tag.string) #印出諾貝爾食品有限公司3.抓出標籤內的文字
import requests
from bs4 import BeautifulSoup
resp = requests.get('https://jwlin.github.io/py-scraping-analysis-book/ch1/connect.html')
print(resp.status_code)#查詢狀態碼 200成功 404 失敗(找不到)
soup = BeautifulSoup(resp.text, 'html.parser')
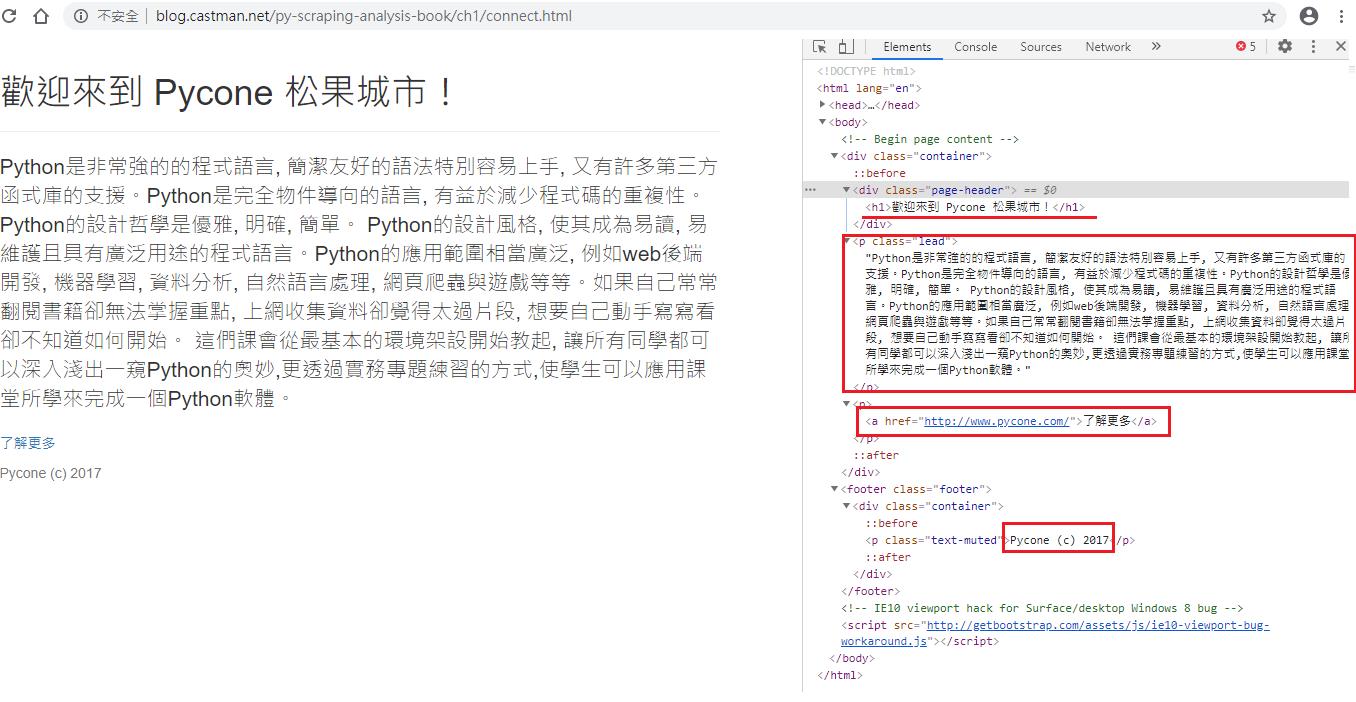
geth1 = soup.find('h1').text #抓取<h1></h1>
getp = soup.find('p').text #抓取<p></p>
geta = soup.find('a').text #抓取<a></a>
getfooter = soup.find('footer').text #抓取<footer></footer>
print(geth1)
print(getp)
print(geta)
print(getfooter)

參考文獻:<姆斯>Python大數據特訓班 <碁峰> 文淵閣工作室 9789864768561
Yiru@Studio - 關於我 - 意如