1.抓取網站第一個<h3></h3>標籤
2.使用for迴圈抓取所有的<h3></h3>
目標網址: https://www.dotblogs.com.tw/YiruAtStudio
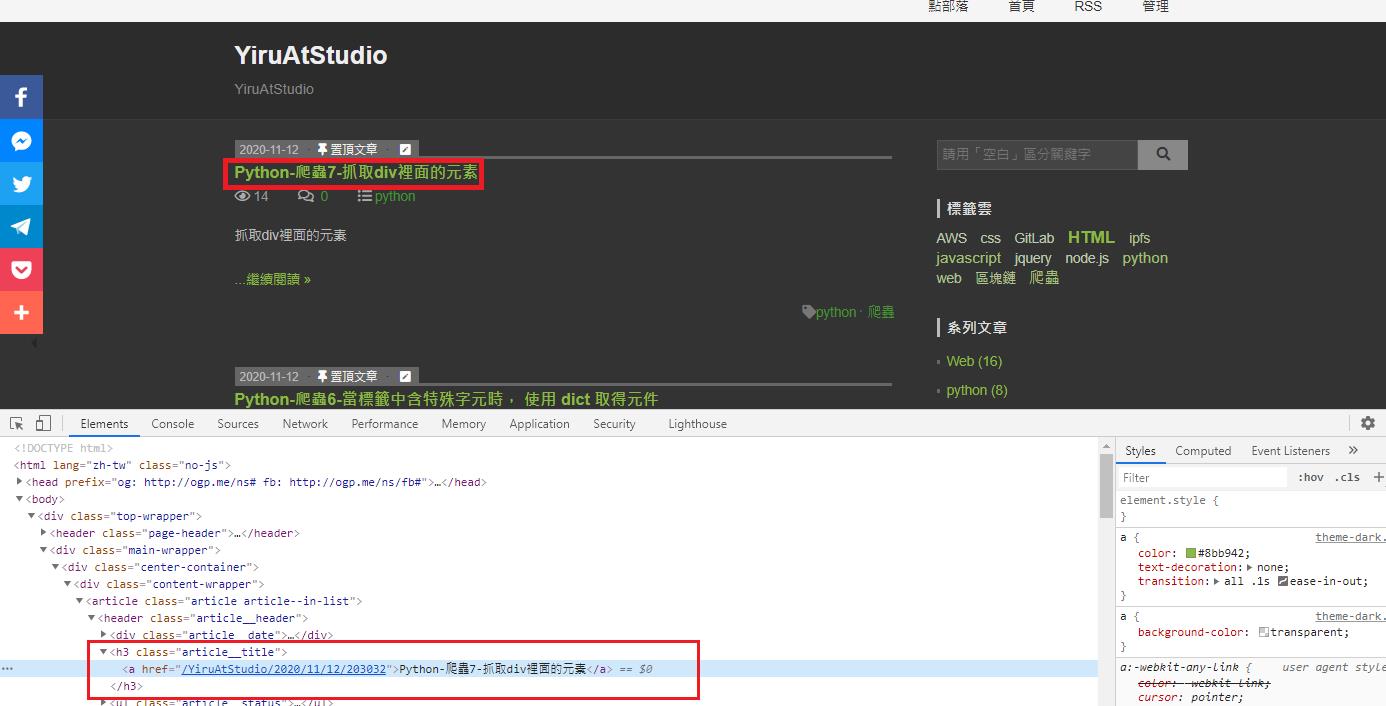
1.抓取網站第一個<h3></h3>標籤
import requests
from bs4 import BeautifulSoup
def main():
resp = requests.get('https://www.dotblogs.com.tw/YiruAtStudio')
soup = BeautifulSoup(resp.text, 'html.parser')
# 取得第一篇 blog (h3)
print(soup.find('h3'))
print(soup.h3) # 與上一行相等
# 取得第一篇 blog 主標題(只取文字)
print(soup.h3.text)
print(soup.h3.a.text)# 與上一行相等
print(soup.h3.a.string)
if __name__ == '__main__':
main()
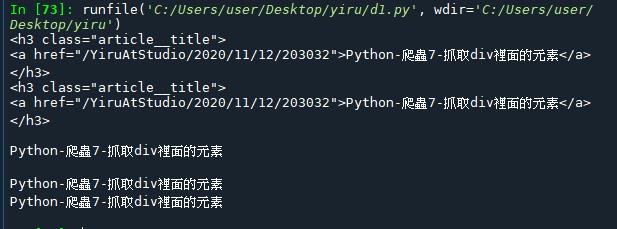
2.使用for迴圈抓取所有的<h3></h3>
#把所有的h3都讀出來
import requests
from bs4 import BeautifulSoup
def main():
resp = requests.get('https://www.dotblogs.com.tw/YiruAtStudio')
soup = BeautifulSoup(resp.text, 'html.parser')
# 取得所有 blog 主標題, 使用 tag
main_titles = soup.find_all('h3')
for title in main_titles:
print(title.a.text)
if __name__ == '__main__':
main()
Yiru@Studio - 關於我 - 意如