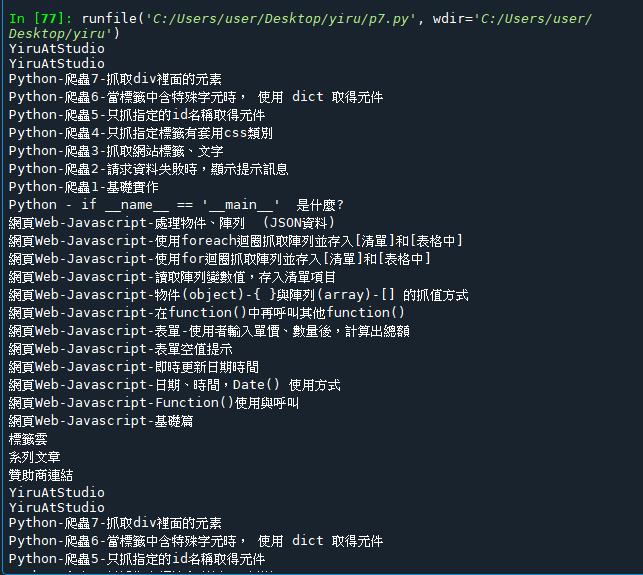
找出所有 'h' 開頭的標題文字
目標網址:https://www.dotblogs.com.tw/YiruAtStudio
import requests
import re
from bs4 import BeautifulSoup
def main():
resp = requests.get('https://www.dotblogs.com.tw/YiruAtStudio')
soup = BeautifulSoup(resp.text, 'html.parser')
# 找出所有 'h' 開頭的標題文字
titles = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
for title in titles:
print(title.text.strip()) #strip()去除頭尾空白或斷行字符
# 利用 regex 找出所有 'h' 開頭的標題文字
for title in soup.find_all(re.compile('h[1-6]')):
print(title.text.strip())
if __name__ == '__main__':
main()
Yiru@Studio - 關於我 - 意如