文、意如
1. 題目說明:
請開啟PYD02.py檔案,依下列題意進行作答,使輸出值符合題意要求。作答完成請另存新檔為PYA02.py再進行評分。
2. 設計說明:
請撰寫一程式,爬取https://www.codejudger.com/target/5201.html,程式須回傳下列資訊:
讓使用者輸入欲搜尋的字詞,再輸出字詞的搜尋結果及字詞出現的次數。
3. 輸入輸出:
輸入說明
爬取網頁
搜尋的字詞
輸出說明
字詞的搜尋結果
字詞出現的次數
範例輸入及輸出
請輸入欲搜尋的字串 : TQC+
TQC+ 搜尋成功
TQC+ 出現 23 次題目:
# 載入模組
import ___
import ___
url = '___'
# 使用 GET 請求
htmlfile = requests.___(___)
# 驗證HTTP Status Code
if htmlfile.status_code == ___:
# 欲搜尋的字串
___ = input("請輸入欲搜尋的字串 : ")
___ = re.findall(___, htmlfile.text)
if ___ in htmlfile.text:
print(___, "搜尋成功")
print(___, "出現 %d 次" % len(___))
else:
print(___, "搜尋失敗")
print(___, "出現 0 次")
else:
print("網頁下載失敗")參考解答:
# 載入模組
import requests
import re
url = 'http://tqc.codejudger.com:3000/target/5201.html'
# 使用 GET 請求
htmlfile = requests.get(url)
# 驗證HTTP Status Code
if htmlfile.status_code == 200:
# 欲搜尋的字串
key = input("請輸入欲搜尋的字串 : ")
datas = re.findall(key, htmlfile.text)
if key in htmlfile.text:
print(key, "搜尋成功")
print(key, "出現 %d 次" % len(datas))
else:
print(key, "搜尋失敗")
print(key, "出現 0 次")
else:
print("網頁下載失敗")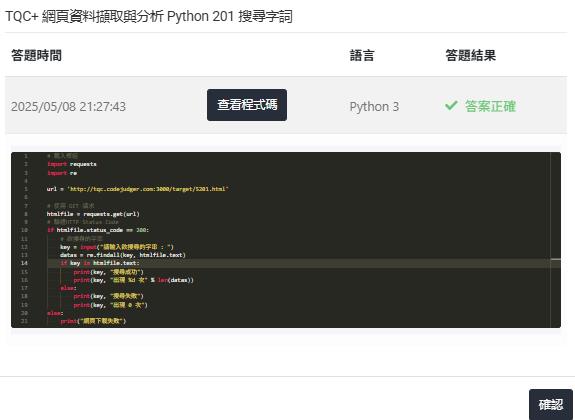
參考解答2:
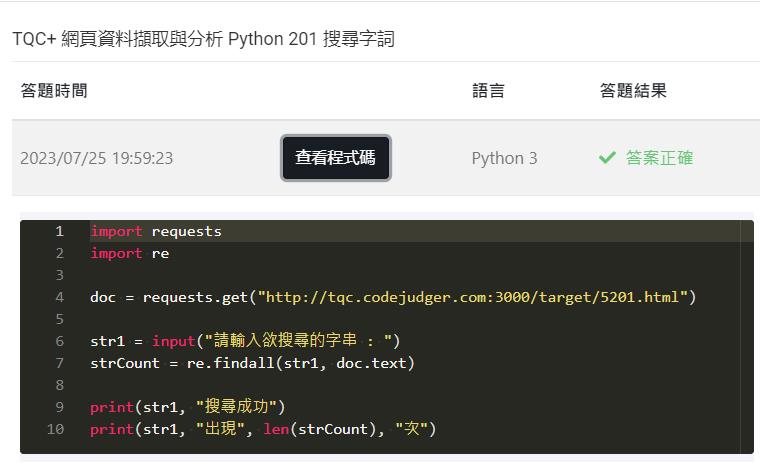
# 匯入 requests 模組用於發送 HTTP 請求
import requests
# 匯入 re 模組用於正規表達式處理
import re
# 使用 requests.get() 方法向指定 URL 發送 GET 請求,並將回應內容儲存在 'doc' 變數中
doc = requests.get("http://tqc.codejudger.com:3000/target/5201.html")
# 詢問使用者輸入欲搜尋的字串,並將輸入值儲存在 'str1' 變數中
str1 = input("請輸入欲搜尋的字串 : ")
# 使用 re.findall() 方法在 'doc.text' 中尋找所有符合 'str1' 的字串,並儲存在 'strCount' 變數中
strCount = re.findall(str1, doc.text)
# 印出搜尋成功的訊息,顯示使用者輸入的搜尋字串
print(str1, "搜尋成功")
# 印出符合搜尋字串的次數
print(str1, "出現", len(strCount), "次")
Yiru@Studio - 關於我 - 意如