文、意如
題目:
- 請撰寫程式讀取寶可夢資料檔pokemon.csv,並利用整體學習(Ensemble learning)進行分類及預測。資料檔的欄位說明如下:
| 欄位名稱 | 說明 | 欄位名稱 | 說明 |
|---|---|---|---|
| Number* | 編號 | Attack | 攻擊力 |
| Name* | 名稱 | Defense | 防禦力 |
| Type1* | 第一屬性 | SpecialAtk | 特殊攻擊 |
| Type2* | 第二屬性 | SpecialDef | 特殊防禦 |
| Total | 能力值加總 | Speed | 速度 |
| HP | 血量 | Generation* | 世代編號 |
*備註:欄位有標示星號(*)者為類別變數,其餘為數值變數。 2. 取出兩個特徵欄位Defense, SpecialAtk以及預測欄位Type1為資料集,將資料集分為訓練集與測試集,其中測試集占20%。 3. 針對訓練集的特徵欄位進行標準化(Standardization)。 4. 建立四個分類器:
a. 隨機森林(RandomForest)。
b. k-近鄰(kNN)。
c. 線性支援向量分類器(SVC)。
d. 投票(Voting)分類器。 5. 利用k折交叉驗證(k-fold cross validation)對這特徵欄位進行Type1分類,計算上述四個分類器對訓練集的準確度(Accuracy)平均值,並分別對測試集進行分類預測以及計算準確度。 6. 輸入一個未知寶可夢的欄位值,利用投票分類器預測其分類。
(三)、 請依序回答下列問題:
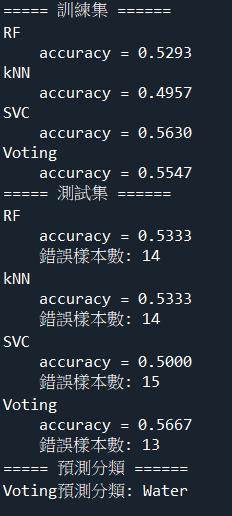
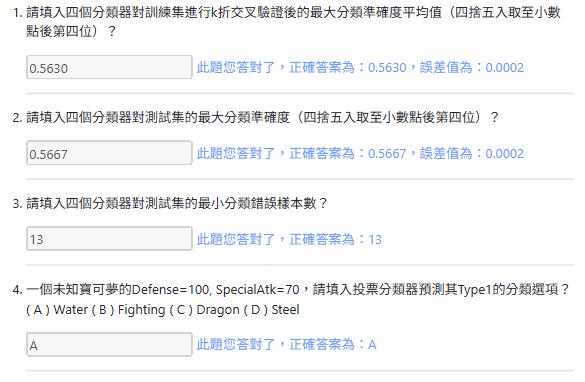
- 請填入四個分類器對訓練集進行k折交叉驗證後的最大分類準確度平均值(四捨五入取至小數點後第四位)?
- 請填入四個分類器對測試集的最大分類準確度(四捨五入取至小數點後第四位)?
- 請填入四個分類器對測試集的最小分類錯誤樣本數?
- 一個未知寶可夢的Defense=100, SpecialAtk=70,請填入投票分類器預測其Type1的分類選項? ( A ) Water ( B ) Fighting ( C ) Dragon ( D ) Steel
PYD03.py
# #############################################################################
# 本題參數設定,請勿更改
seed = 0 # 亂數種子數
# #############################################################################
import pandas as pd
# 載入寶可夢資料
# TODO
# 取出目標欄位
X = #TODO 特徵欄位
y = #TODO Type1 欄位
# 編碼 Type1
from sklearn import preprocessing
# TODO
# 切分訓練集、測試集,除以下參數設定外,其餘為預設值
# #########################################################################
# X, y, test_size=0.2, random_state=seed
# #########################################################################
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =
# 特徵標準化
from sklearn.preprocessing import StandardScaler
# TODO
# 訓練集
# 分別建立 RandomForest, kNN, SVC, Voting,除以下參數設定外,其餘為預設值
# #############################################################################
# RandomForest: n_estimators=10, random_state=seed
# kNN: n_neighbors=4
# SVC: gamma=.1, kernel='rbf', probability=True
# Voting: estimators=[('RF', clf1), ('kNN', clf2), ('SVC', clf3)],
# voting='hard', n_jobs=-1
# #############################################################################
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
# TODO
# 建立函式 kfold_cross_validation() 執行 k 折交叉驗證,並回傳準確度的平均值
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import KFold, cross_val_score
def kfold_cross_validation(scalar, model):
""" 函式描述:執行 k 折交叉驗證
參數:
scalar (StandardScaler):標準化適配的結果
model: 機器學習模型
回傳:
k 折交叉驗證的準確度(accuracy)平均值
"""
# 建立管線,用來進行(標準化 -> 機器學習模型)
pipeline = #TODO
# 產生 k 折交叉驗證,除以下參數設定外,其餘為預設值
# #########################################################################
# n_splits=5, shuffle=True, random_state=seed
# #########################################################################
kf = #TODO
# 執行 k 折交叉驗證
# #########################################################################
# pipeline, X_train, y_train, cv=kf, scoring='accuracy', n_jobs=-1
# #########################################################################
cv_result = #TODO
return #TODO
# 利用 kfold_cross_validation(),分別讓分類器執行 k 折交叉驗證,計算準確度(accuracy)
#TODO
# #############################################################################
# 利用訓練集的標準化結果,針對測試集進行標準化
# TODO
# 上述分類器針對測試集進行預測,並計算分類錯誤的個數與準確度
from sklearn.metrics import accuracy_score
# TODO
# #############################################################################
# 分別利用上述分類器預測分類
print("===== 預測分類 ======")
# TODO
參考解答:
# #############################################################################
# 本題參數設定,請勿更改
seed = 0 # 亂數種子數
# #############################################################################
import pandas as pd
# 載入寶可夢資料
data = pd.read_csv('pokemon.csv')
# 取出目標欄位
X = data.loc[:, ['Defense', 'SpecialAtk']]
y = data.loc[:, 'Type1']
# 編碼 Type1
from sklearn import preprocessing
le = preprocessing.LabelEncoder().fit(y)
y = le.transform(y)
# 切分訓練集、測試集,除以下參數設定外,其餘為預設值
# #########################################################################
# X, y, test_size=0.2, random_state=seed
# #########################################################################
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=seed)
# 特徵標準化
from sklearn.preprocessing import StandardScaler
scalar = StandardScaler().fit(X_train)
X_train = scalar.transform(X_train)
# 訓練集
# 分別建立 RandomForest, kNN, SVC, Voting,除以下參數設定外,其餘為預設值
# #############################################################################
# RandomForest: n_estimators=10, random_state=seed
# kNN: n_neighbors=4
# SVC: gamma=.1, kernel='rbf', probability=True
# Voting: estimators=[('RF', clf1), ('kNN', clf2), ('SVC', clf3)],
# voting='hard', n_jobs=-1
# #############################################################################
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
clf1 = RandomForestClassifier(n_estimators=10, random_state=seed)
clf2 = KNeighborsClassifier(n_neighbors=4)
clf3 = SVC(gamma=.1, kernel='rbf', probability=True)
vclf = VotingClassifier(estimators=[('RF', clf1), ('kNN', clf2), ('SVC', clf3)],
voting='hard', n_jobs=-1)
name_list = ['RF', 'kNN', 'SVC', 'Voting']
model_list = [clf1, clf2, clf3, vclf]
# 建立函式 kfold_cross_validation() 執行 k 折交叉驗證,並回傳準確度的平均值
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import KFold, cross_val_score
def kfold_cross_validation(scalar, model):
""" 函式描述:執行 k 折交叉驗證
參數:
scalar (StandardScaler):標準化適配的結果
model: 機器學習模型
回傳:
k 折交叉驗證的準確度(accuracy)平均值
"""
# 建立管線,用來進行(標準化 -> 機器學習模型)
pipeline = make_pipeline(scalar, model)
# 產生 k 折交叉驗證,除以下參數設定外,其餘為預設值
# #########################################################################
# n_splits=5, shuffle=True, random_state=seed
# #########################################################################
kf = KFold(n_splits=5, shuffle=True, random_state=seed)
# 執行 k 折交叉驗證
# #########################################################################
# pipeline, X_train, y_train, cv=kf, scoring='accuracy', n_jobs=-1
# #########################################################################
cv_result = cross_val_score(pipeline, X_train, y_train, cv=kf, scoring='accuracy', n_jobs=-1)
return cv_result
# 利用 kfold_cross_validation(),分別讓分類器執行 k 折交叉驗證,計算準確度(accuracy)
print("===== 訓練集 ======")
for name, model in zip(name_list, model_list):
model.fit(X_train, y_train)
accuracy = kfold_cross_validation(scalar, model)
print(f"{name}\n\t"
f"accuracy = {accuracy.mean():.4f}")
# #############################################################################
# 利用訓練集的標準化結果,針對測試集進行標準化
X_test = scalar.transform(X_test)
# 上述分類器針對測試集進行預測,並計算分類錯誤的個數與準確度
from sklearn.metrics import accuracy_score
print("===== 測試集 ======")
for name, model in zip(name_list, model_list):
accuracy = accuracy_score(y_test, model.predict(X_test))
error_num = (y_test!= model.predict(X_test)).sum()
print(f"{name}\n\t"
f"accuracy = {accuracy:.4f}\n\t"
f"錯誤樣本數: {error_num}")
# #############################################################################
# 分別利用上述分類器預測分類
print("===== 預測分類 ======")
inp = scalar.transform([[100, 70]])
inp_pred = vclf.predict(inp)
print(f"Voting預測分類: {le.inverse_transform(inp_pred)[0]}")程式解析:
# #############################################################################
# 本題參數設定,請勿更改
seed = 0 # 設定亂數種子,確保每次執行結果一致
# #############################################################################
import pandas as pd
# 載入寶可夢資料集
data = pd.read_csv('pokemon.csv')
# 取出兩個特徵欄位作為訓練資料(防禦力與特殊攻擊)
X = data.loc[:, ['Defense', 'SpecialAtk']]
# 取出目標欄位 Type1 作為分類標籤
y = data.loc[:, 'Type1']
# 將 Type1 進行編碼(字串轉為數字),以利機器學習處理
from sklearn import preprocessing
le = preprocessing.LabelEncoder().fit(y)
y = le.transform(y)
# 將資料切分為訓練集與測試集,測試集佔 20%,設定亂數種子以固定切法
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=seed)
# 特徵標準化:將訓練資料轉換為標準常態分布(平均值為0,標準差為1)
from sklearn.preprocessing import StandardScaler
scalar = StandardScaler().fit(X_train) # 用訓練資料來計算平均與標準差
X_train = scalar.transform(X_train) # 對訓練資料進行轉換
# 載入三種分類器:隨機森林、KNN、SVC,並設定相關參數
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
clf1 = RandomForestClassifier(n_estimators=10, random_state=seed) # 隨機森林
clf2 = KNeighborsClassifier(n_neighbors=4) # K 近鄰
clf3 = SVC(gamma=.1, kernel='rbf', probability=True) # 支援向量機
# 建立投票分類器(整合三個模型),使用「硬投票」
vclf = VotingClassifier(
estimators=[('RF', clf1), ('kNN', clf2), ('SVC', clf3)],
voting='hard', n_jobs=-1
)
# 建立模型名稱與模型物件的清單
name_list = ['RF', 'kNN', 'SVC', 'Voting']
model_list = [clf1, clf2, clf3, vclf]
# 匯入交叉驗證相關套件
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import KFold, cross_val_score
# 定義函式:使用 KFold 執行 k 折交叉驗證,回傳每折的準確度
def kfold_cross_validation(scalar, model):
"""
執行 K 折交叉驗證,並回傳每折的準確度陣列
scalar: 已擬合好的標準化物件
model: 欲驗證的機器學習模型
"""
pipeline = make_pipeline(scalar, model) # 將標準化與模型串在一起,形成處理流程
kf = KFold(n_splits=5, shuffle=True, random_state=seed) # 5折交叉驗證
cv_result = cross_val_score(pipeline, X_train, y_train, cv=kf, scoring='accuracy', n_jobs=-1)
return cv_result # 回傳每一折的準確度
# ============================== 訓練集評估 ==============================
print("===== 訓練集 ======")
for name, model in zip(name_list, model_list):
model.fit(X_train, y_train) # 用訓練資料訓練模型
accuracy = kfold_cross_validation(scalar, model) # 執行交叉驗證
print(f"{name}\n\taccuracy = {accuracy.mean():.4f}") # 顯示平均準確度
# ============================== 測試集評估 ==============================
# 將測試集依照訓練集的標準進行標準化
X_test = scalar.transform(X_test)
# 匯入準確度計算模組
from sklearn.metrics import accuracy_score
print("===== 測試集 ======")
for name, model in zip(name_list, model_list):
accuracy = accuracy_score(y_test, model.predict(X_test)) # 計算準確度
error_num = (y_test != model.predict(X_test)).sum() # 計算錯誤預測數量
print(f"{name}\n\taccuracy = {accuracy:.4f}\n\t錯誤樣本數: {error_num}")
# ============================== 實際預測 ==============================
print("===== 預測分類 ======")
inp = scalar.transform([[100, 70]]) # 標準化預測資料
inp_pred = vclf.predict(inp) # 使用投票模型預測分類
print(f"Voting預測分類: {le.inverse_transform(inp_pred)[0]}") # 將編碼結果還原為原始分類名稱
Yiru@Studio - 關於我 - 意如