文、意如
首先建立一個文字檔,例如: threads_raw.txt
請按照以下步驟操作,這就是「手動採集」過程:
打開瀏覽器:進入 Threads 網頁版。
搜尋關鍵字:在搜尋框輸入你想分析的主題(例如:天主教、育幼院、或公益)。
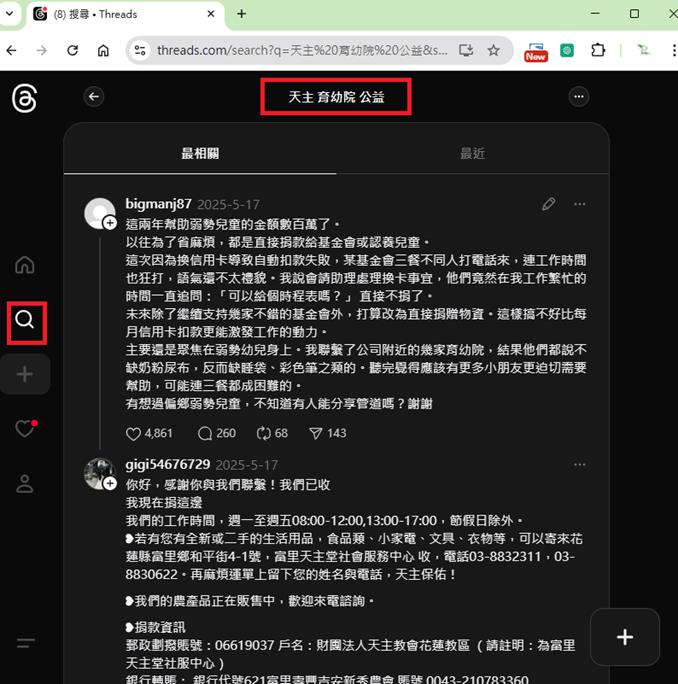
往下捲動頁面,讓它跑出幾十條甚至上百條貼文。
全選複製:
在網頁任何地方點一下,按Ctrl + A (全選)。
接著按 Ctrl + C (複製)。
貼上存檔:
在你的電腦(跟 Python 程式碼同一個資料夾)建立一個新的記事本檔案。
檔名取為 threads_raw.txt。
直接 Ctrl + V (貼上)。
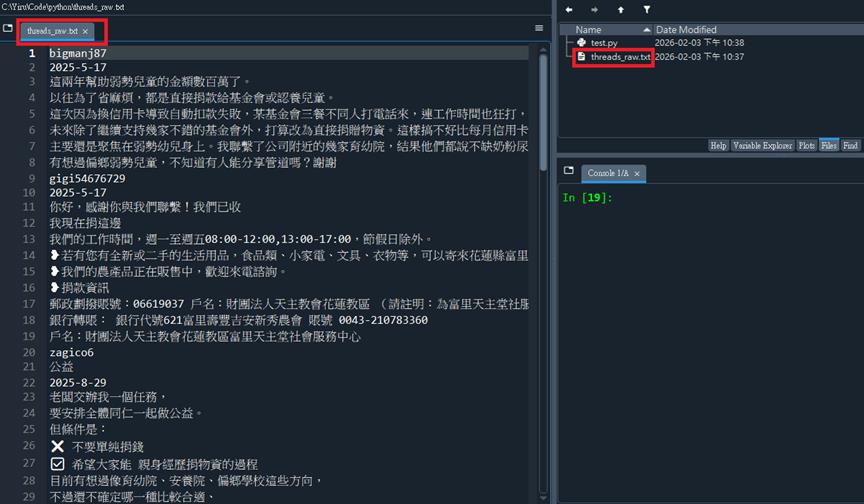
裡面看起來會很亂嗎?
會的! 裡面會有一堆帳號名稱、時間、讚數、回覆按鈕、甚至是廣告。
但請放心,這就是為什麼我們需要 Python。
接下來我們寫一段邏輯,就像一個「濾網」,幫你把那些沒用的雜訊(讚數、時間、法律條款)通通濾掉,只留下真正的貼文內容。
程式碼:如果遇到找不到套件時,請自行下載
下載指令: pip install 套件名稱
程式碼:test.py
# 導入 jieba 斷詞套件:這是中文自然語言處理(NLP)最常用的工具
import jieba
# 1. 讀取你從 Threads 手動採集並存放的原始文字檔案
# 使用 'r' (read) 模式開啟,並指定 utf-8 編碼以正確讀取中文繁體字
with open('threads_raw.txt', 'r', encoding='utf-8') as f:
content = f.read()
# 2. 【核心步驟】自定義字典:加入基金會的核心詞彙
# 這是為了避免 jieba 把「育幼院」切成「育幼」、「院」,或是把「天主」切開
# 確保這些專有名詞在後續的文字雲中能以「完整型態」出現,保留最強的品牌力
jieba.add_word("天主")
jieba.add_word("育幼院")
jieba.add_word("公益")
# 3. 執行精確模式斷詞
# lcut 會直接將讀取的長文本切開,並回傳成一個 Python 的列表 (List)
words = jieba.lcut(content)
# 4. 數據清洗與過濾邏輯
# 使用列表推導式篩選詞彙:
# (1) len(w) > 1:過濾掉單個字(如:的、我、了、在),這些字通常沒有分析意義
# (2) 過濾掉標點符號與空白,只留下真正具備「社會關懷含義」的關鍵字
meaningful_words = [w for w in words if len(w) > 1 and w.strip()]
# 5. 輸出分析結果摘要
# len(meaningful_words) 會告訴你經過濾後,我們最終提煉出了多少個「純金詞彙」
print(f"分析完成!我們從你的資料中提取了 {len(meaningful_words)} 個有意義的詞彙。")
# 6. 印出完整的詞彙清單
# 使用 ", ".join() 將列表中的 603 個詞串聯起來,中間用逗號隔開,方便閱讀檢查
print(f"--- 總計 {len(meaningful_words)} 個完整詞彙清單 ---")
print(", ".join(meaningful_words))
執行結果:
當我們執行這段「濾網」程式碼後,神奇的事情發生了。那些原本夾雜在帳號 ID 和時間戳記裡的數位碎片,被重新排列組合成了一幅清晰的社會圖譜:
分析完成!我們從你的資料中提取了 603 個有意義的詞彙。
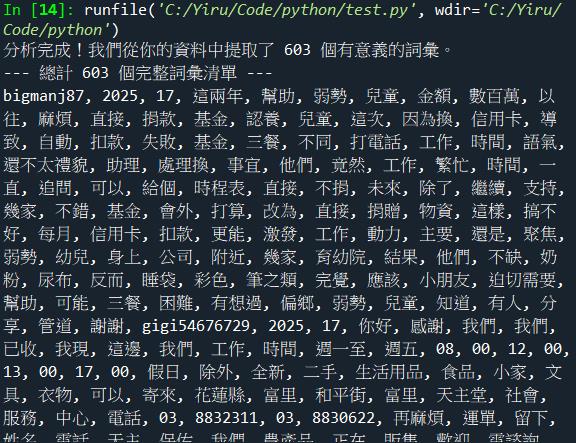
這代表在 Threads 這個看似「廢文」聚集地的表面下,潛藏著巨大的公益關注這不僅是 603 個數據點,更是 603 個潛在的共鳴與支持。
文字雲視覺化 —— 讓數據說話
先把剛剛提取到的603個數據,複製到一個word603.txt文字檔。
程式碼範例:
# 導入 pyecharts 的配置選項,用於設定標題、顏色等視覺效果
from pyecharts import options as opts
# 導入 pyecharts 的文字雲組件,這是生成 HTML 動態雲圖的核心工具
from pyecharts.charts import WordCloud
# 導入 jieba 斷詞套件,負責將長篇大論的中文切開,變成一個個有意義的詞彙
import jieba
# 導入 Counter 工具,用來自動統計每個詞彙出現的次數(也就是詞頻)
from collections import Counter
# 1. 讀取你辛苦採集並精煉後的 603 個詞彙原始檔案
# 使用 utf-8 編碼讀取 word603.txt,確保繁體中文不會變成亂碼
with open('word603.txt', 'r', encoding='utf-8') as f:
raw_data = f.read()
# 2. 進行數據清洗與二次精煉
# 使用 jieba.cut 將文本切開
# [w for w in ...] 是 Python 的列表推導式,邏輯是:
# 只要詞彙長度大於 1(過濾掉「的、了」等廢詞)且不是空白,就留下來
meaningful_words = [w for w in jieba.cut(raw_data) if len(w) > 1 and w.strip()]
# 3. 核心統計:計算每個關鍵字出現的頻率
# 這一點非常重要,因為出現次數越多的詞(如:育幼院),在雲圖中就會長得越大
word_counts = Counter(meaningful_words)
# 4. 格式轉換:將統計結果轉為 pyecharts 認得的列表格式
# 將字典格式轉成 [(詞, 數量), (詞, 數量)] 的配對清單
word_data = [(word, count) for word, count in word_counts.items()]
# 5. 建立文字雲物件並配置參數
c = (
# 初始化文字雲圖表
WordCloud()
# 新增數據內容
.add(
"", # 系列名稱(這裡留空即可)
word_data, # 放入我們剛才準備好的詞頻數據
word_size_range=[20, 100], # 設定字體大小:最小 20 像素,最大 100 像素
shape="star" # 設定形狀為星形
)
# 設定全域配置,例如幫這張圖加上一個專業的標題
.set_global_opts(
title_opts=opts.TitleOpts(title="Threads 社會關注度數據洞察")
)
)
# 6. 渲染結果並生成 HTML 檔案
# 這會在你當前的資料夾下產出一個網頁檔,可以用瀏覽器直接開啟觀看動態效果
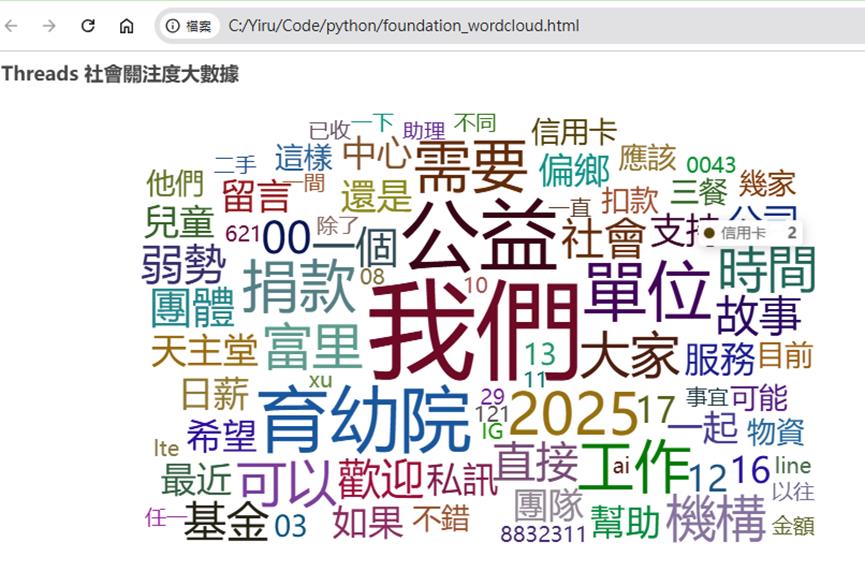
c.render("foundation_wordcloud.html")
# 7. 在終端機印出完成訊息,方便確認執行進度
print(f"已成功處理 {len(meaningful_words)} 個核心詞彙。")
print("請打開資料夾中的 'foundation_wordcloud.html',見證你的數據成果!")
執行結果:
請打開資料夾中的 'foundation_wordcloud.html',使用瀏覽器,見證你的數據成果!
Yiru@Studio - 關於我 - 意如