文、意如
網路的時光隧道
1990年代 Yahoo
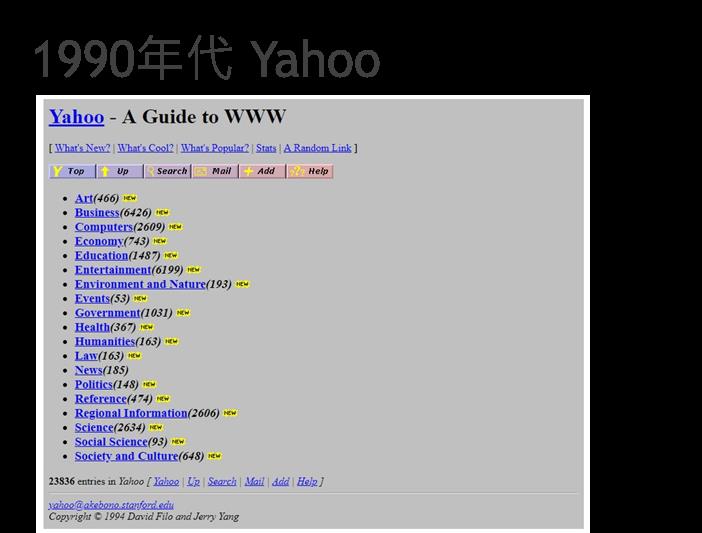
還記得當年數據機的嘰嘰叫聲嗎?還記得開一張圖要等個10分鐘的時光嗎
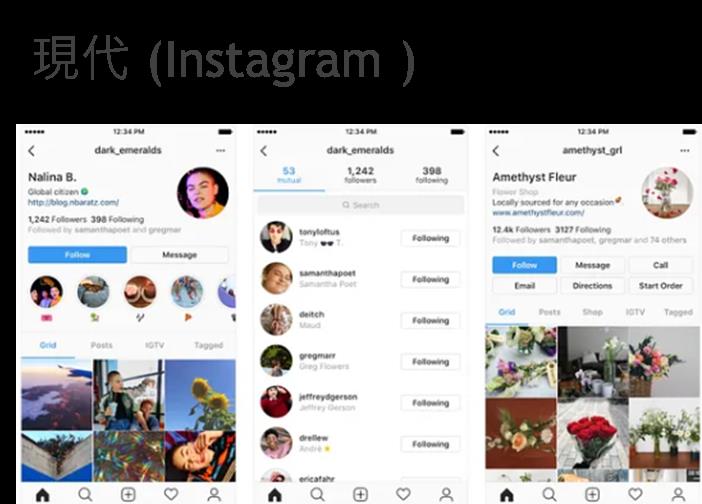
現代 (Instagram )
Web 1.0:唯讀時代 (Read-Only)
靜態、單向、資訊公布欄
就像在看「電子報紙」,你只能讀,不能留言
特點:
內容由網站主提供。
沒有社群互動。
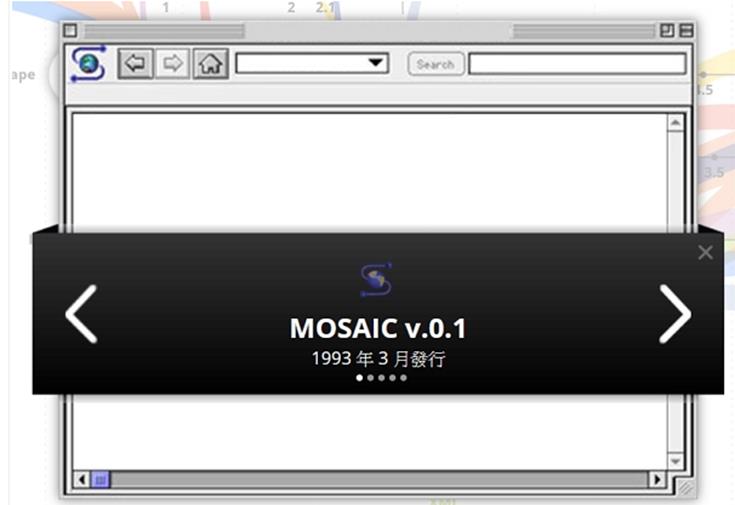
史上第一款獲得普遍使用的瀏覽器,正是Mosaic瀏覽器,第一版於1993年4月22日發佈
Web 2.0:讀寫與互動時代 (Read-Write)
社群、UGC (使用者生成內容)、中心化。
就像「大廣場」,每個人都能帶擴音器演講,但廣場是私人企業(FB/Google)開的
特點:
雙向: 留言、分享、直播。
代價: 你的數據(個資)換取免費服務。
Most Popular Social Networks (2003 - 2020)
Web 3.0:去中心化與所有權 (Read-Write-Own)
區塊鏈、數據所有權、邊緣運算。
就像「合作社」,沒有大老闆,每個人都擁有自己的一塊紀錄
(代幣/資料)。
特點:
去中心化: 不再受限於單一伺服器。
數據主權: 你的數位足跡由你自己管理。
當前趨勢:AI 驅動的語義網
AI 不再只是找關鍵字,而是「理解」需求。
傳統搜尋: 輸入「台南美食」,給你一堆連結。
AI 語義搜尋 (如 Perplexity/ChatGPT): 輸入「推薦台南適合帶長輩去的餐廳,要有電梯」,直接生成具體建議。
例如:https://youtube.com/shorts/44o7YLvBUtM?si=v812k9Os7F0DARwV
網路演進:從 Web 1.0 到 Web 3.0 /十題挑戰
Q1. 在 Web 1.0 時代,使用者與網頁的主要互動方式為何?
(A) 雙向互動,隨時留言
(B) 只能閱讀資訊,屬於單向接收
(C) 共同編輯內容
(D) 透過語音控制網頁
1.(B):1.0 時代像看報紙,是唯讀的。
Q2.Web 2.0 最核心的特徵之一是「UGC」,請問它的中文意思是什麼?
(A) 使用者生成內容
(B) 全球資訊網路
(C) 雲端運算架構
(D) 去中心化管理
2.(A):UGC = User Generated Content。
Q3. 下列哪一個平台最能代表 Web 2.0 的「中心化」與「社群互動」特質?
(A) 靜態的公司官網
(B) 電子報
(C) Facebook (臉書)
(D) 個人純文字部落格(無留言功能)
3.(C):社群媒體是 2.0 的代表。
Q4. Web 3.0 被稱為「去中心化」的網路,主要是依賴哪種技術來實現?
(A) 5G 通訊
(B) 區塊鏈 (Blockchain)
(C) 光纖網路
(D) 大型伺服器機房
4.(B):區塊鏈是 3.0 去中心化的核心。
Q5. 關於 Web 1.0 到 Web 3.0 的權限演進,下列敘述何者正確?
(A) Web 1.0 是「可讀、可寫、可擁有」
(B) Web 2.0 是「只能閱讀」
(C) Web 3.0 強調「數據所有權」回歸使用者
(D) 所有世代的網路都沒有差別
5.(C):3.0 讓使用者擁有自己的數據。
Q6. 在 Web 3.0 的願景中,我們希望解決 Web 2.0 時代的什麼問題?
(A) 網路速度太慢
(B) 數據被少數中心化大平台壟斷
(C) 圖片畫質不夠高
(D) 網頁沒辦法放影片
6.(B):2.0 的痛點是平台高度中心化。
Q7. 下列何者「不屬於」Web 2.0 時代的產物?
(A) Instagram
(B) YouTube
(C) 撥接上網時期的靜態 HTML 網頁
(D) TikTok
7.(C):靜態網頁屬於 1.0。
Q8. 所謂的「語義網」(Semantic Web)主要是指讓電腦能夠如何處理資訊?
(A) 讓電腦能讀懂單字,但不懂邏輯
(B) 讓電腦能理解內容的「含義」與「情境」
(C) 讓電腦純粹儲存大量圖片
(D) 讓電腦只能處理數字
8.(B):語義網的核心在於「理解」。
Q9. AI 驅動的搜尋方式(如 ChatGPT、Perplexity)與傳統搜尋引擎最大的不同點為何?
(A) 傳統搜尋給一堆連結,AI 則能理解需求並整合答案
(B) AI 搜尋只能搜尋文字,不能搜尋圖片
(C) 傳統搜尋比 AI 搜尋更懂人類的情緒
(D) AI 搜尋完全不需要用到網路
9.(A):AI 搜尋是基於對自然語言的理解。
Q10.邊緣運算 (Edge Computing) 在 Web 3.0 中扮演的角色主要是?
(A) 讓所有數據都傳回美國的伺服器
(B) 讓運算在靠近數據源頭的地方進行,提升效率與隱私
(C) 取代所有的行動電話
(D) 專門用來備份老舊的網頁
10.(B):邊緣運算分散了運算壓力,符合去中心化精神
思辨題
https://forms.gle/4k9YJxyniuexZV8r9

題目一:
Web 3.0 強調「數據主權回歸個人」,但在 Web 2.0 時代,我們習慣以「個資」換取「免費且便利」的服務(如免費的 Google 地圖、FB 社交)。
如果未來所有服務都要付費(或支付代幣)才能保障隱私,你願意買單嗎?
- 參考觀點 A(支持買單): 隱私是基本人權。長期下來,中心化平台透過演算法控制我們的行為,代價比付費更高;唯有付費才能斷開被「收割」的循環。
- 參考觀點 B(持保留態度): 便利性與低門檻是網路普及的關鍵。若全面轉向 Web 3.0 付費模式,可能會造成「數位階級」,只有富有的人才能擁有隱私與高品質服務。
題目二:在 Web 2.0 中,若有假訊息或違法內容,政府可以要求平台(如 YouTube)下架。但在 Web 3.0 的去中心化世界裡,內容儲存在所有節點且不可篡改,當「無法被刪除」的假訊息或仇恨言論出現時,我們該如何管理?
- 參考觀點 A(技術中立論):
網路應保持絕對言論自由,不應由單一權威決定是非。
應透過社群共識機制(如 DAO 投票)來篩選內容,而非由中心化機構強制刪除。
- 參考觀點 B(社會秩序論):
絕對的去中心化會成為犯罪的溫床。
完全無法刪除的資訊可能對受害者造成永久傷害,技術演進不應凌駕於社會倫理與法律保護之上。
題目三:當 AI(如 ChatGPT)能直接針對問題給出精確答案,我們不再需要從搜尋結果中「自行篩選、比較、閱讀多方資料」時,這會提升人類的效率,還是會導致我們失去辨別真偽與獨立思考的能力?
•參考觀點 A(效率至上): 人類應從低效率的資料檢索中解放,將精力花在更高階的決策與創意上。AI 只是更強大的工具,就像計算機取代心算一樣。
•參考觀點 B(認知危機): 搜尋的過程本身就是學習。如果直接接收「餵養」的答案,人們會逐漸忽視資料來源與論證過程,更容易被 AI 的偏見或幻覺(Hallucination)所誤導。
Yiru@Studio - 關於我 - 意如