上個月 OpenAI 宣布了 ChatGPT 支援外掛,因此讓 ChatGPT 可以瀏覽網頁或是使用不同的資料來源來加強回應的結果,而在前幾天微軟也在 Azure OpenAI Service 上推出了新的功能,讓我們可以使用自己的資料集,背後就是透過 Azure 認知搜尋 (Azure Cognitive Search) 這一個服務,它可以針對我們的資料來源做索引,然後提供搜尋的服務,因此我們可以做出自己的知識庫之後,提供給 Azure OpenAI Service 使用,讓回覆的結果更精確。
說明
建立 Azure Cognitive Search 服務
首先來準備我們的資料,搜尋 Azure Cognitive Search 來建立服務。
建立的過程一樣基本的資料和定價層選取,因為只是測試,所以可以選擇免費或是基本就很夠用了,高一點的定價層會有比較多的副本跟資源讓建立索引跟搜尋會更快一點。
建立資料集
建立好之後有很多種方式可以來建立我們的資料,主要就是透過 Azure Portal、Rest Api 來建立索引和匯入資料。
Azure Portal
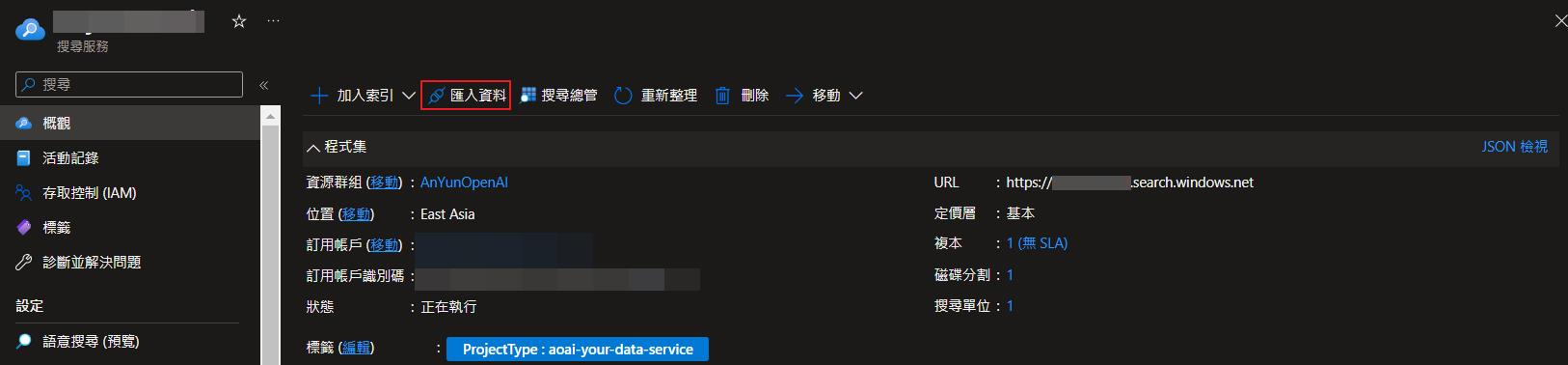
在概觀的地方可以點選匯入資料來新增我們的資料。
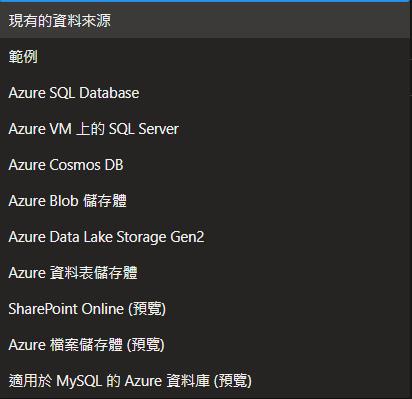
目前可以連結的資料來源以及有兩個現成的資料範例可以使用。
這邊我用現成的範例 hotels-sample 做展示。
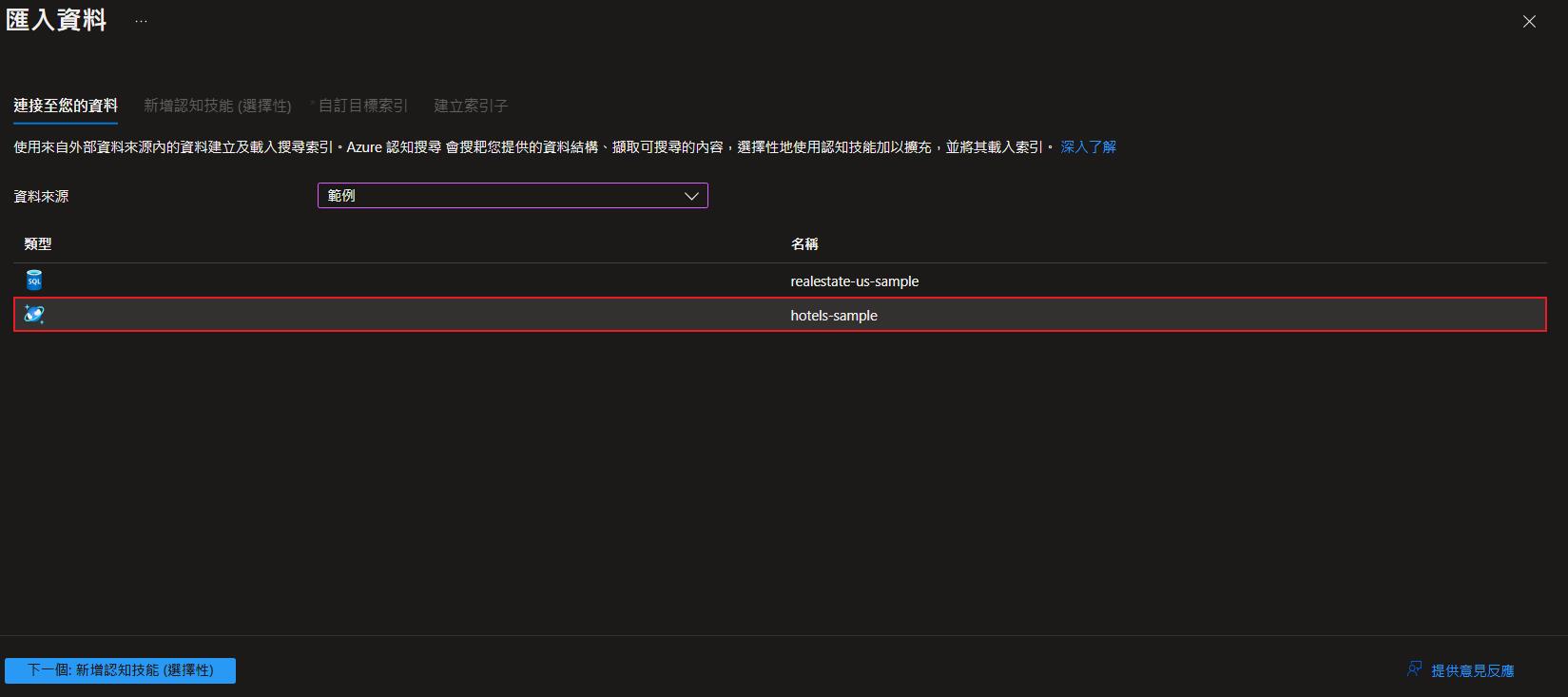
認知技能就暫時在本範例中用不到,就不多做說明了,未來有介紹整個服務再來探討,接下來就是針對要做索引的資料作相關設定,就可以來建立索引了。
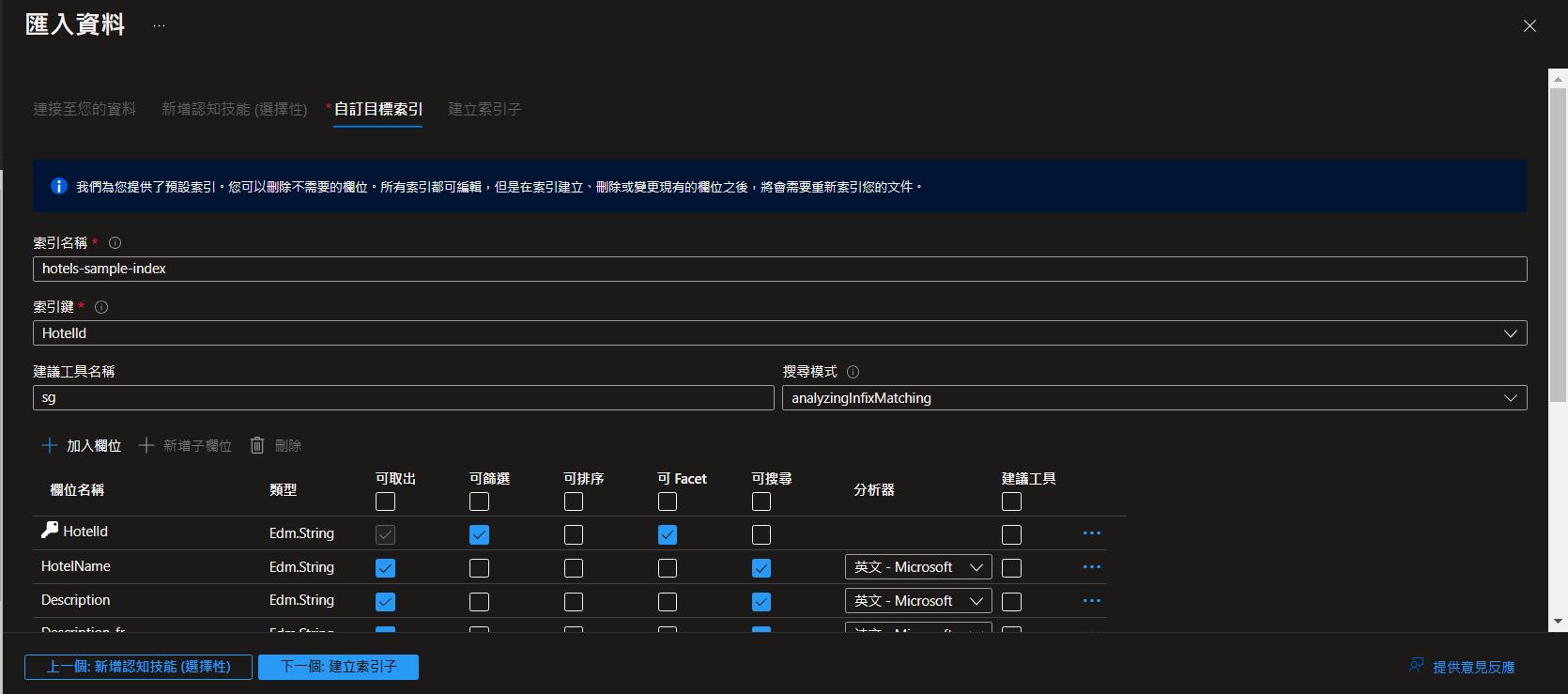
建立好之後就可以在概觀的地方點選索引的頁籤來檢視結果,建立索引會需要一點時間,完成之後就可以看到目前資料的筆數跟佔用的儲存體大小了。
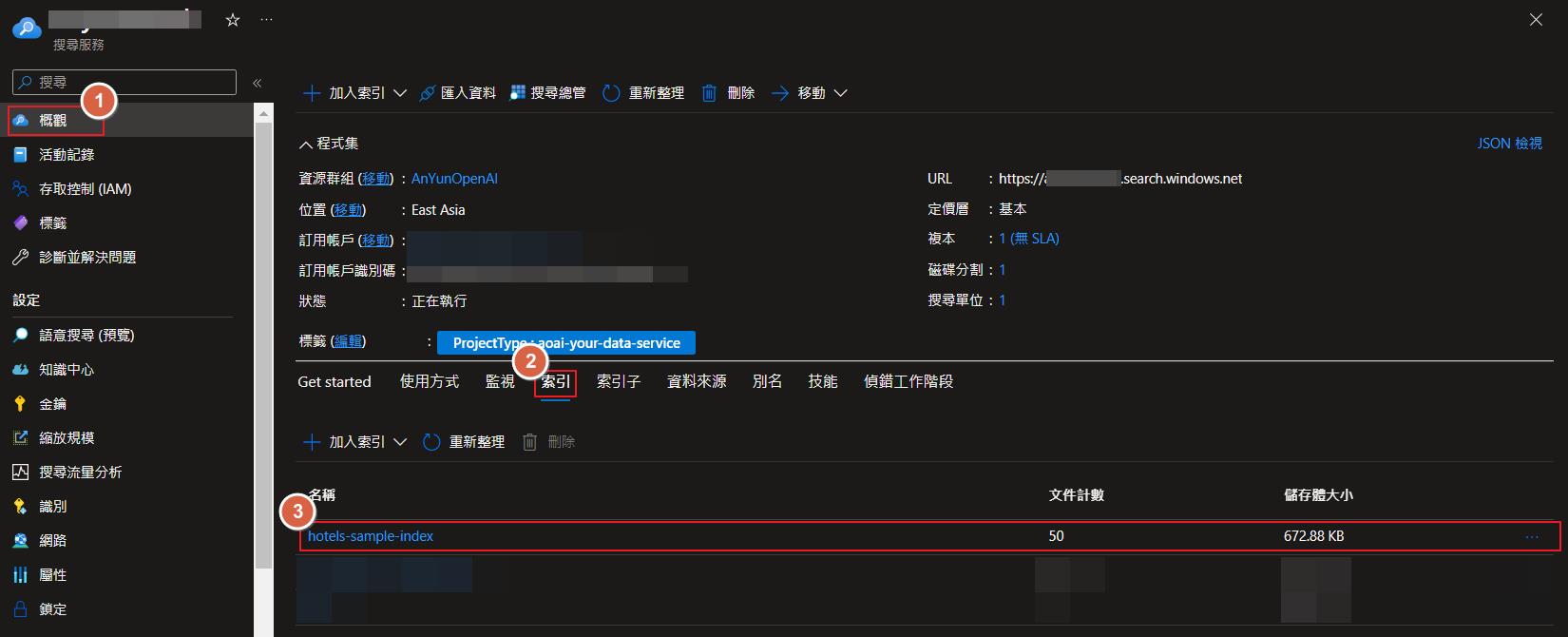
Rest Api
不過為了之後可以更方便或是程式化還是要知道如何用 Api 來建立索引和匯入資料。我們可以從知識中心點選連線到您的資料,再選取取得 Postman 集合,就可以下載到一份包含我們建立的服務的位址和金鑰的 Postman 集合的設定檔可以讓我們匯入 Postman。
此檔案需小心保管,因為有包含自己建立出來的服務的金鑰,請不要隨意分享出去了。
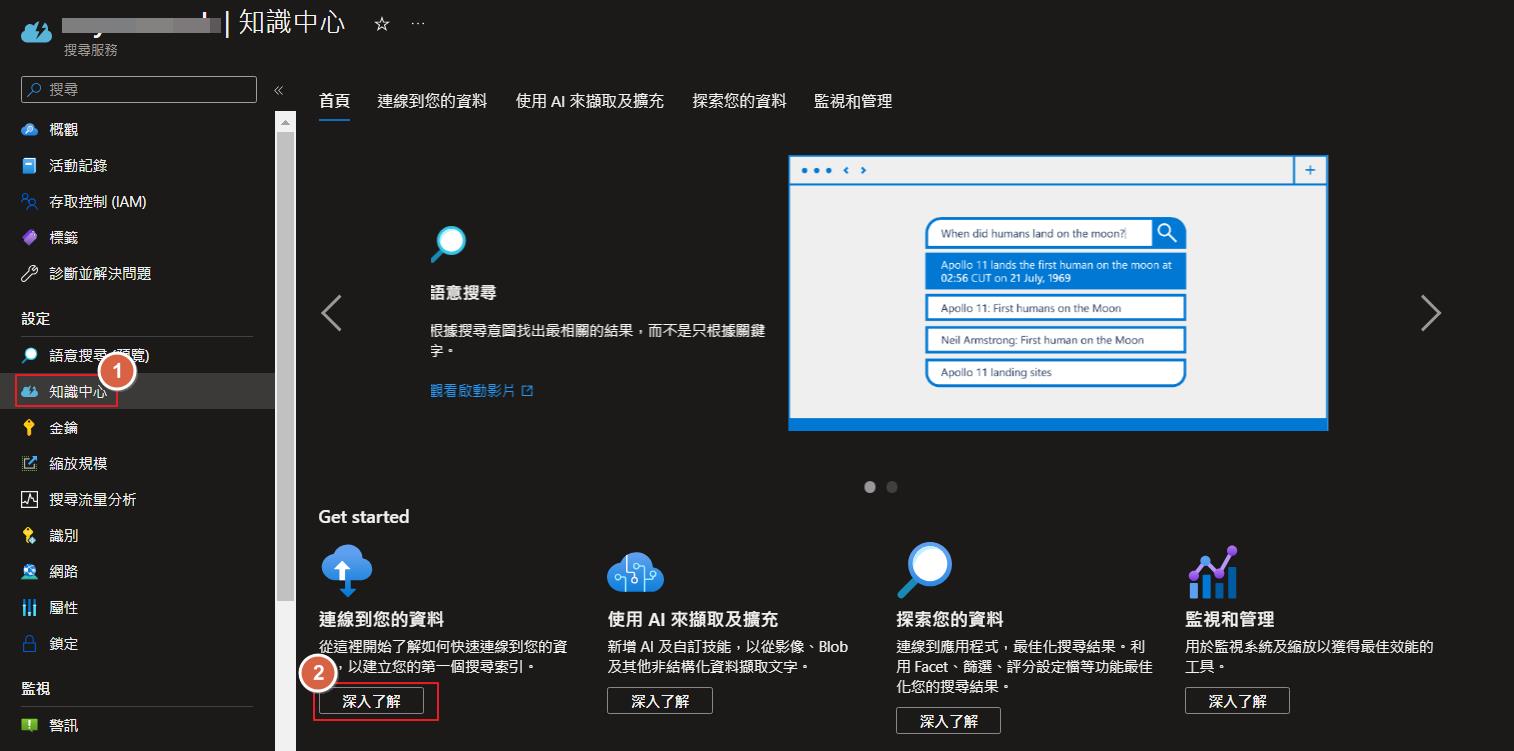
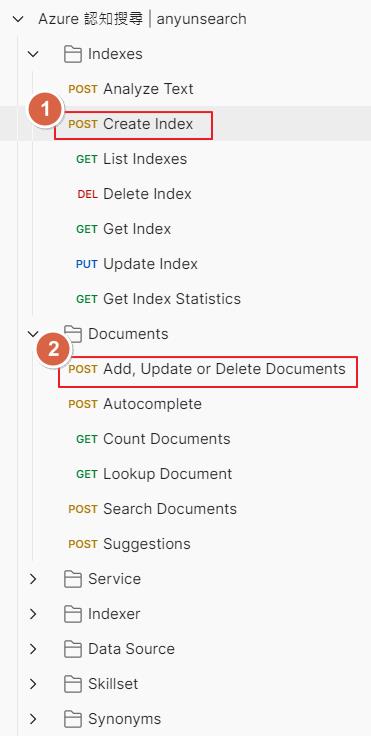
匯入到 Postman 之後就可以快速的來呼叫 Api 了,這次主要會用到 Create Index 和 Add, Update or Delete Documents 這兩個 Api 設定。
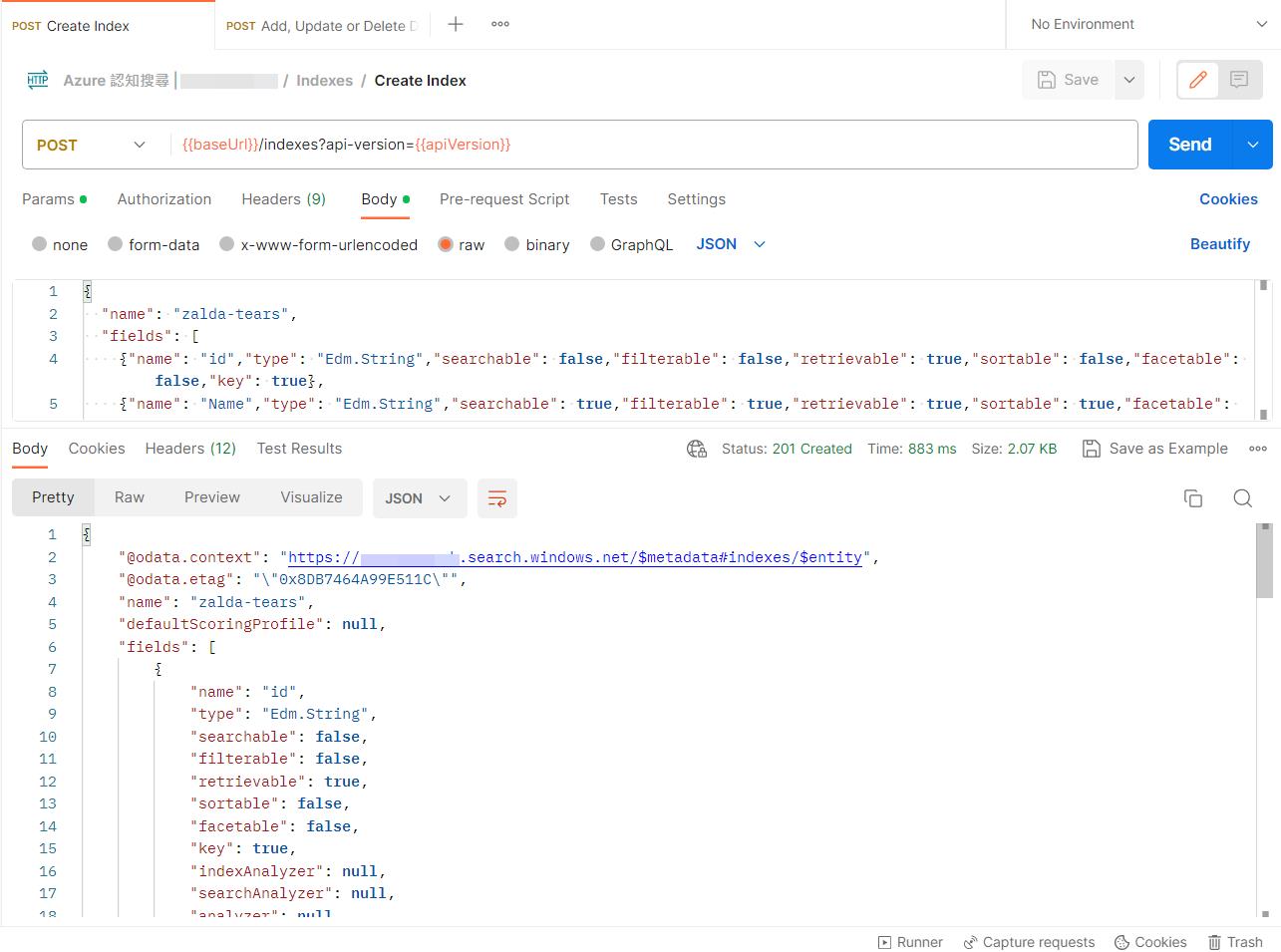
後面的展示就會用這次建立的資料來做,所以我準備了一份遊戲薩爾達 - 王國之淚的人物圖鑑資料範例,底下是建立索引的欄位相關設定,更多欄位或 Api 說明可以參考官方文件。
{
"name": "zalda-tears",
"fields": [
{"name": "id","type": "Edm.String","searchable": false,"filterable": false,"retrievable": true,"sortable": false,"facetable": false,"key": true},
{"name": "Name","type": "Edm.String","searchable": true,"filterable": true,"retrievable": true,"sortable": true,"facetable": false,"key": false,"analyzer": "zh-Hant.lucene"},
{"name": "Name_En","type": "Edm.String","searchable": true,"filterable": true,"retrievable": true,"sortable": true,"facetable": false,"key": false,"analyzer": "en.lucene"},
{"name": "Name_Jp","type": "Edm.String","searchable": true,"filterable": true,"retrievable": true,"sortable": true,"facetable": false,"key": false,"analyzer": "ja.lucene"},
{"name": "Description","type": "Edm.String","searchable": true,"filterable": true,"retrievable": true,"sortable": false,"facetable": false,"key": false,"analyzer": "standard.lucene"}]
}所以透過 Create Index 這一個設定的結果來建立我們的索引資料。
再來我準備了 5 筆簡單的資料要來匯入。
{
"value": [
{
"@search.action": "upload",
"Id": "1",
"Name": "林克",
"Name_En": "Link",
"Name_Jp": "リンク",
"Description": "林克(日文:リンク,英語:Link)是薩爾達傳說系列中每部主角的名字,這可能是他們的真名亦或是傳說中的代稱;雖然並非全都是同一位,但是在故事背景的設定下他們皆被視為勇者之魂的轉世,是女神所欽選為保護世界遠離邪惡威脅的天選之人,當中有幾位更是有著血緣關係,以精神傳承的方式繼承著古代勇者的偉業。"
},
{
"@search.action": "upload",
"Id": "2",
"Name": "薩爾達",
"Name_En": "Zalda",
"Name_Jp": "ゼルダ",
"Description": "根據薩爾達傳說系列時間軸的設定,最早的薩爾達是一位於天空時代中,作為海利亞女神轉世誕生的平凡少女,而她之後於《禦天之劍》事件中覺醒為海利亞女神的人世化身,因此她的後裔,亦即海拉魯王族都繼承了此神聖的血脈,而皇室中與她同名的成員,也就因為身為女神轉世的象徵作為女王皇儲的身分留名於歷史上。"
},
{
"@search.action": "upload",
"Id": "3",
"Name": "加儂多夫",
"Name_En": "日文:ガノン,英語:Ganon",
"Name_Jp": "ガノン",
"Description": "加儂(日文:ガノン,英語:Ganon),或稱加儂多夫(日文:ガノンドロフ,英語:Ganondorf),又譯作蓋儂/蓋儂多夫、格諾/葛諾多夫、卡農/卡農多洛夫 等,從系列第一作就作為最終魔王登場,之後的作品中也時常出現或被提及,是薩爾達傳說系列主要的反派角色。"
},
{
"@search.action": "upload",
"Id": "4",
"Name": "普爾亞",
"Name_En": "Purah",
"Name_Jp": "プルア",
"Description": "普爾亞(日語:プルア;英語:Purah)是一名於《曠野之息》中登場的女性希卡族人。她是卡卡利科村村長英帕的姊姊,任職於哈特諾古代研究所的所長,也是少數見證百年前海拉魯王國於災厄之戰中滅亡的希卡族人。"
},
{
"@search.action": "upload",
"Id": "5",
"Name": "勞魯",
"Name_En": "Rauru",
"Name_Jp": "ラウル",
"Description": "勞魯(日語:ラウル;英語:Rauru),是一名首次於《王國之淚》中登場的人物,不過他的經歷則遠比《王國之淚》的時代還要悠久。身為左納烏族的勞魯在萬年前的海拉魯大地上,與海利亞人的索尼婭結為夫婦,並建立起延續到《曠野之息》時代的海拉魯王國,勞魯也因此成為海拉魯的初代國王。"
}
]
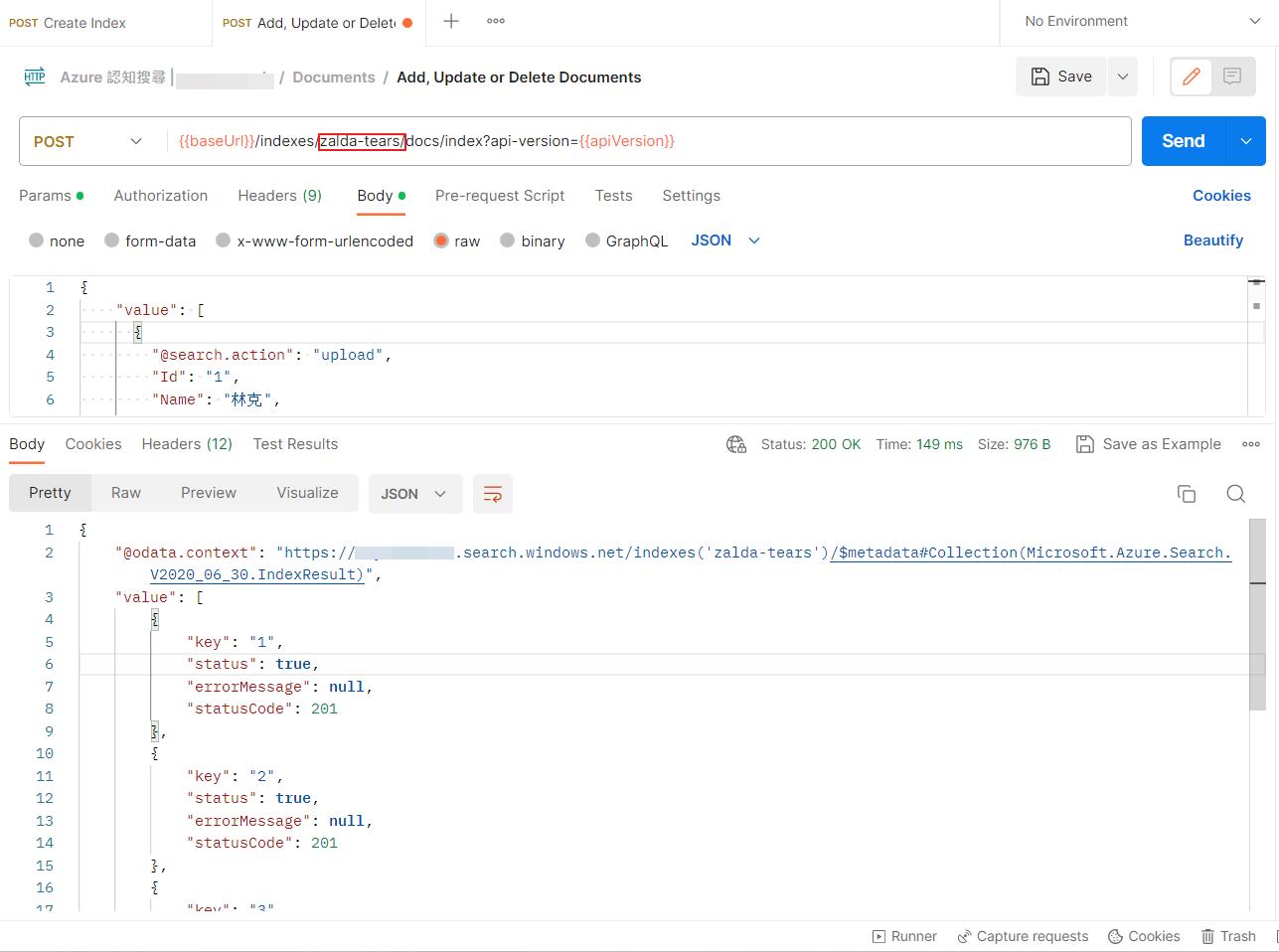
}再來就是透過 Add, Update or Delete Documents 這個設定來匯入資料,記得將紅框部分改成前面我們設定的索引名稱。
一樣可以在 Azure Poral 確認索引是否有被建立了,確認之後我們就建立好接下來要用到的資料集了。
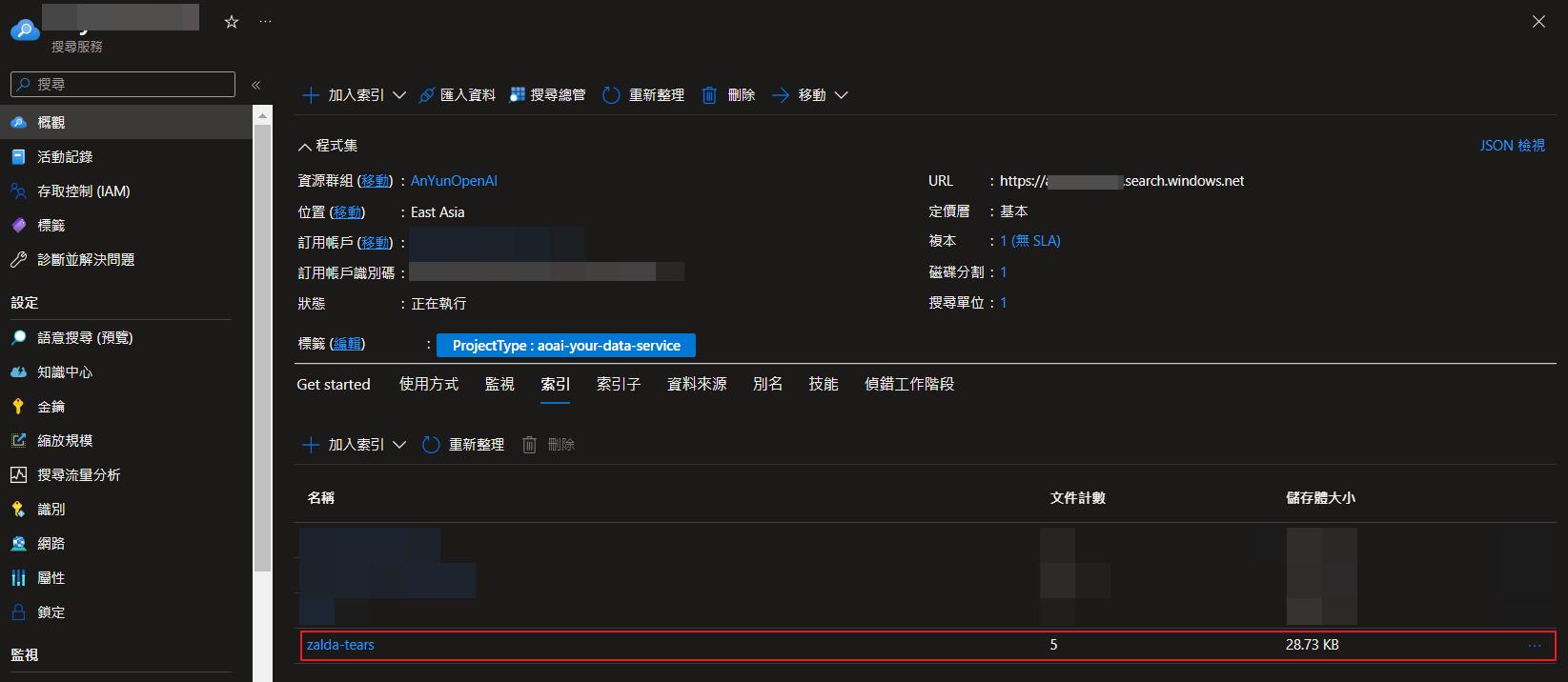
透過 Azure OpenAI Studio 設定資料集
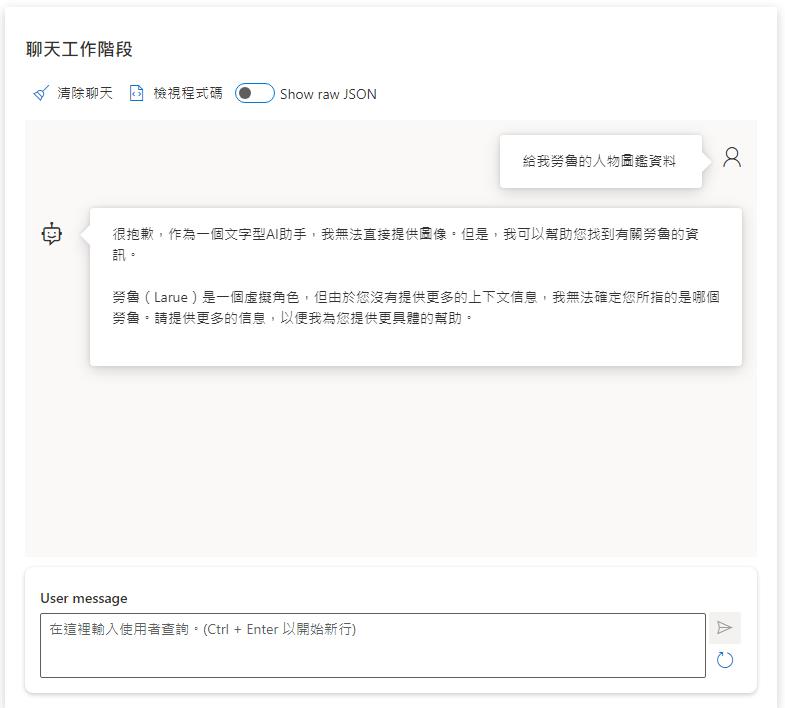
首先測試在還沒設定之前是無法回答這個問題了,畢竟王國之淚是最近才上式的遊戲,在目前資料訓練的範圍是不可能會知道的。
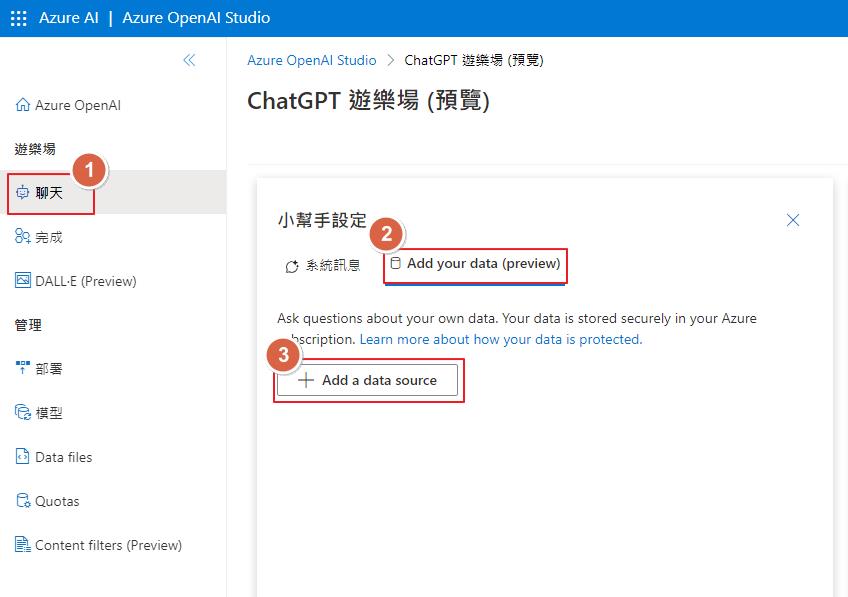
接下來開啟 Azure OpenAI Studio 來設定資料,在聊天的分頁裡面多了可已設定資料,就點選 Add a data source 來新增資料。
資料來源就選擇認知搜尋,他會自動帶出帳號內有的服務,就選擇前面我們建立的服務和索引。
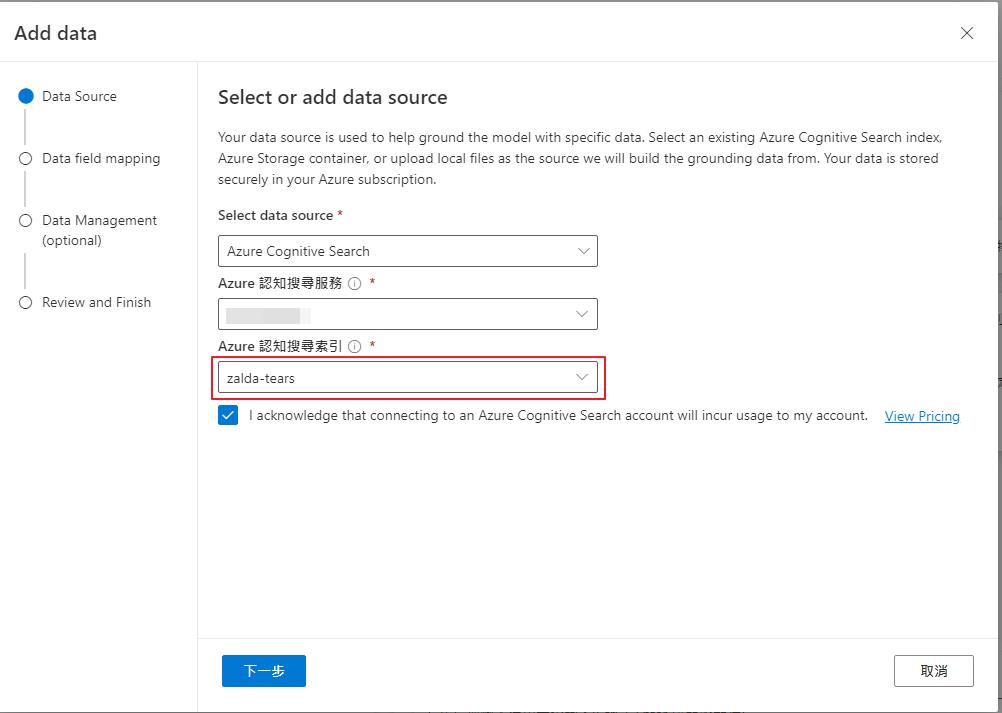
再來選擇資料內容的欄位,就可以到最後一步儲存了。
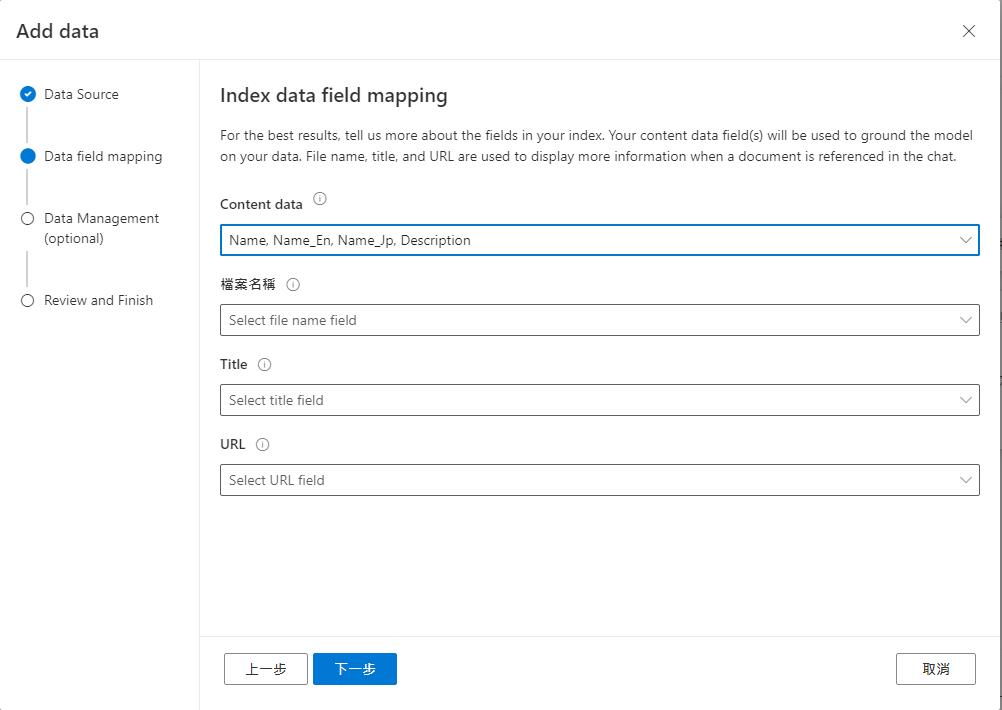
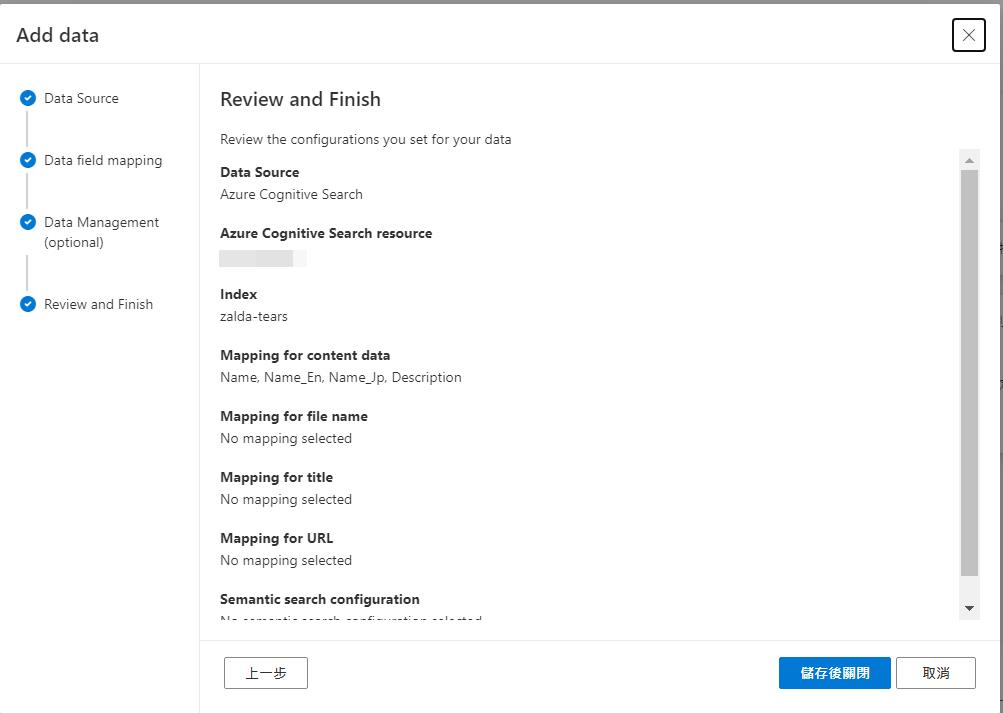
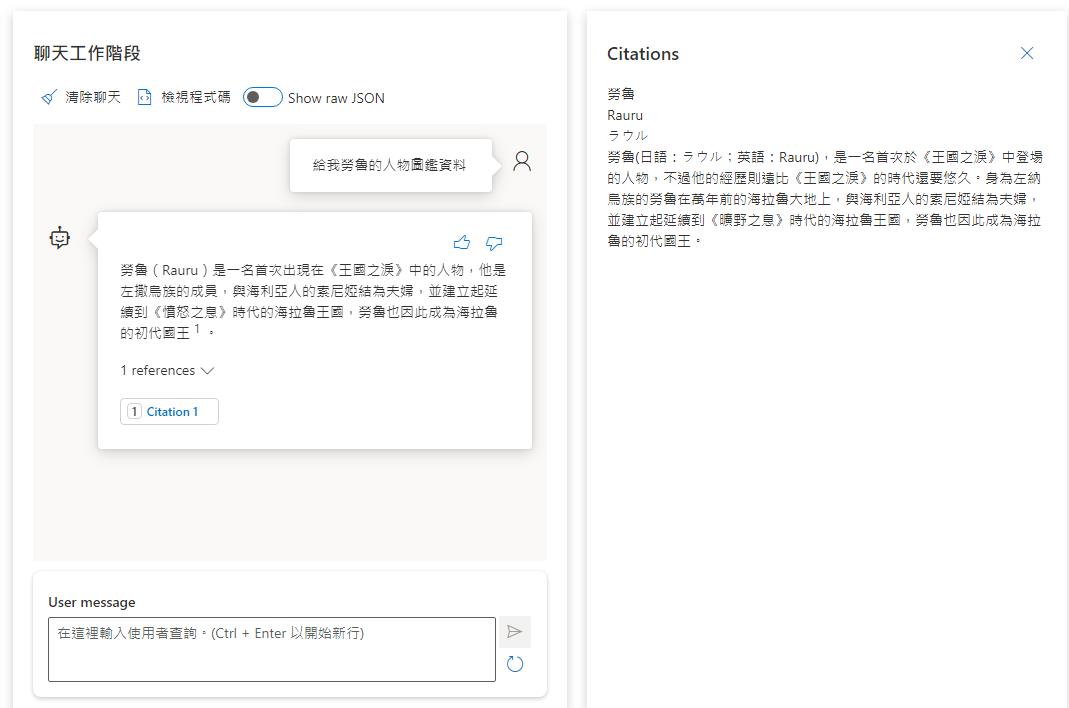
設定都正確的話就可以測試結果了,這次回應的結果就會根據搜尋到的資料來回覆了,也有查到的資料做為參考。
如果在新增資料的時候選擇儲存體就會儲存體內用來建立索引的檔案,目前可以支援的檔案類型會是底下這些,PDF 也會自動辨識文字內容做為索引。
- .txt
- .md
- .html
- Microsoft Word 檔案
- Microsoft PowerPoint 檔案
一鍵部署聊天機器人站台
最近的更新除了可以用自己的資料來源也多了一個一鍵部署站台的功能,只需要點選右上角的 Deploy to… 就可以了。

可以選擇建立新的站台或是更新現有的站台,建立新的站台會建立 Linux 的 App Service Plan,並且整合 AAD 登入驗證功能,我們就可以在幾分鐘之類得到一個有登入驗證功能的聊天機器人站台可以測試了。
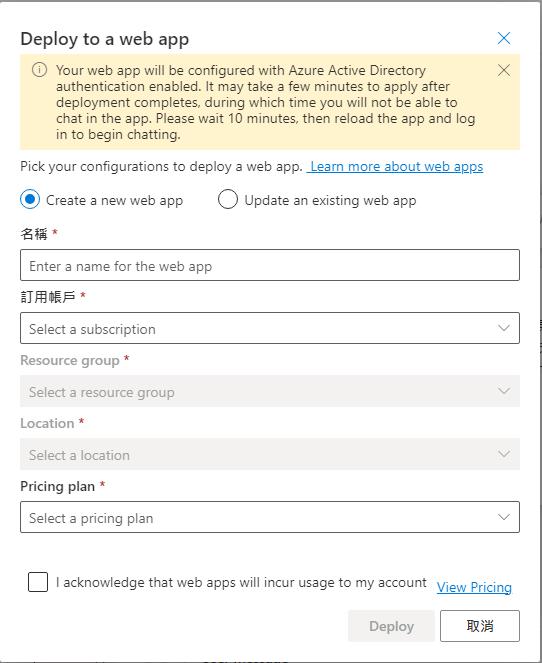
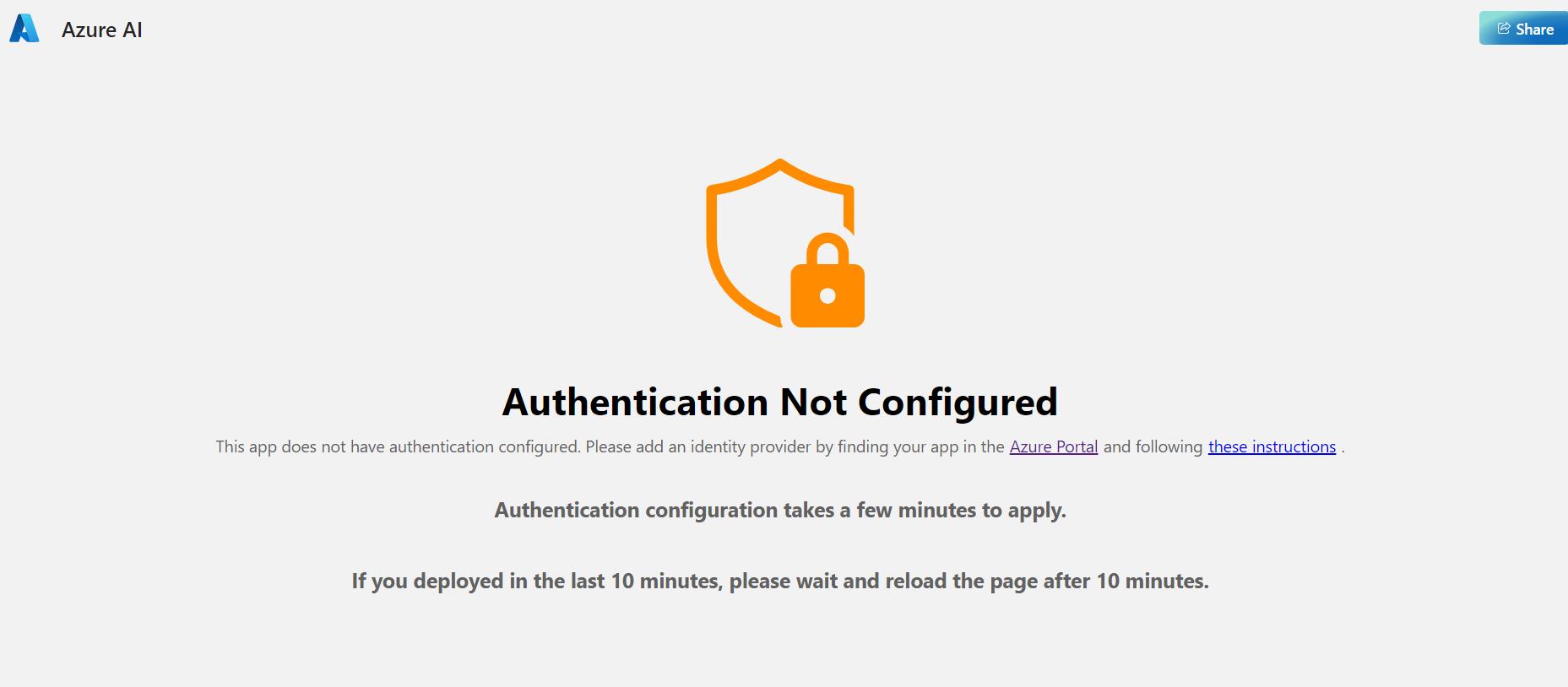
剛建立好的時候驗證部分會還沒生效,會出現底下的畫面,等個幾分鐘之後再重新整理就會看到站台了。
它會把我們剛剛在 Azure OpenAI Studio 設定的相關參數都設定到建立的站台的組態內,所以可以得到跟剛剛測試一樣的結果。
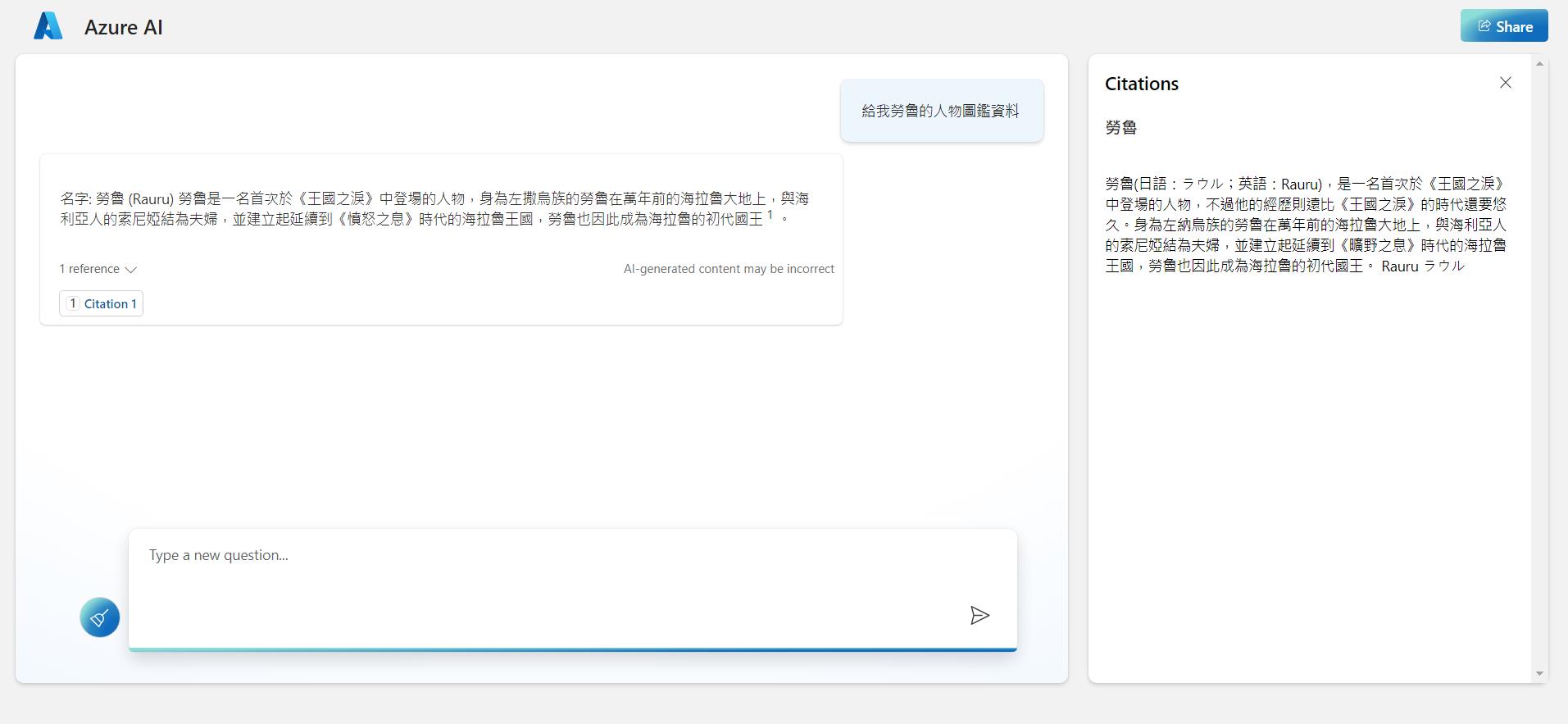
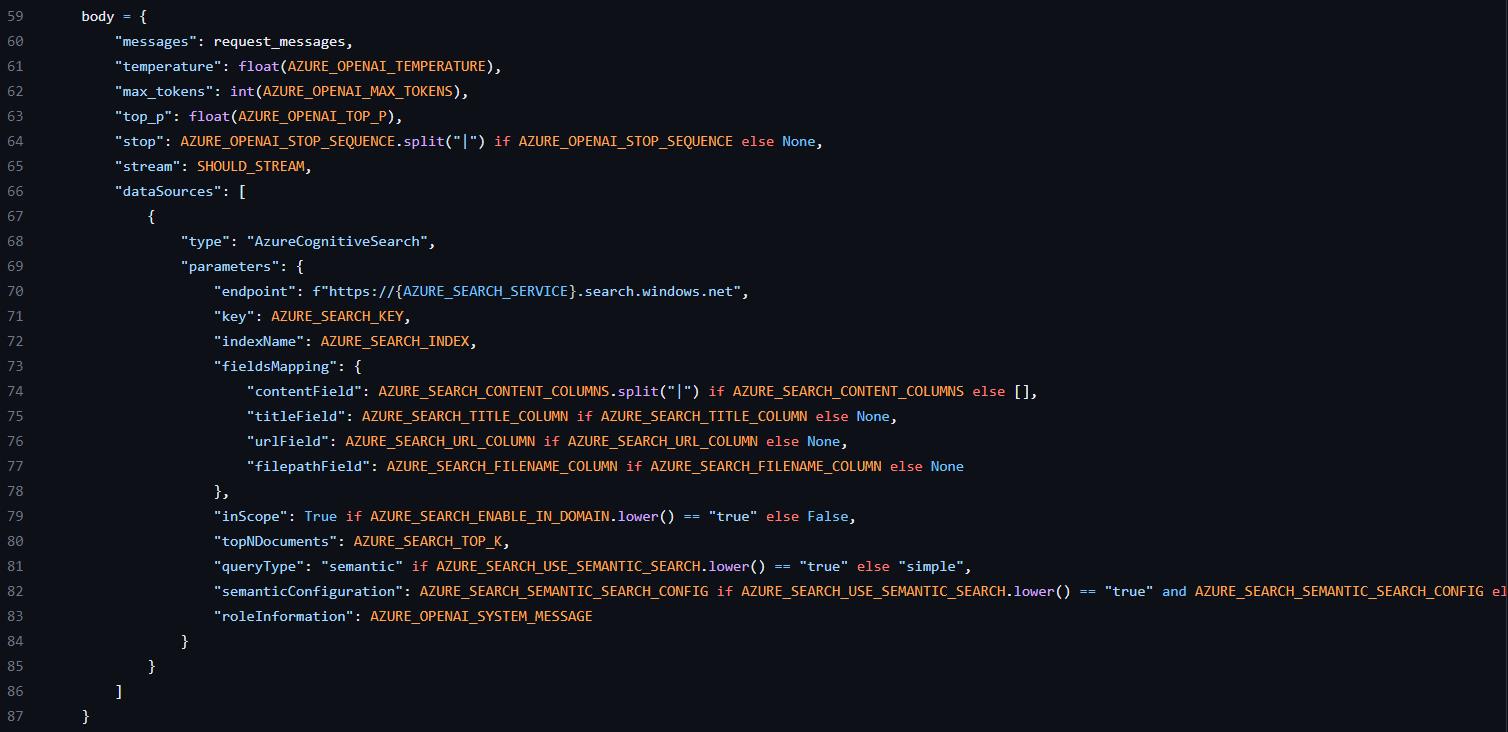
這時候去 App Service 察看就可以發現部署的站台原始碼是在 GitHub 上。感興趣的話就可以去看看原始碼,是用 Python 寫的站台,也可以知道如果要自己用 Api 打的話是多了哪些參數,就可以整合到自己的站台或服務上了。
結論
雖然 Azure OpenAI Service 目前只支援認知服務和儲存體,我想未來應該也會可以串接自己的 Api 來製作屬於自己的外掛資料給 ChatGPT 來使用,到時候就可以更彈性的可以做出含有企業內部知識庫的聊天機器人了。



