Whisper 是 OpenAI 推出的一個語音辨識的模型,而在 Azure OpenAI Service 也推出了這一個模型,所以我們也可以透過 Azure 使用這一個模型來做語音辨識了,後面就來介紹這個模型跟實做串接的程式。
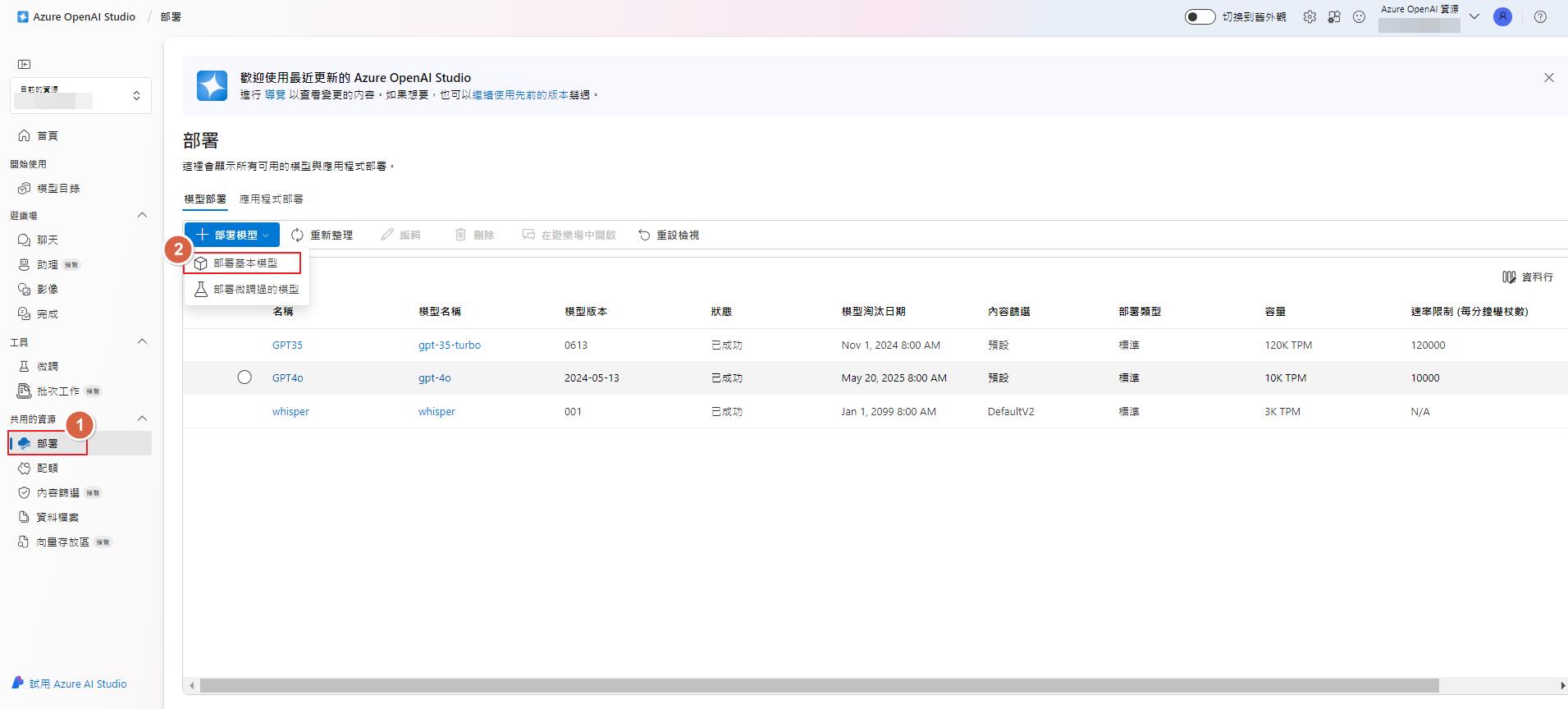
要使用 Whisper 一樣透過 Azure OpenAI Studio 來部署模型,選擇 Whisper 來部署。
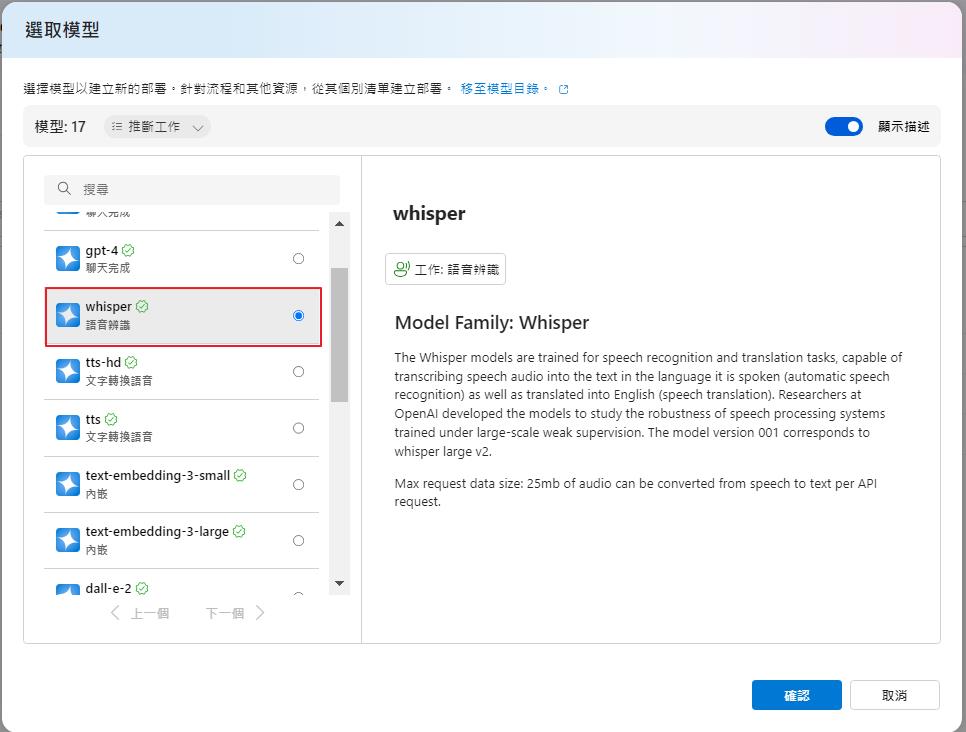

我們也可以透過 Azure AI 的 Speech Studio。點選登入之後就會列出帳號底下的 OpenAI 服務,選擇剛剛建立的模型來做測試。
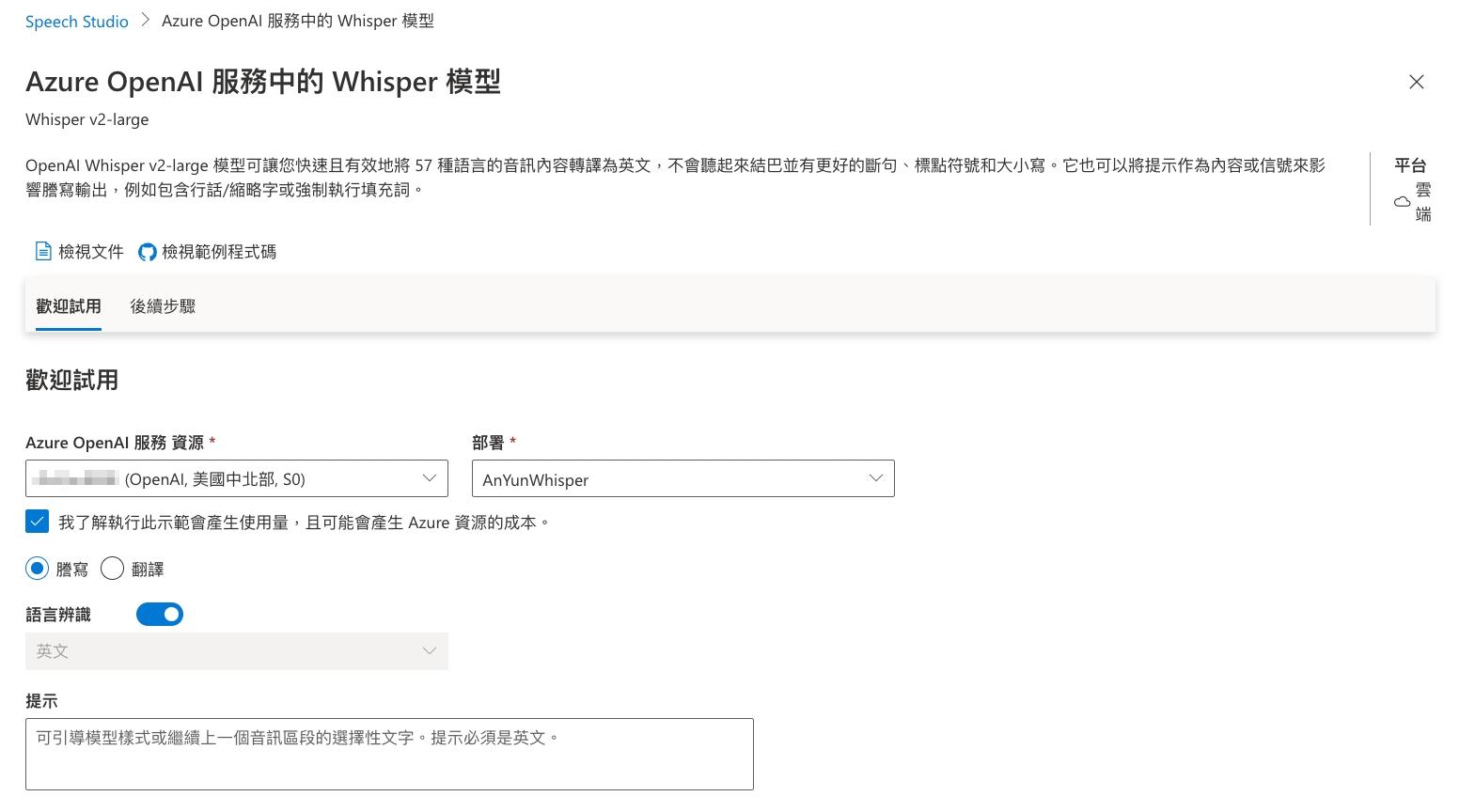
然後選擇謄寫,也就是針對語音來辨識成文字,為了驗證對中文的支持程度,所以用語言辨識,看是否可以正確辨識出來。
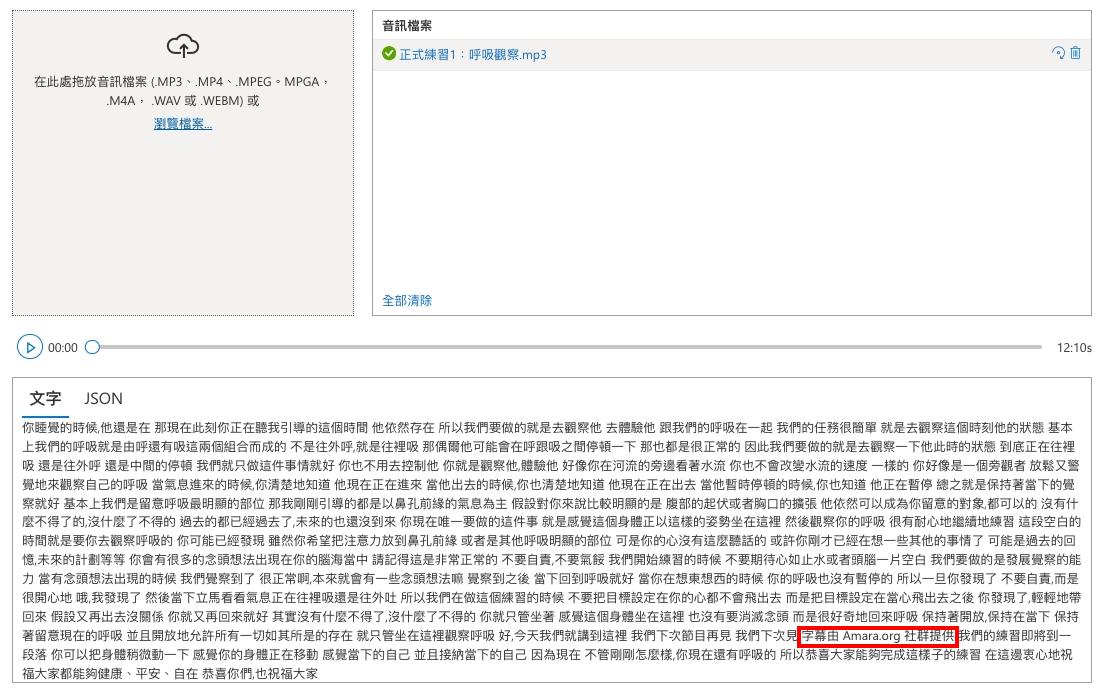
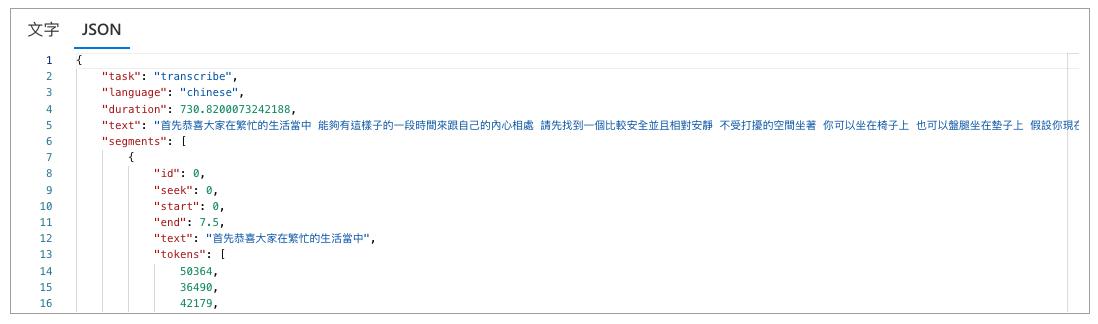
選擇了一個語音檔,等了一下子之後就辨識出來了,基本上辨識的都蠻正確的,但是本語音檔後面有一段是空白的,這一段空白的辨識結果也很有趣的被補上了如紅框中的文字,而點到 Jason 也可以看到回傳的 Json 呈現的模樣。
當然還是要來寫點程式,一樣使用官方套件 Azure OpenAI client library for .NET 來開發。
一樣開了 ASP.NET Core Web 的 Razor Page 專案來做測試,畫面上簡單的放上了選取檔案表單並且上傳。
程式部分也很簡單,透過 IFormFile 來接收檔案,然後使用 OpenAIClient 來呼叫 AudioTranscription 方法來呼叫並取得結果。
public async Task<IActionResult> OnPost(IFormFile voicefile)
{
var apikey = "{your api key}";
var apiUrl = "https://{your openai endpoint}.openai.azure.com";
var deploymentName = "{your deploy}";
var client = new AzureOpenAIClient(new Uri(apiUrl), new AzureKeyCredential(apikey)).GetAudioClient(deploymentName);
try
{
var transcriptionOptions = new AudioTranscriptionOptions()
{
ResponseFormat = AudioTranscriptionFormat.Verbose,
};
AudioTranscription transcription = await client.TranscribeAudioAsync(voicefile.OpenReadStream(), voicefile.FileName, transcriptionOptions);
return Content(transcription.Text);
}
catch (Exception ex)
{
return Content(ex.Message);
}
}最後也得到了辨識的結果了。

完整範例可以到 GitHub 下載。
結論
透過 Azure OpenAI Service 的 Whisper 可以達到不錯的辨識結果,而微軟也有將此模型整合到原本的 Azure AI Speech Service,所以也可以透過對應的 SDK 來開發和使用,而在 Azure OpenAI Service 內的 Whisper 最多只能上傳 25MB 的檔案,所以如果超過 25MB 的語音檔案就可以透過 Speech Service 的批次謄寫功能來處理超過 25MB 的檔案。



