OpenAI 在上個月 DevDay 上 公布了新的模型 GPT-4 Turbo with Vision,它可以讓 GPT4 模型可以認得圖片,可以讓 GPT-4 的應用場景又變的更多元了,而微軟也在本週也把此模型上到 Azure 上了,而且可以搭配 Azure AI Vision (Azure Computer Vision) 達成辨識影片的功能,後面就來介紹實際建置要注意的點和測試的結果。
說明
目前 GPT-4 Turbo with Vision 只在瑞士北部 (Switzerland North)、瑞典中部 (Sweden Central)、美國西部 (West US) 與澳洲東部 (Australia East) 這四個資料中心推出,所以建置服務的時候要注意一下,不然是找不到這個模型的。
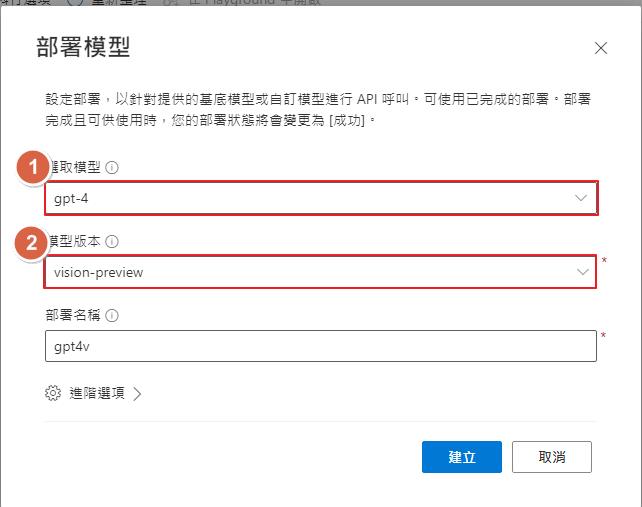
部署模型的時候一樣透過 Azure OpenAi Studio 來部署,部署的時候他被歸類在 GPT4 的其中一個模型,所以選取模型請選擇 gpt-4,在模型版本就可以找到 vision-preview ,如果沒看到的話就要確認一下資料中心是不是正確了。
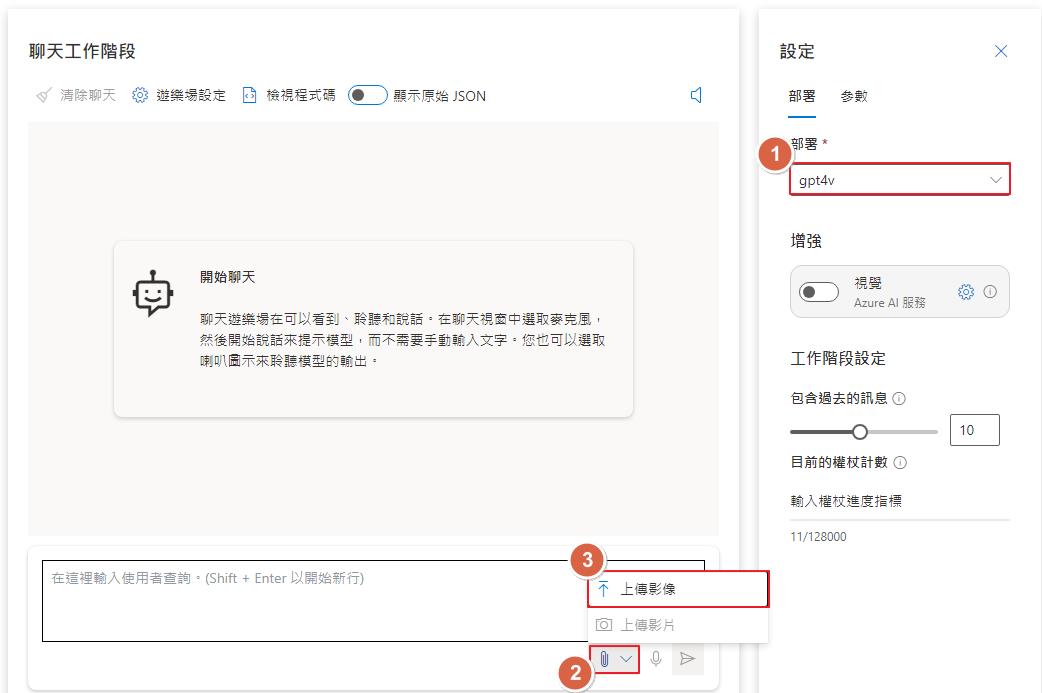
部署完成之後就可以到 PlayGround 來測試看看了,確定模型選擇的是 GPT-4 Turbo with Vision,就可以在聊天的下方點開圖示,就可以看到上傳影像的功能,選擇一張圖片並打上一些提示詞就可以讓 GPT4 來幫我們辨識圖片了。
我用了一張之前測試 Dalle3 時候產生的圖片,讓 GPT-4 來辨識,底下是辨識的結果,有正確的辨識出場景,後續請他辨識左邊的角色也可以正確的辨識出是哆啦 A 夢,效果還不錯。

增強模式
在 Azure 上面的 GPT-4 Turbo with Vision 還可以結合 Azure AI Vision 來辨識影片,增強模式可以額外加強底下的辨識能力:
- 光學字符識別(OCR):Azure AI Vision 透過提供高質量的 OCR 結果,作為模型的補充資訊,並用來輔助 GPT-4 Turbo with Vision。它允許模型為密集文本,並且讓變換後的圖像,與數字密集的財務文件產生更高品質的響應,進而擴展了 OCR 的語言覆蓋範圍。
- 物件定位(Object Grounding):Azure AI Vision 與 GPT-4 Turbo with Vision 的文本回應是相輔相成的—透過物件定位,在輸入的圖像中定位出突出的物件。這種整合為數據分析和用戶交互帶來了新的層次,因為這個功能可以在處理圖像時,以視覺為核心,區分並突顯圖片中的重要元素。
- 影片提示功能(Video prompt):我們正在透過 Azure AI Vision Video Retrieval 的原生整合,使開發者能夠將影片作為 GPT-4 Turbo with Vision 的輸入。這簡化了將影片輸入到應用程式中的過程,消除了複雜的影片處理過程。這種整合,透過對視覺和語音的先進多模態向量索引,實現了影片提示功能(Video prompt)的上下文檢索能力,並允許生成關於影片內容的摘要和答案。
- Azure OpenAI on your data with images:透過結合 GPT-4 Turbo with Vision、Azure AI Search 和 Azure AI Vision,我們正在改變資訊檢索的方式。現在,您可以將圖像添加到文本數據中,利用向量搜索功能,開發一個能夠連接您數據的解決方案,從而實現更好的聊天體驗。
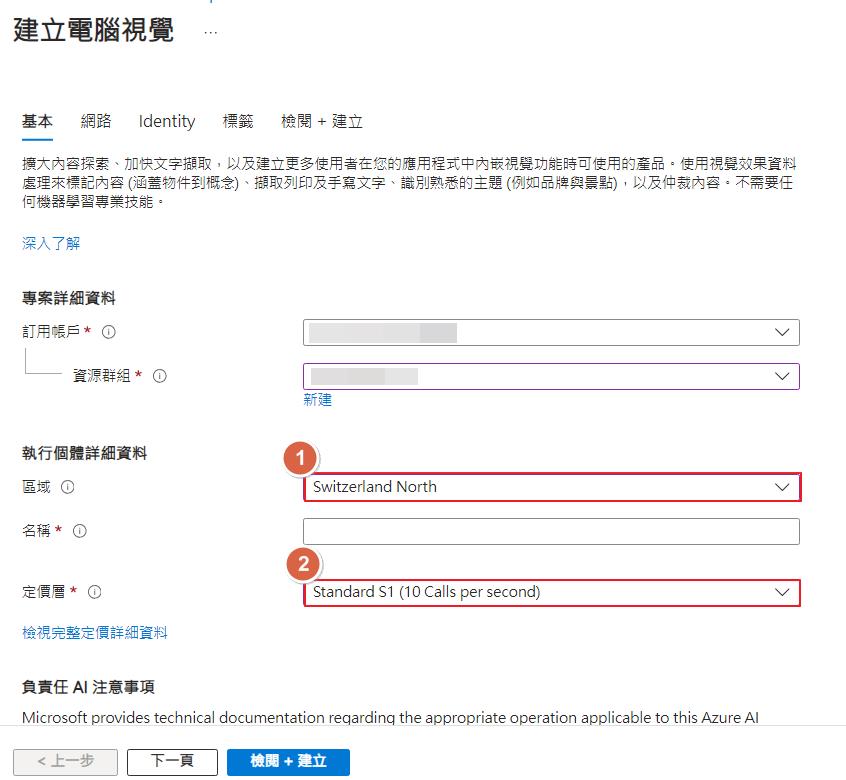
首先需要建立一個 Azure Computer Vision 服務起來,這邊要注意的點是資料中心要選擇和 OpenAI 服務建立的是一樣的,像是我前面測試的是瑞士北部,這邊就要選擇一樣的資料中心,不然後面會選擇不到,此外定價層也不能選擇免費,不然也會抓不到,這一點是文件沒特別提到的,我在測試的時候花了一點時間才找到是這原因。
建立好之後回到 PlayGroung 來設定,在右邊的設定可以找到增強的區塊點選設定之後就可以選擇到我們剛剛建立的資源了。
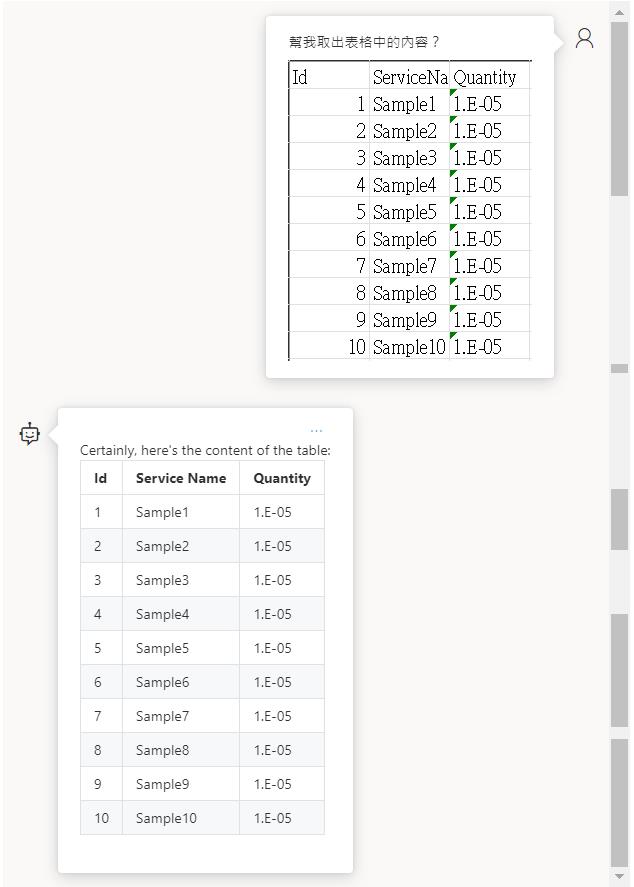
OCR 辨識
在未啟用增強模式底下,無法辨識試算表截圖的內容。

啟用之後就可以正確辨識了。
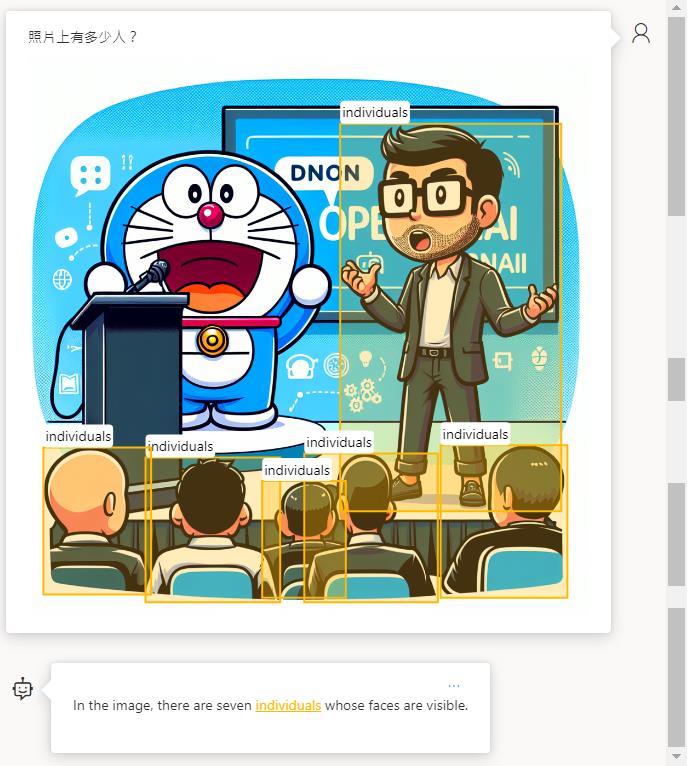
物件定位
在未啟用增強模式前是可以辨識的出來有多少人。

啟用之後可以辨識出來,還可以定位這些物件的位置。
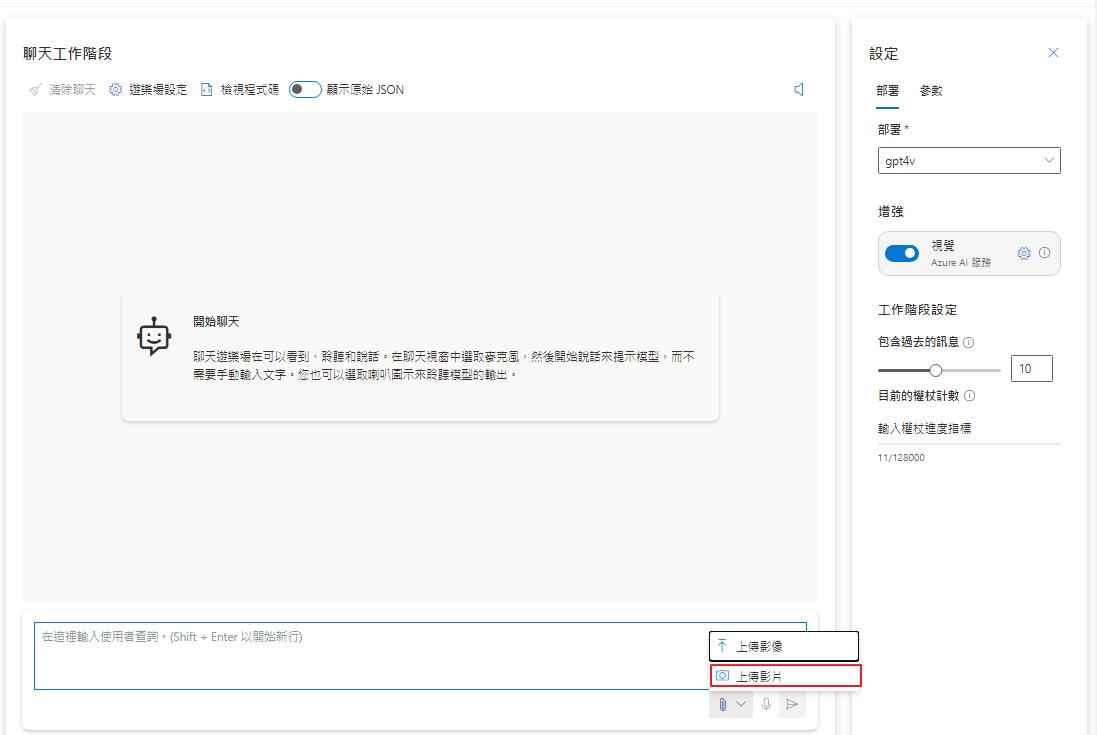
影片提示功能
開啟增加功能選擇檔案的地方就會發現上傳影片的選項可以使用了,要注意的點就是目前支援的影片長度為 3 分鐘,且影片解析度越大相對產生的費用也會越高。
在辨識的過程可以注意到畫面上,服務把影片解取畫面然後取出 20 個畫面給 GPT-4 Turbo with Vision 來辨識。
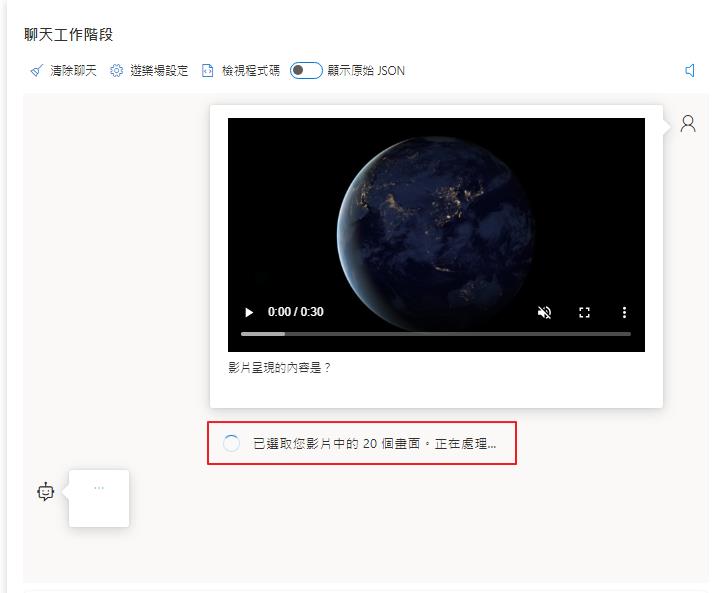
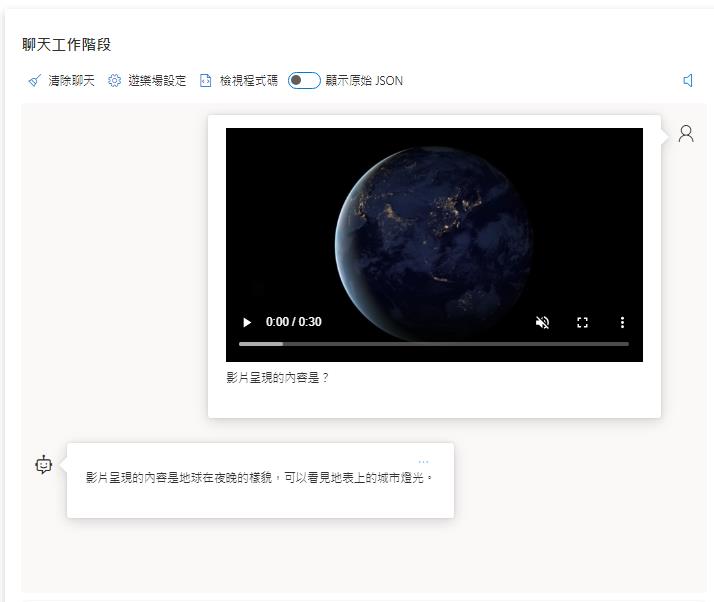
最後等一下就可以看到結果了,結果也還算可以,之前測試的時候還可以判斷出來是地球在旋轉,寫文章的時候就沒有辨識出來了,但是多了描述更多影片的內容。
Azure OpenAI on your data with images
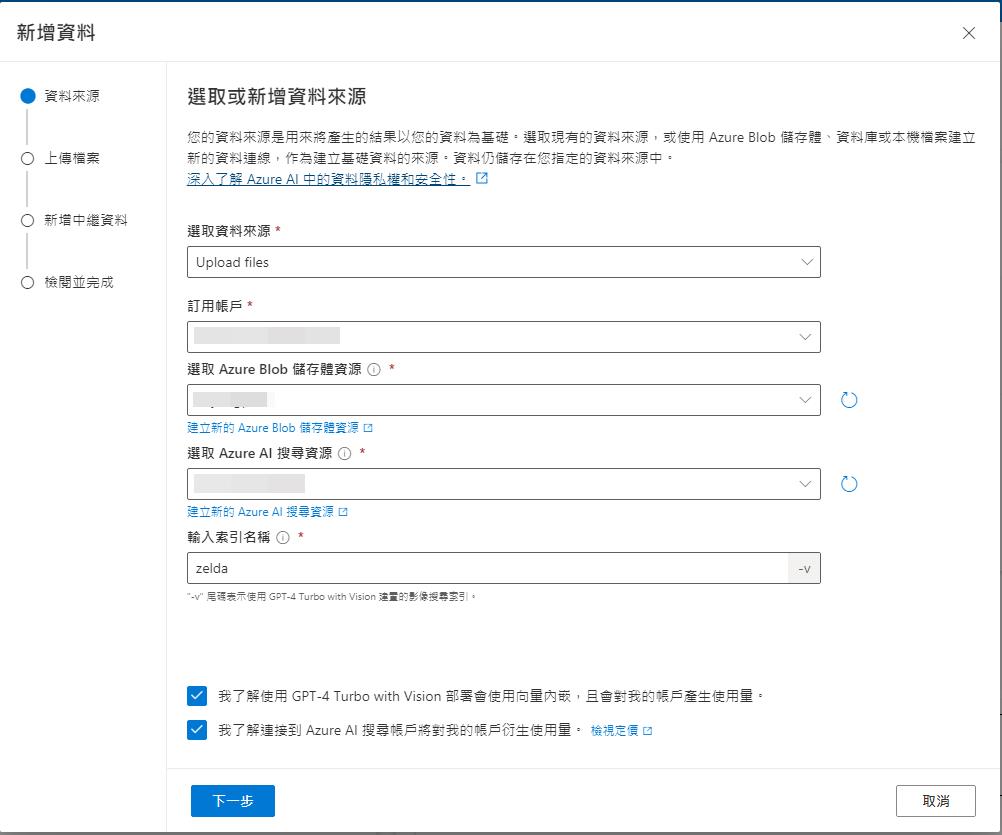
這功能是建置在之前文章「在 Azure OpenAI 使用自己的資料集」介紹過的功能之上,首先我們再來建立我們的資料集,因為有新的功能,可以即時上傳圖片來建立索引,步驟上會比較簡單,就用新的方式來建立資料集。
新增資料集時候選擇 Upload files 並且設定好儲存體跟 Azure Ai Search,這邊注意不能是免費的方案,不然會不給選擇。
再來選擇圖片檔案上傳。
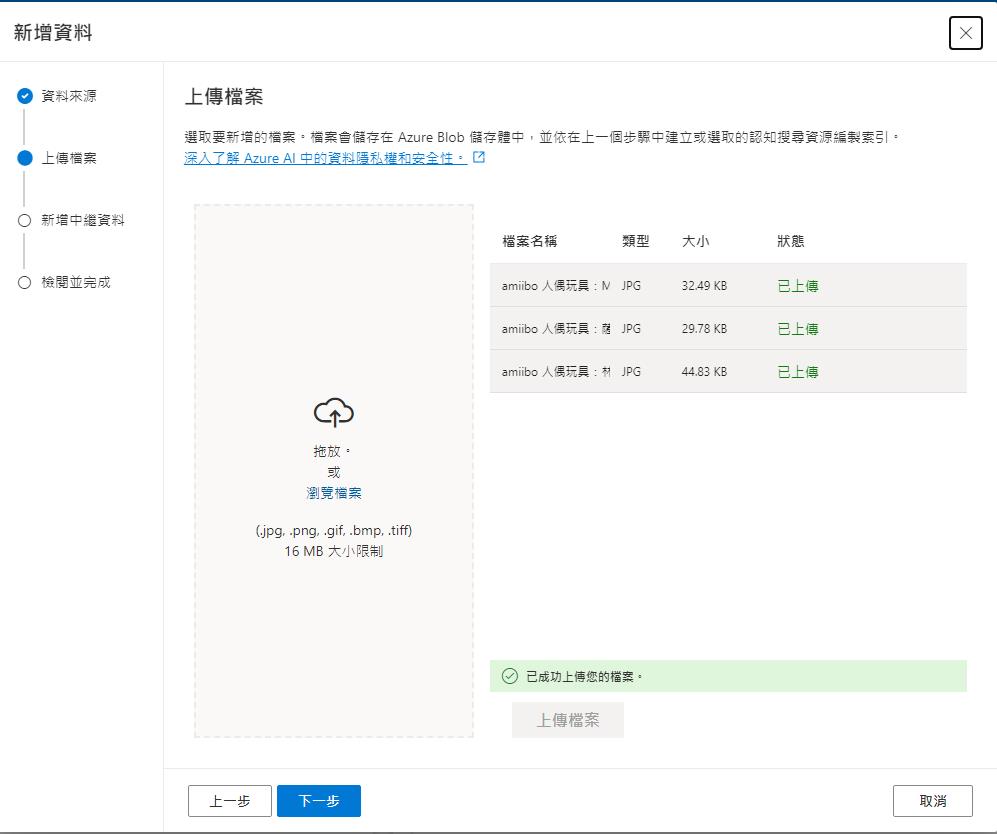
針對每一張圖建立描述,以利後續建立索引使用。
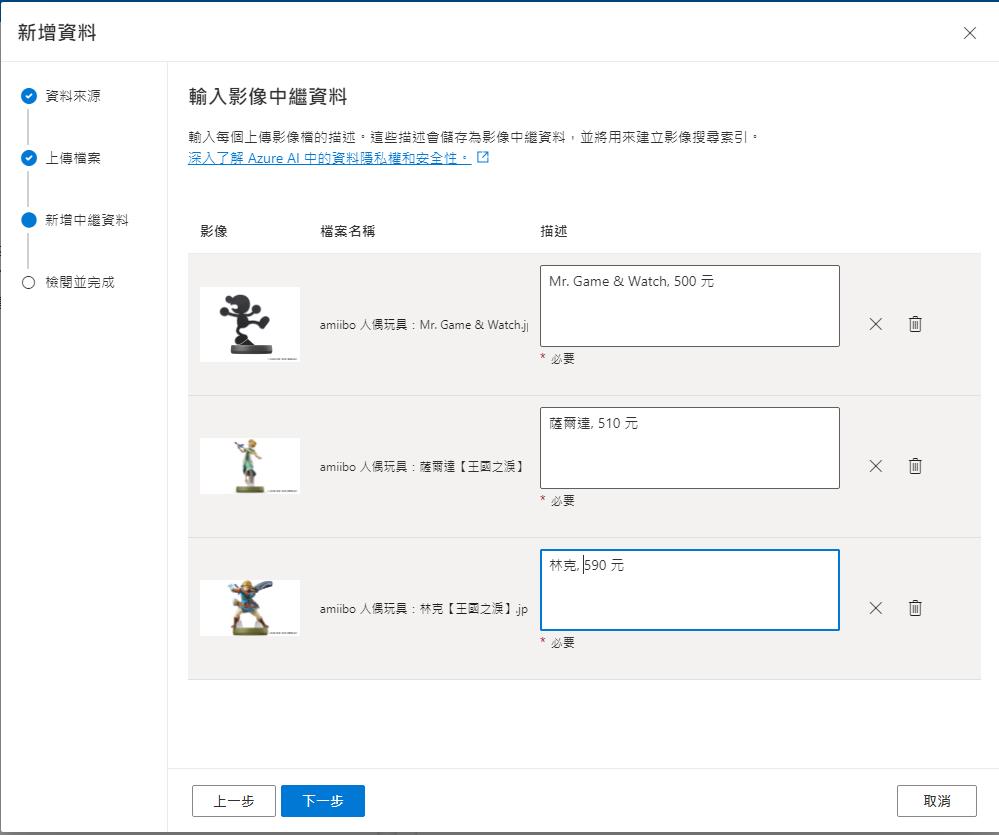
最後確認之後就完成了。
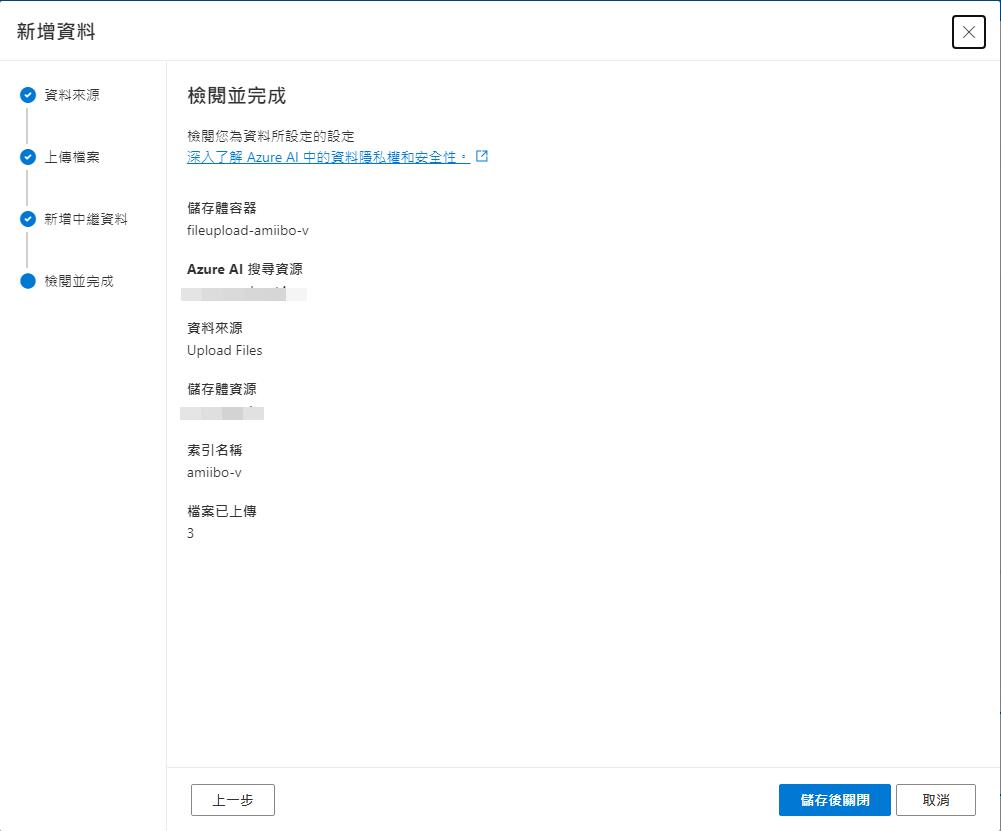
建立之後等待建立索引。
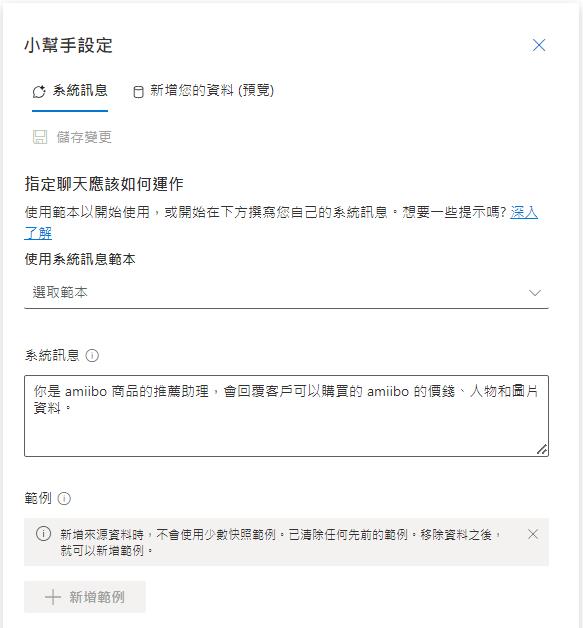
設定他是商品推薦助理,會回應價錢和人物相關資料。
首先測試未開啟增強模式且有設定資料來源的狀態底下,無法正確辨識出人物和推薦結果給我。
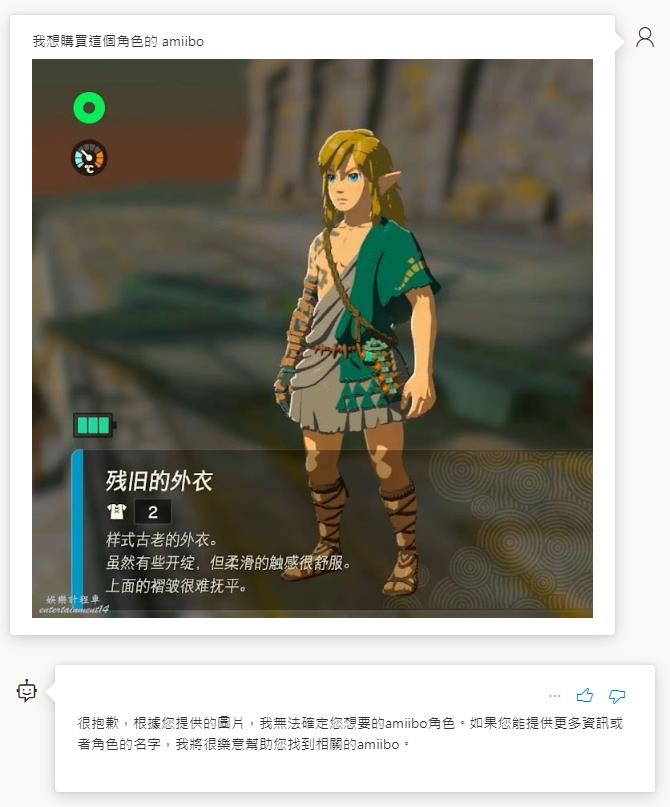
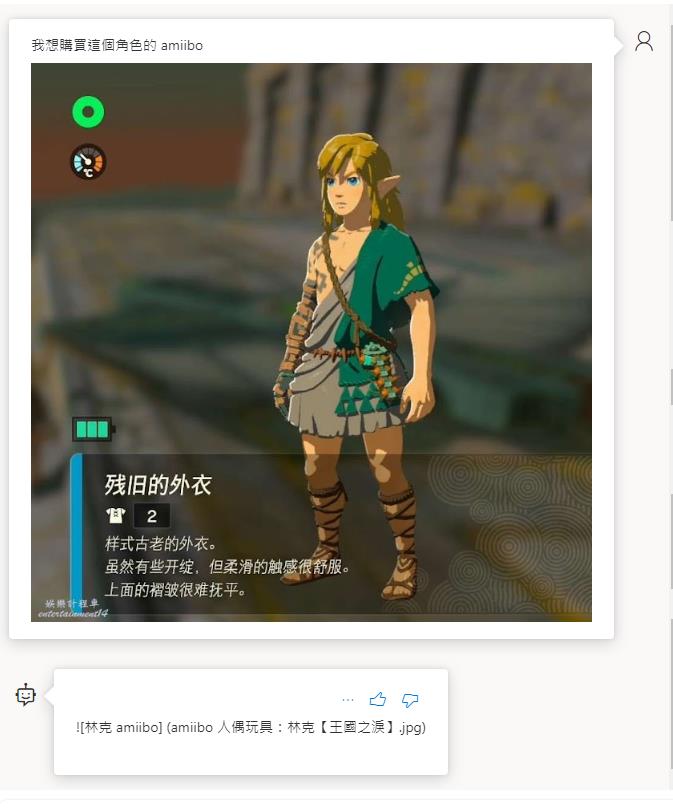
而在開啟增強模式的狀態底下,就可以正確的判斷出來了,不過 UI 有點問題沒正確顯示出來,但是切換成 Json 格式就可以看到是有正確回應結果的。

費用說明
GPT-4 Turbo with Vision 費用和 GPT-4 Turbo 是一致的,也比 GPT-4 還便宜,但是使用上 GPT-4 Turbo 和 GPT-4 Turbo with Vision 會使用到更多的 Token ,所以定價上就設定比較低,但是使用下來費用可能更容易超越 GPT-4 模型。
| Prompt | Completion | |
|---|---|---|
| gpt-4-1106-preview | $0.01 / 1K Tokens | $0.03 / 1K Tokens |
| gpt-4-1106-vision-preview | $0.01 / 1K Tokens | $0.03 / 1K Tokens |
另外要特別提的就是 Tokem 的計算上,圖片會如何計算 Token,在送出圖片資料的時候有一個 detail 參數可以設定,其中值可以是 auto、low、high,這部分可以參考 OpenAI 關於 Vision 模型的 API 說明,而這個值會影響到 Token 的計算。
{
"type": "image_url",
"image_url": {
"url": "{URL}",
"detail": "high"
}
}低解析度 (Low)
在這模式下圖片會用 512*512 的解析度來處理,回應速度上會較快,而每張圖片都只算 85 Tokens。
高解析度 (High)
在高解析的模式下會先縮放圖片再切割成 512*512 區塊來計算 Token,一個區塊是 170 Tokens 然後再加上 85 Tokens。縮放圖片的演算法是先按比例縮放到 2048 x 2048 可以放入此大小的圖片,再把最短邊縮放到 768 然後按比例縮放最長邊,最後就是看這張圖片可以被切割成多少個 512*512 區塊。
用兩個範例來說明:
1024*1024
- 因為低於 2048,所以不做第一步的縮放。
- 將最短邊縮放到 768 會得到 768*768 的圖片。
- 768*768 會需要 4 個 512*512 區塊來函蓋。方便計算的方式是 768 除以 512 無條件近位會得到 2,所以 2*2 會等於 4 個方塊。
- Tokes 數就是 4*170+85=765 Tokens。
2048 x 4096
- 會先按比例縮放成 1024*2048 的圖片。
- 短邊 1024 縮放到 768 會得到 768*1536 的圖片。
- 768*1536 會需要 6 個 512*512 區塊來和。768 除以 512 取整數為 2,1536 除以 512 取整數等於 3,所以 2*3 等於 6 個方塊。
- Token 數就是 6*170+85=1105 Tokens。
而在 Azure 上面額外的增強功能,則是要另外計費,計費項目是屬於其它 Azure AI 服務的費用。
| 功能 | 費用 |
|---|---|
| 光學字符識別(OCR) | $1.50 per 1000 transactions |
| 物件定位(Object Grounding) | $1.50 per 1000 transactions |
| Azure OpenAI on your data with images | $0.10 per 1000 transactions |
| 影片提示功能(Video prompt) | $0.05 per minute for indexing $0.25 per 1000 transactions |
結論
雖然 GPT-4 Turbo with Vision 這個模型還在 Preview 階段,但是效果上還算不錯,再加上 Azure 上面額外的增強功能的結合,可以更快速的完成更多情境,而不用自己再用程式多去處理這些 API 的串接結果的處理,不過在驗證自帶資料的增強效果的時候,製作範例弄了很久都沒有達到像官方範例那麼好的效果,可能是資料不夠多或是情境不夠適合,之後有機會再來多驗證看看了。
參考資料
- New models and developer products announced at DevDay
- Azure AI Vision(Azure Computer Vision)
- 在您的 AI 聊天中使用影像
- GPT-4 Turbo with Vision is now available on Azure OpenAI Service!
- Video Retrieval: GPT-4 Turbo with Vision Integrates with Azure to Redefine Video Understanding
- 搭配視覺使用 GPT-4 Turbo
- 什麼是 Azure OpenAI 服務?
- OpenAI vision



