本文介紹如何寫一段 python 的程式碼來爬取 Google 新聞來使用。
最近有需求要做一隻 Python 爬蟲來抓取新聞,與其到各大網路新聞去抓,乾脆直接把腦筋動到 Google 上,以 Google 抓新聞的管道我看到有兩個,一個是Google search 的新聞頁籤,另一個則是Google 新聞。
Google 新聞平台上沒有更多篩條件,抓下來的資料在時間還有排序上只能完全依照 google 提供的(汗)。所以我最後選擇用 Google Search 的新聞做為資料來源。
不過使用 Goolgle Search 的新聞,發現在網頁點選右鍵檢視網頁原始碼所看到的 html 會與實際爬蟲抓到的不一樣,看起來 Google 針對這部分有把 html 標籤、id、class 等處理過,所以在處理前必須要先了解一下爬蟲抓到的資料結構。
右鍵檢視網頁原始碼看到的 html
<div class="gG0TJc">
<h3 class="r dO0Ag">
<a class="l lLrAF" href="https://newtalk.tw/news/view/2018-03-24/118588" ping="/url?sa=t&source=web&rct=j&url=https://newtalk.tw/news/view/2018-03-24/118588&ved=0ahUKEwimoYXH-YbaAhXLXrwKHSK4AN8QqQIIVCgAMAU">5年21個新創基地
<em>柯文哲</em>:創新是台灣唯一出路</a>
</h3>
<div class="slp">
<span class="xQ82C e8fRJf">新頭殼</span>
<span class="v0c3xd">-</span>
<span class="f nsa fwzPFf">21 小時前</span>
</div>
<div class="st">台北市市長
<em>柯文哲</em>今日出席全國大專院校商業個案大賽,並指出創新是台灣唯一的出路。 圖:翻攝自Flickr/zhenghu feng開放權限. 台北市市長
<em>柯文哲</em>今(24)日出席全國大專院校商業個案大賽( ATCC ),除與企業領袖對談外,更於致詞時表示,計劃未來每年開設2到3個新創基地,預計未來5年內,北市最少會有21個新創基地。 此次第16 ...</div>
</div>
爬蟲抓到的 html
<div class="g">
<table>
<tr>
<td valign="top" style="width:516px">
<h3 class="r">
<a href="/url?q=https://newtalk.tw/news/view/2018-03-24/118588&sa=U&ved=0ahUKEwjx29Dv-obaAhUDF5QKHbDFDdMQqQIIPSgAMAU&usg=AOvVaw1gl8zS6uqDn2yMujpzFwem">5年21個新創基地
<b>柯文哲</b>:創新是台灣唯一出路</a>
</h3>
<div class="slp">
<span class="f">新頭殼 - 21 小時前</span>
</div>
<div class="st">台北市市長
<b>柯文哲</b>今日出席全國大專院校商業個案大賽,並指出創新是台灣唯一的出路。 圖:翻攝自Flickr/zhenghu feng開放權限. 台北市市長
<b>柯文哲</b>今(24)日出席全國大專院校商業個案大賽( ATCC ),除與企業領袖對談外,更於致詞時表示,計劃未來每年開設2到3個新創基地,預計未來5年內,北市最少會有21個新創基地。 此次第16 ...
</div>
</td>
<td valign="top" style="padding:2px 0 0 8px;font-size:77%;text-align:center">
<a href="/url?q=https://newtalk.tw/news/view/2018-03-24/118588&sa=U&ved=0ahUKEwjx29Dv-obaAhUDF5QKHbDFDdMQpwIIPjAF&usg=AOvVaw05tVqqiImowjzQaHl9w5ZR">
<img class="th" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSVlSNRzZj54mO-2pD3RbsjuEvv6PKjzWVWuqLLh_74N0DtUpAmt-jK8_ttH7HH8MPqE9DHGyI"
border="1">
</a>
<div class="f">新頭殼</div>
</td>
</tr>
</table>
</div>
Python 程式碼
import requests
from bs4 import BeautifulSoup
from urllib import quote
import urlparse
search_list = []
keyword = quote('"柯文哲"'.encode('utf8'))
res = requests.get("https://www.google.com.tw/search?num=50&q="+keyword+"&oq="+keyword+"&dcr=0&tbm=nws&source=lnt&tbs=qdr:d")
# 關鍵字多加一個雙引號是精準搜尋
# num: 一次最多要request的筆數, 可減少切換頁面的動作
# tbs: 資料時間, hour(qdr:h), day(qdr:d), week(qdr:w), month(qdr:m), year(qdr:w)
if res.status_code == 200:
content = res.content
soup = BeautifulSoup(content, "html.parser")
items = soup.findAll("div", {"class": "g"})
for item in items:
# title
news_title = item.find("h3", {"class": "r"}).find("a").text
# url
href = item.find("h3", {"class": "r"}).find("a").get("href")
parsed = urlparse.urlparse(href)
news_link = urlparse.parse_qs(parsed.query)['q'][0]
# content
news_text = item.find("div", {"class": "st"}).text
# source
news_source = item.find("span", {"class": "f"}).text.split('-')
news_from = news_source[0]
time_created = str(news_source[1])
# add item into json object
search_list.append({
"news_title": news_title,
"news_link": news_link,
"news_text": news_text,
"news_from": news_from,
"time_created": time_created
})
以下為幾個關鍵語法
url encode
keyword = quote('"柯文哲"'.encode('utf8'))
中文字放到網址內需先進行編碼轉換,只要利用 urllib 的 quote 即可輕鬆轉換。
findAll and find
items = soup.findAll("div", {"class": "g"})
news_title = item.find("h3", {"class": "r"}).find("a").text
指定要查詢的標籤及其要篩選的屬性和條件, find 和 findAll 的差別在於前者為回傳一筆,後者為取得多筆資料’,而使用 .text 可以取得其內容。
get url query
parsed = urlparse.urlparse(href)
news_link = urlparse.parse_qs(parsed.query)['q'][0]
使用 urlparse 解析 url 以及 parse_qs 函數擷取 query 參數,拿到的結果會是一個陣列所以要指定 index 來取得值。
如何避免爬蟲被阻擋?
其實 google news 是不允許爬蟲的,所以經歷過很多次的請求後,很可能會發現爬蟲被阻擋而要不到資料,這時候就需要設定 User-Agent (UA) 來假裝是透過瀏覽器做請求。
這是 MDN 上 User-Agent 的解釋:
用戶代理(User-Agent)請求標頭(request header)含有能令網路協議同級層(peer)識別發出請求的軟體類型或版本號、該軟體使用的作業系統、還有軟體開發者的字詞串。
想知道自己的 UA ,可以透過 Chrome 開發者工具上的 Network ,從任一筆請求的 Request Headers 找到。
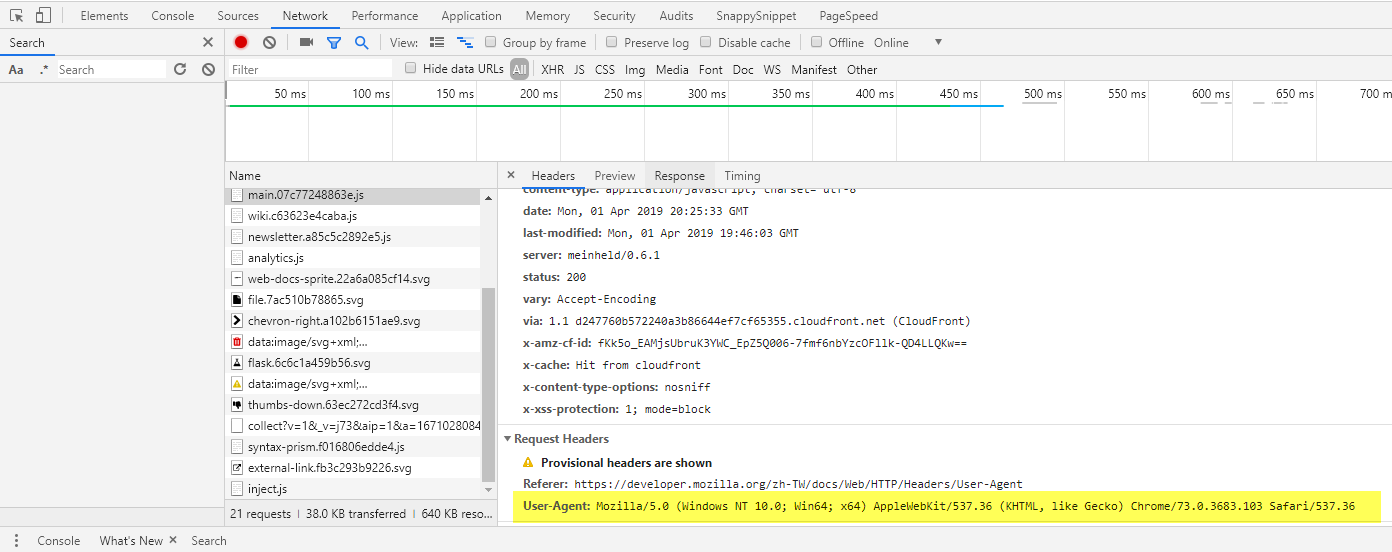
要設定代理很簡單,只要在使用 requests.get(request_url) 時,於後面指定 headers 替換掉 UA,當然可以自己選擇要使用的 UA。
user_agent = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
res = requests.get(request_url, headers=user_agent)
試試看吧! 希望對於學習爬蟲及需要爬 Google News 的人有一些幫助。