自 SQL Server 2016推出 R服務之後,Revolution團隊在SQL 2017版本中,除了將原先的服務改名為 Machine Learning Services(為了納入對 Python語言的支援),更強化了對 R語言的支援與 Pre Training model的數量。本篇將簡單地介紹 R語言的語法,以及會用GLM 一般線性模型(可歸類為廻歸分析)來示範,讓熟悉 T-SQL的 DBA也能用 SQL Server做機器學習
接續上一篇 SQL2017 R入門,我們將會在 SSMS中實作,以前需要在 R Studio才能做的事情。詳細的操作步驟可以參考官網的說明。若想了解如何用 PowerShell 來做 R語言的機器學習,請參考另外一篇介紹預防性維修的案例。
為什麼我的要選 GLM 這個統計類別模型開始?因為 R語言在統計領域已經發展多年,所以選擇這個在學界已有豐富範例與相關文件的模型,最適合不過了。
講到統計學,學界中有一個很有趣的迴歸分析應用,就是鐵達尼號的票價與生存率分析,預告一下,下次我來介紹一下 Azure Machine Learning Gallery 這個有趣的題目,再配合 Excel 來呼叫雲端上的 ML模型,只需填入你的資料,就可以讓你與歷史重大事件來互動
首先要認識原生的 R,在不考慮第三方工具的條件下 Rgui.exe是它相當於 SSMS的基本配備,它的路徑在 C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\R_SERVICES\bin\x64
 若是你偏好 Command Line(CLI)在上一層目錄還有一個 Rscript.exe(並非一定要用64位元,32位元也可以)
若是你偏好 Command Line(CLI)在上一層目錄還有一個 Rscript.exe(並非一定要用64位元,32位元也可以)
先跳脫框架,用指令來畫張圖,畢竟 R語言是吃統計的奶水長大的
z <- seq(-3,3,.1)
d <- dnorm(z)
plot(z,d,type="l")
title("The Standard Normal Density",col.main="cornflowerblue")
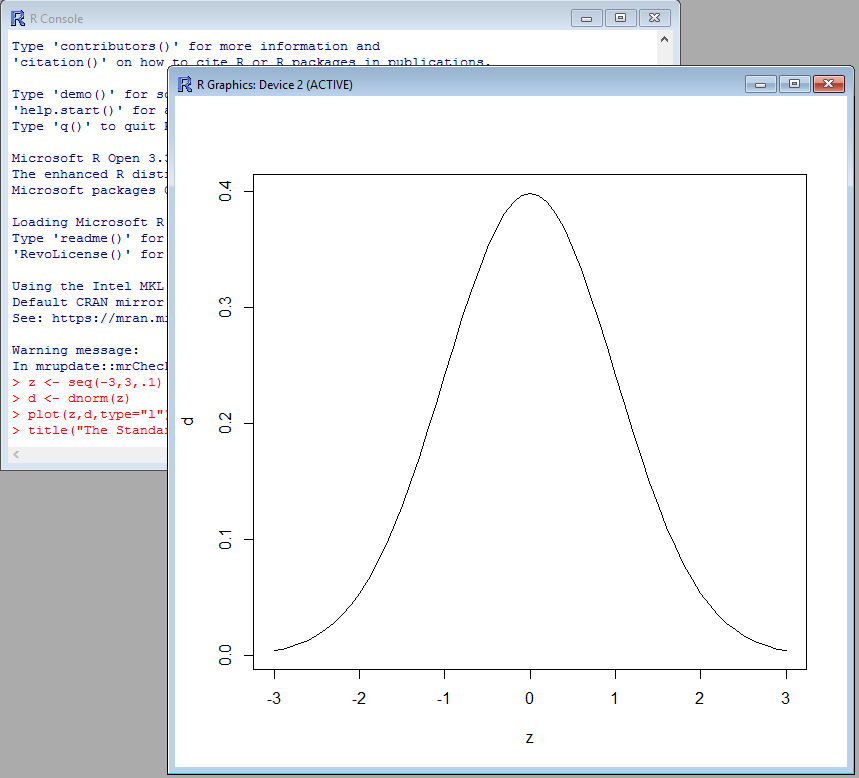 上述指令中的第一行,是先準備一些-3,-2.9,-2.8以0.1的間距,一直到3.0的61個數據。
上述指令中的第一行,是先準備一些-3,-2.9,-2.8以0.1的間距,一直到3.0的61個數據。
第二行是透過 dnorm 密度常態分配的函式,把數據打散
第三行是把X,Y軸的座標,以及圖型的類型l(line)指定後,讓plot繪圖函式把圖畫出來。
第四行則是給它一個標題
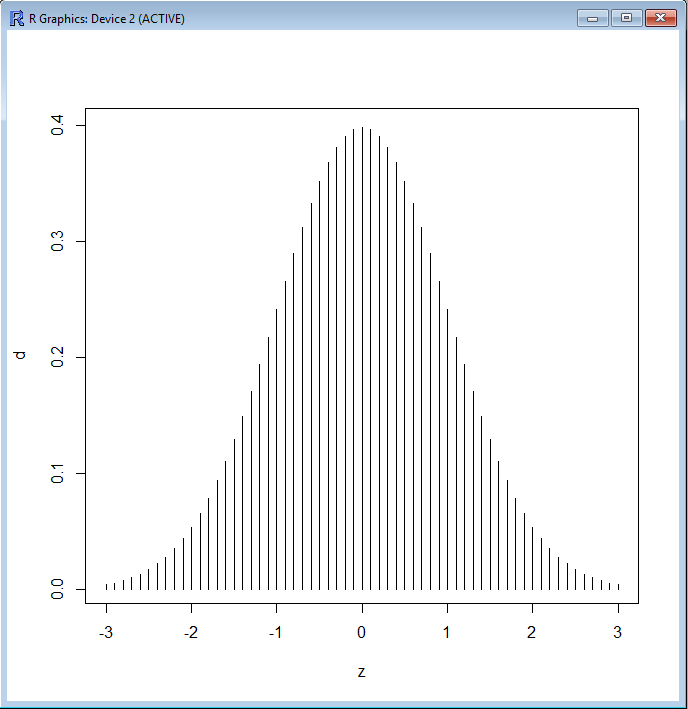
其中,類型除了l(line線)還支援p(point點)、b(both點線)、c(b類型中的線)、o(overplotted重疊點)、s(stair step階梯)、h(histogram直方圖表示密度的垂直線)、n(no不畫圖),以下我們示範把type改成h(直方圖)再畫一次
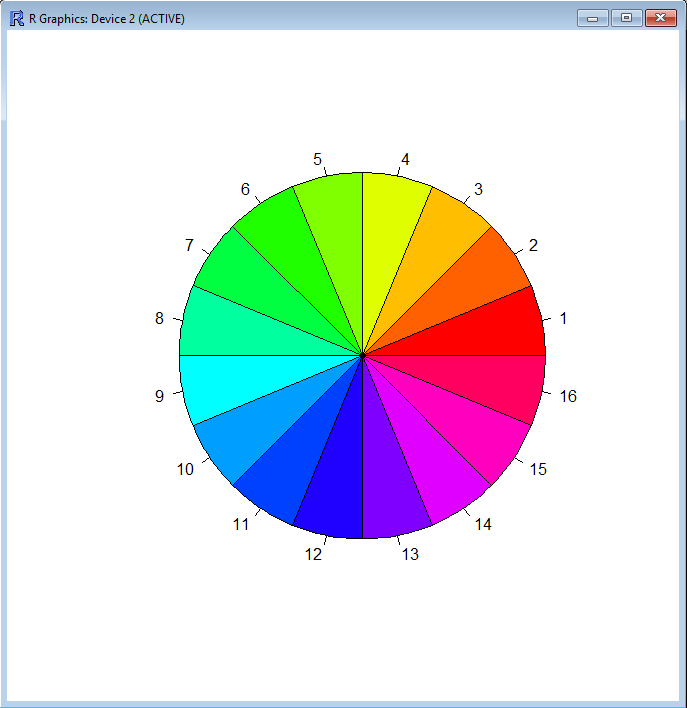
 接下來,示範一個全彩畫圖,pie(rep(1,16),col=rainbow(16)),透過 repeat從1到16 給定至Pie,再指定彩虹顏色,是不是很漂亮?
接下來,示範一個全彩畫圖,pie(rep(1,16),col=rainbow(16)),透過 repeat從1到16 給定至Pie,再指定彩虹顏色,是不是很漂亮?
 另外,它還有一些向量 Concatenate、數學(加、減、乘、除、對數、開根號…),因為這篇是以 T-SQL為主,就先略過不介紹…
另外,它還有一些向量 Concatenate、數學(加、減、乘、除、對數、開根號…),因為這篇是以 T-SQL為主,就先略過不介紹…
言歸正傳,讓我們再回到 GLM 一般線性模型,若你有時間,可以透過 help(glm)指令,叫出官方文件來參考
 在官方文件有提到GLM的參數有19個(包含Optional),但其實必要的參數只有 formula, family, data 就可以運作了。
在官方文件有提到GLM的參數有19個(包含Optional),但其實必要的參數只有 formula, family, data 就可以運作了。
formula是公式,family是透過你要解決的問題決定資料的分佈(例如要解決二選一的問題,就選二項式分配),data你可以使用自帶資料或是應用 R語言的範例資料集
** family有六種,包含了二項式分配、高斯分配、反高斯分配、gamma分配…許多選擇。細節可以利用 help(family)指令來做進一步的研究;R語言內建的範例資料集有大有小約有50個左右,你可以透過 library(help="datasets")來取得相關的資訊
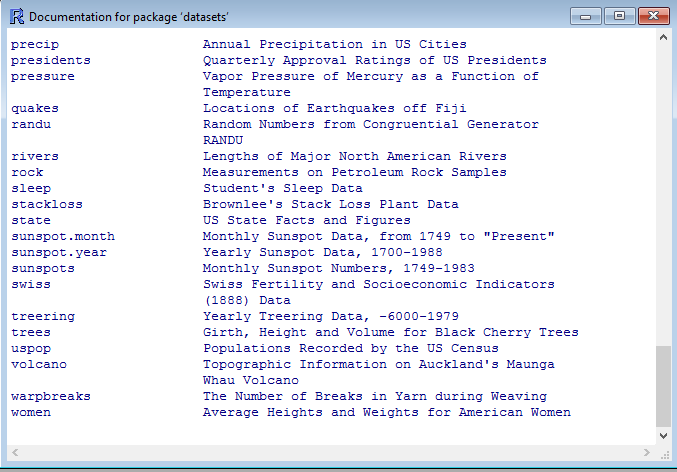 首先我們要建立 Schema,才能把範例資料集匯入SQL Server中,所以我們把這個汽車相關的 MTCars Table建立起來,裡面的欄位包含了mpg(英里/加侖)、cyl(氣缸數)、disp(排氣量)、hp(馬力)、drat(後輪軸比)、wt(重量)、qsec(加速性能)、vs(發動機類型)、am(手自排)、gear(前進檔位數)、carb(化油器數)…等
首先我們要建立 Schema,才能把範例資料集匯入SQL Server中,所以我們把這個汽車相關的 MTCars Table建立起來,裡面的欄位包含了mpg(英里/加侖)、cyl(氣缸數)、disp(排氣量)、hp(馬力)、drat(後輪軸比)、wt(重量)、qsec(加速性能)、vs(發動機類型)、am(手自排)、gear(前進檔位數)、carb(化油器數)…等
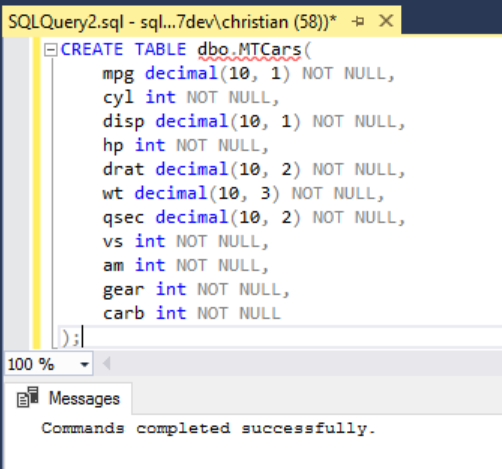 接著,匯入範例資料集到剛建好的 Table中
接著,匯入範例資料集到剛建好的 Table中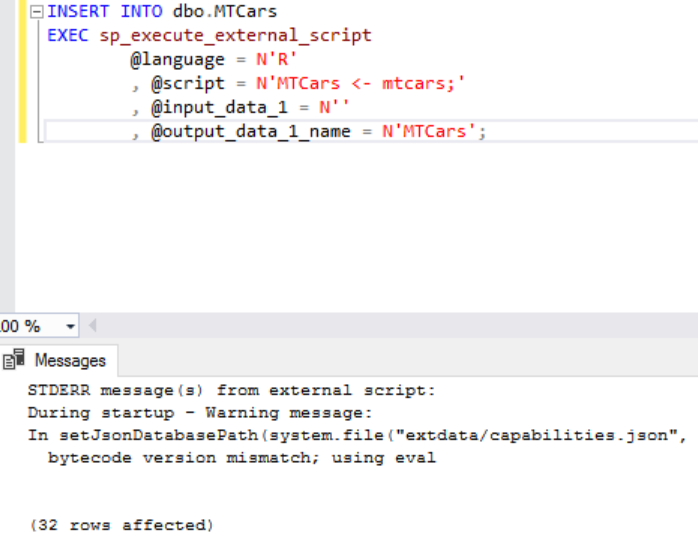 我們將MTCars的資料,加上關係式:am ~ hp + wt,以及二項式分配,填入GLM 這個一般線性模型的建立函式中。其中的應變數是汽車的變速器 (am) ,將會相依於馬力 (hp) 和重量 (wt)二個自變數。
我們將MTCars的資料,加上關係式:am ~ hp + wt,以及二項式分配,填入GLM 這個一般線性模型的建立函式中。其中的應變數是汽車的變速器 (am) ,將會相依於馬力 (hp) 和重量 (wt)二個自變數。
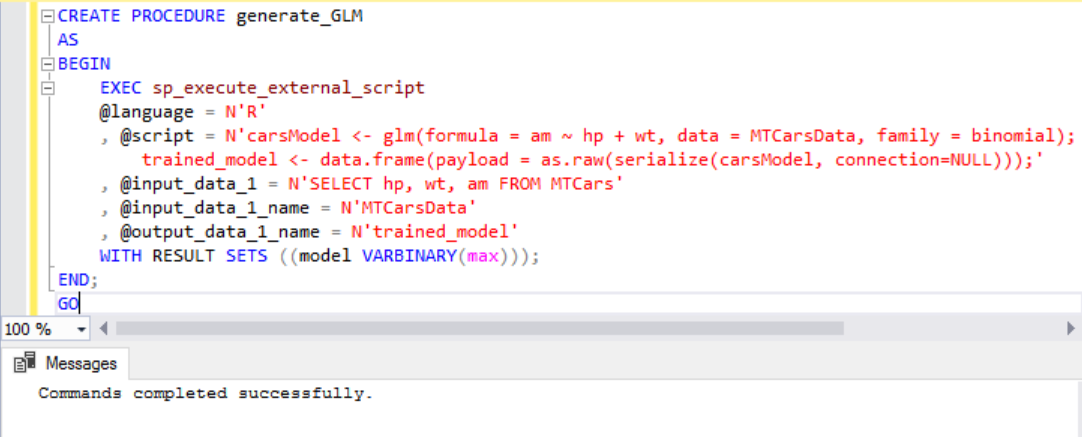 接下來,儲存模型,以便您可以重新定型或預測中使用它。 R 套件如果會建立模型,其輸出通常會是「二進位物件」。 因此,將模型儲存的資料表必須提供的資料行varbinary (max) 型別。
接下來,儲存模型,以便您可以重新定型或預測中使用它。 R 套件如果會建立模型,其輸出通常會是「二進位物件」。 因此,將模型儲存的資料表必須提供的資料行varbinary (max) 型別。
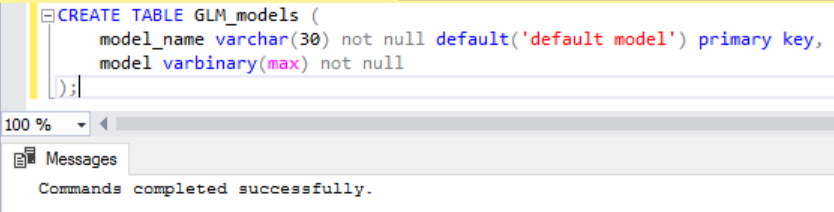 基礎於剛才建好的 GLM模型 Schema,我們就可以執行這個模型的訓練,並且將其結果儲存在 Table中
基礎於剛才建好的 GLM模型 Schema,我們就可以執行這個模型的訓練,並且將其結果儲存在 Table中
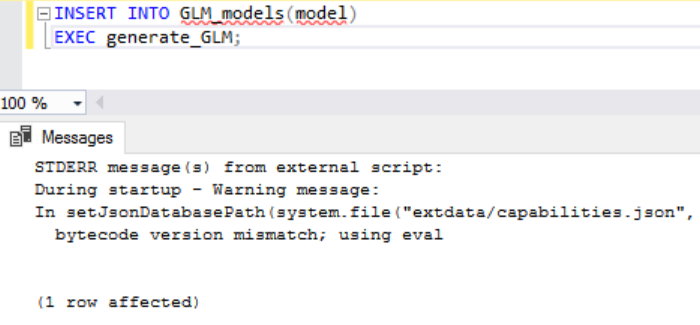 若你想再次訓練這個模型,系統將會報錯,所以你應該要學會,如何修改模型的名稱,以下提供一個用當前時間來避免重覆的範例語法
若你想再次訓練這個模型,系統將會報錯,所以你應該要學會,如何修改模型的名稱,以下提供一個用當前時間來避免重覆的範例語法
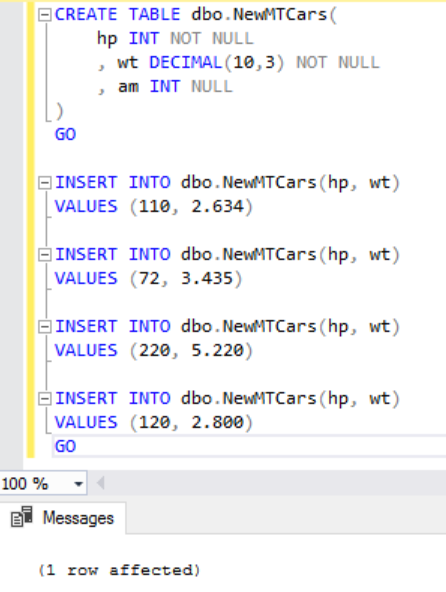
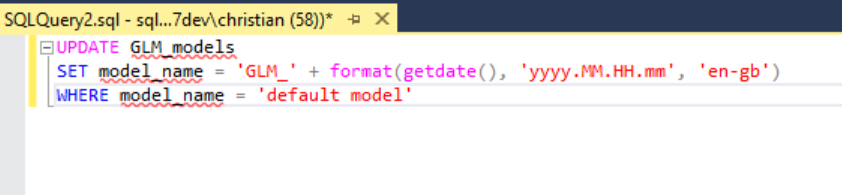 有了訓練資料集,接下來我們還需要測試資料集,因此我們來建立 NewMTCars Table
有了訓練資料集,接下來我們還需要測試資料集,因此我們來建立 NewMTCars Table
 由於在 dob.GLM_models 資料表中,可能會包含數個用不同條件(參數、演算法、資料集)訓練而成的模型。所以當我們要進行預測時,一定要指名要用哪個模型?要使用哪個測試資料集?要使用哪個相容於這個模型的預測函數?所以 default model 是我們要採用的模型名稱,NewMTCars 是我們要使用的測試資料集, predict(model, dataset, response類別) 是我們所採用的預測函數
由於在 dob.GLM_models 資料表中,可能會包含數個用不同條件(參數、演算法、資料集)訓練而成的模型。所以當我們要進行預測時,一定要指名要用哪個模型?要使用哪個測試資料集?要使用哪個相容於這個模型的預測函數?所以 default model 是我們要採用的模型名稱,NewMTCars 是我們要使用的測試資料集, predict(model, dataset, response類別) 是我們所採用的預測函數
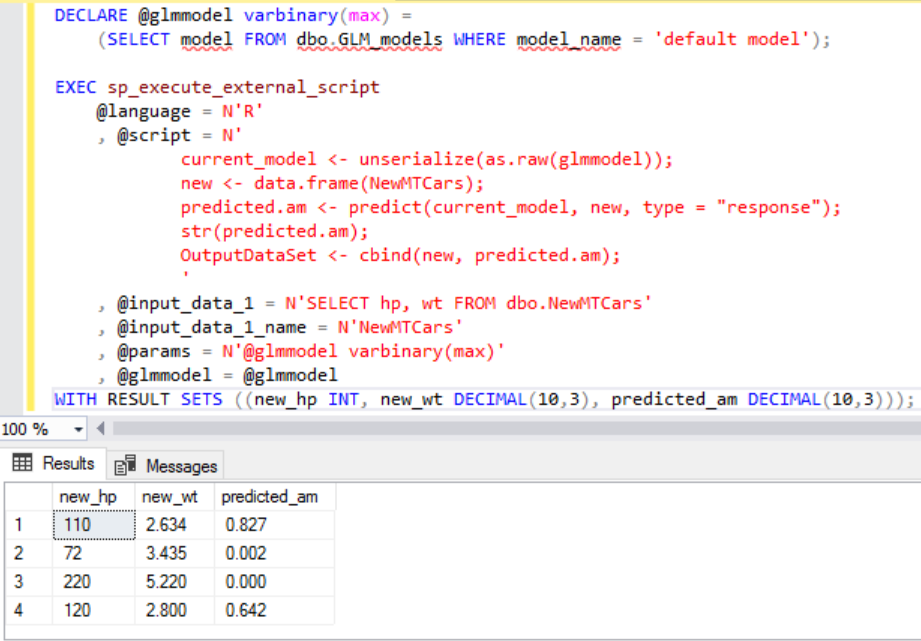 我們分解動作整個預測運行的細節,先透過 select ... where model_name 陳述式,從 GLM_models 資料表取得所需的模型,並傳遞它做為輸入參數。
我們分解動作整個預測運行的細節,先透過 select ... where model_name 陳述式,從 GLM_models 資料表取得所需的模型,並傳遞它做為輸入參數。
當我們從資料表擷取模型之後,對這個模型呼叫 unserialize 函數。
再搭配適當參數在 predict 函數,並提供新的輸入資料集,套用至這個模型。
str函式會加入在測試階段中(Debug用途),若要你對於資料結構描述已經能掌握,將來就可以移除 str的陳述式。
在 R語言中,顯示結果的欄位 Header並非必要,在這裡使用了 WITH RESULTS 子句來強化結果的可讀性
最後 R 透過馬力與重量的數值,幫我們預測出這款車會是手排還自排?
結論:透過 SQL Server與 R的整合,我們可以實現 in-database analysis的目標,以較經濟的持有成本、提便更大的調度資源、高效地 ML運算(支援多執行緒)、在一台伺服器可以搞定…等優勢
李秉錡 Christian Lee
Once worked at Microsoft Taiwan