Custom Vision是Cognitive services 其中一項服務,比較不同的是它可以讓我們自行訓練自已的圖集,並且轉出視覺辨識模型,本篇要試著以Azure Custom Vision 服務訓練專屬的Model,並將Model匯出,再以ML.NET轉化為ML.NET的Model格式,於地端的應用直接使用Model進行推測。
讓我們以近期比較夯的題材-口罩為例,整個過程大致分為以下程序
- 首先使用Custom Vision服務,訓練圖集,分為帶口罩、未帶口罩二種分類
- 轉出TensorFlow 模型
- 使用ML.NET將TensorFlow 模型轉為ML.NET模型
- 使用ML.NET將模型直接納入應用,實現離線端的本地端應用
Let go !!!
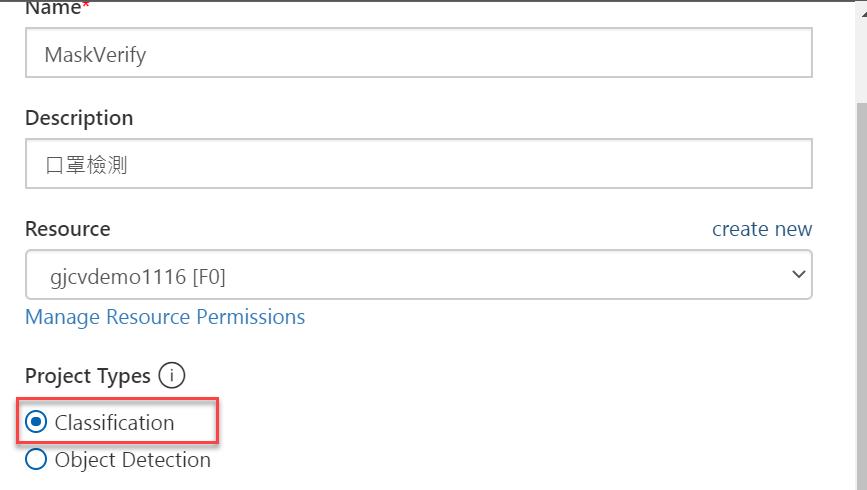
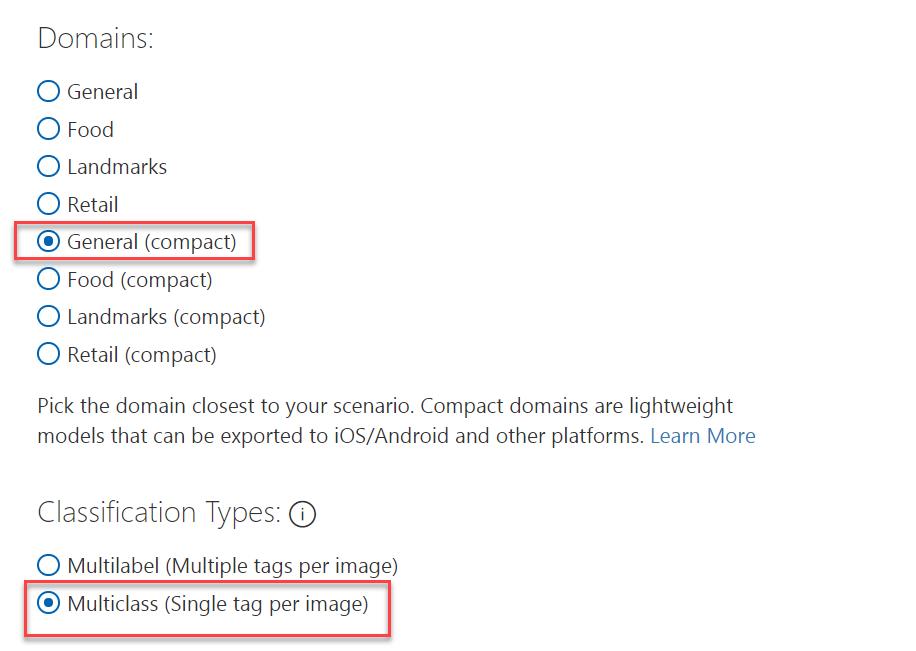
首先使用Custom Vision服務,資料集的部份,這裡我直接借用尹相志老師釋出的公開資料集,帶口罩及未帶口罩隨機挑選20張左右的圖片,合計約40張左右,由於我們要做的是判斷有沒有帶口罩,是屬於影像分類,因此在建立Custom Vision服務時,請選擇Classification,並且我們的標記每張圖片只會有一個,所以在標記類型選擇的是Multiclass(Single tag per image),至於Domains的選項就選用General(若有你的使用情境有合適的預設類別,就選用合適的Domain)。
當建立Custom Vision服務時,由於會藉由Azure雲端環境資源做模型訓練,因此建立服務過程會需要連接Azure訂閱帳戶,並且連帶建立相關的服務
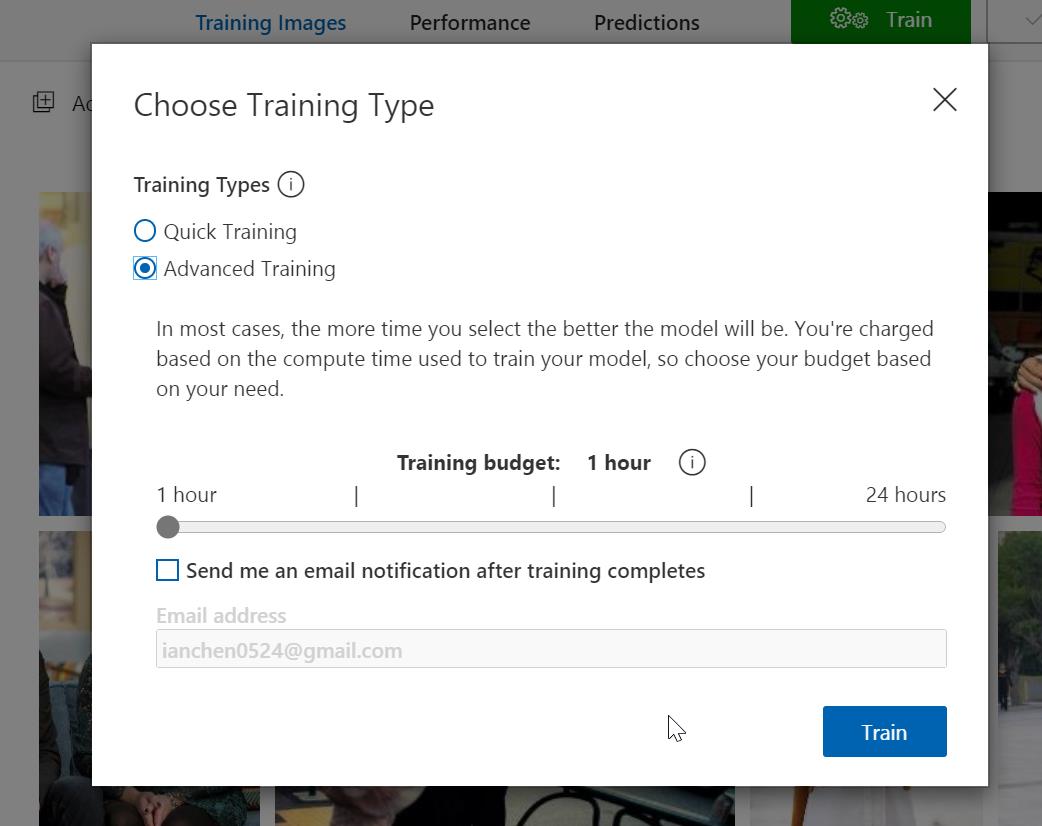
當完成標注後,就可以直接做模型的訓練,在這裡你可以選擇快速訓練,或是較精準的進階訓練,進階訓練是以小時起跳,一般來說會建議用進階訓練,如果不趕時間的話,一旦訓練完成,接著就是做發佈的動作,我們才能夠轉出模型。
在轉出模型的部份,ML.NET支援可以轉化TensorFlow的模型,因此我們選擇轉出TensorFlow格式的模型,。
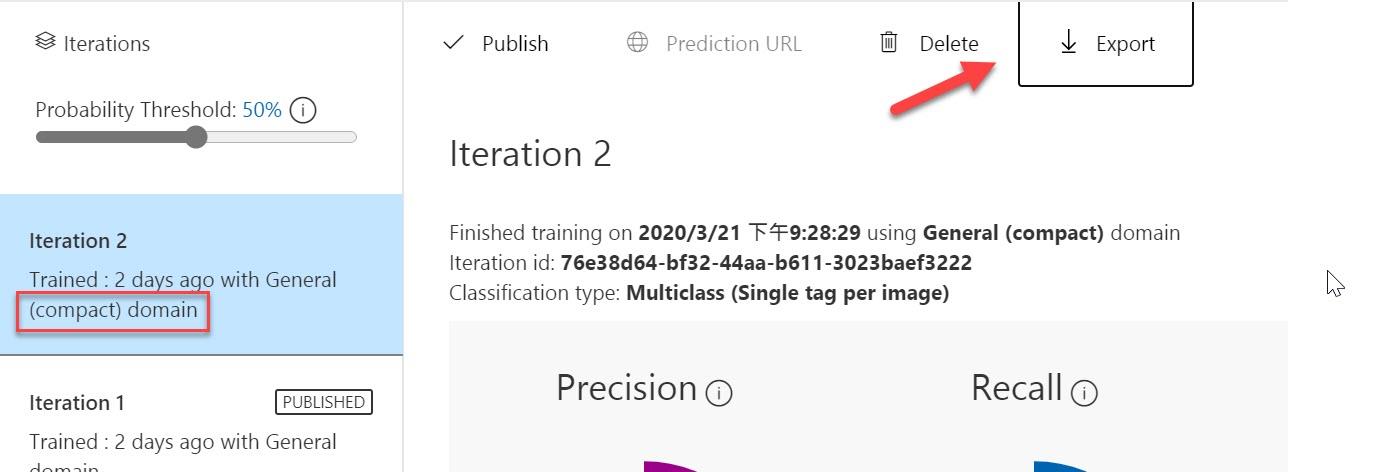
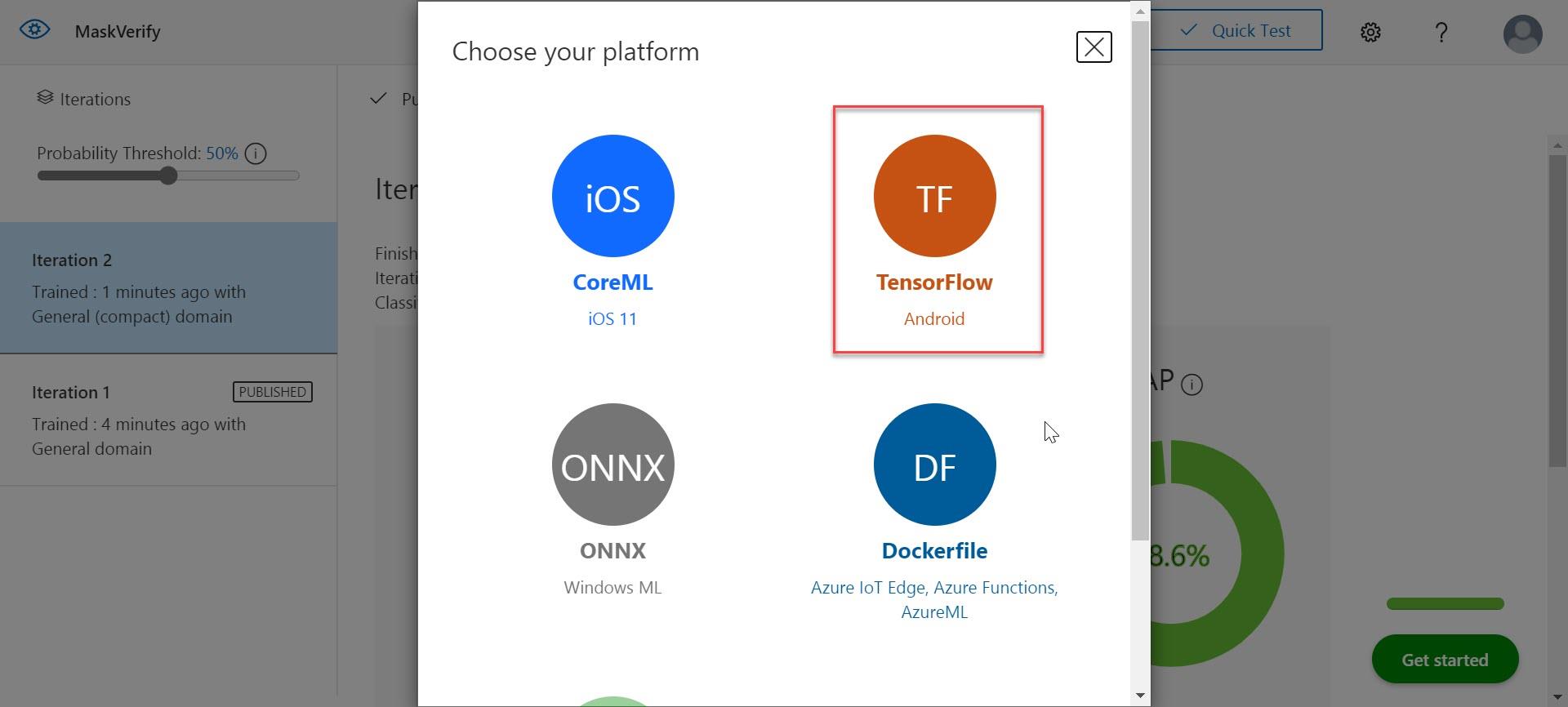
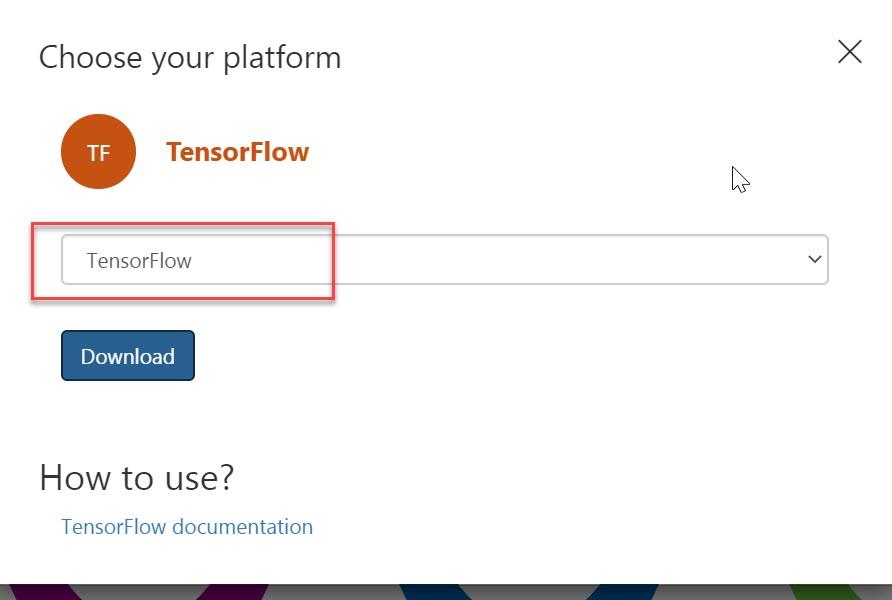
這裡要注意是,當你在訓練模型時,如果一開始Custom Vision服務並沒有選擇(compact)版本,那麼便不會有export功能,不過也不用担心,你可以進入設定重新調整後再做訓練即可。
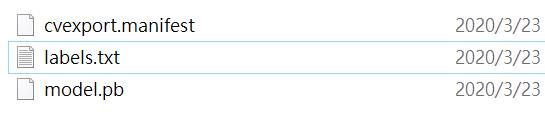
轉出後的模型下載下來會是一個zip壓縮檔,必須解開它,裡面包含了3個檔,別是一個labels.txt(放置我們的標注)、一個manifest描述檔、一個就是TensorFlow模型檔model.pb。
以上的過程,就是我們第1~2步;
接著就是如何使用ML.NET來處理轉出的模型,首先建立二個主控台應用程式,一個是用來把TensorFlow模型檔model.pb轉為ML.NET模型檔,另一個專案則是用來示範應用程式端,這裡我採用.NET Core的版本,並且這二個專案必須分別安裝以下套件:
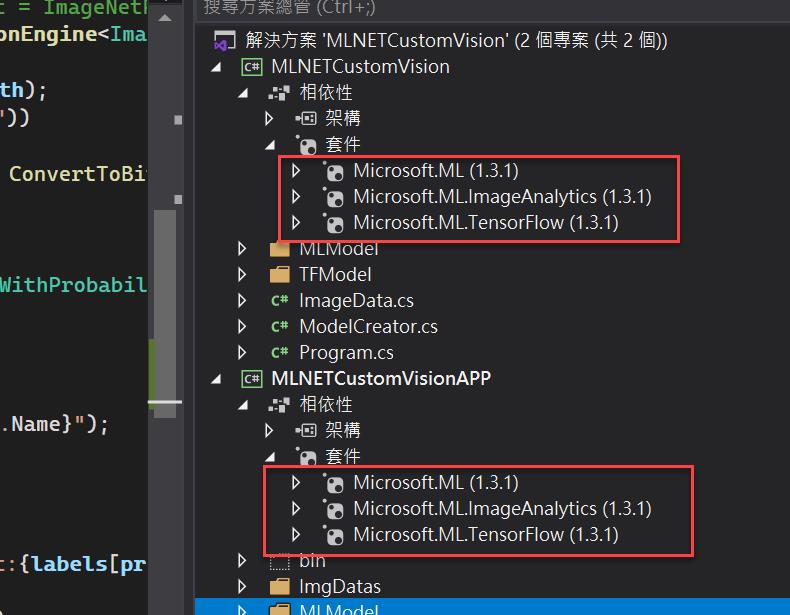
讓我們先來看如何利用ML.NET把TensorFlow模型檔model.pb轉為ML.NET模型檔,在這裡我先建立一個TFModel目錄,放置由Custom Vision匯出的三個檔案,另外再建立MLModel目錄,其作用是用來放置待會由ML.NET轉換過後的Model。
接著我們建立ImageData類別,並且設置尺吋為24*24(這個設定值待會後面會說明如何得知)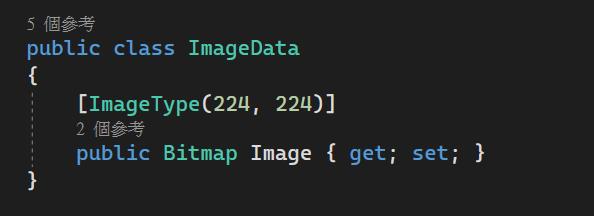
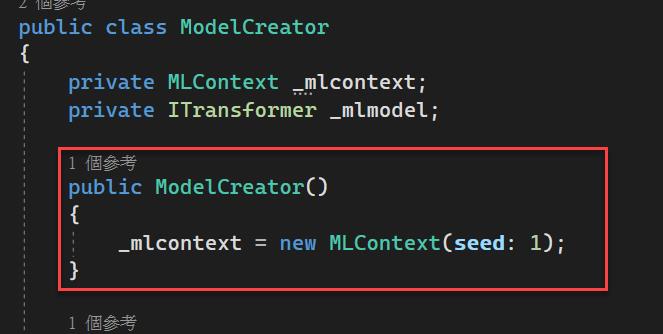
再來建立一個ModelCreator類別,放置轉模型用的程式碼,使用ML.NET的主軸基本上都是由MLContext物件開始,所以在ModelCreator建構子裡建立了MLContext物件。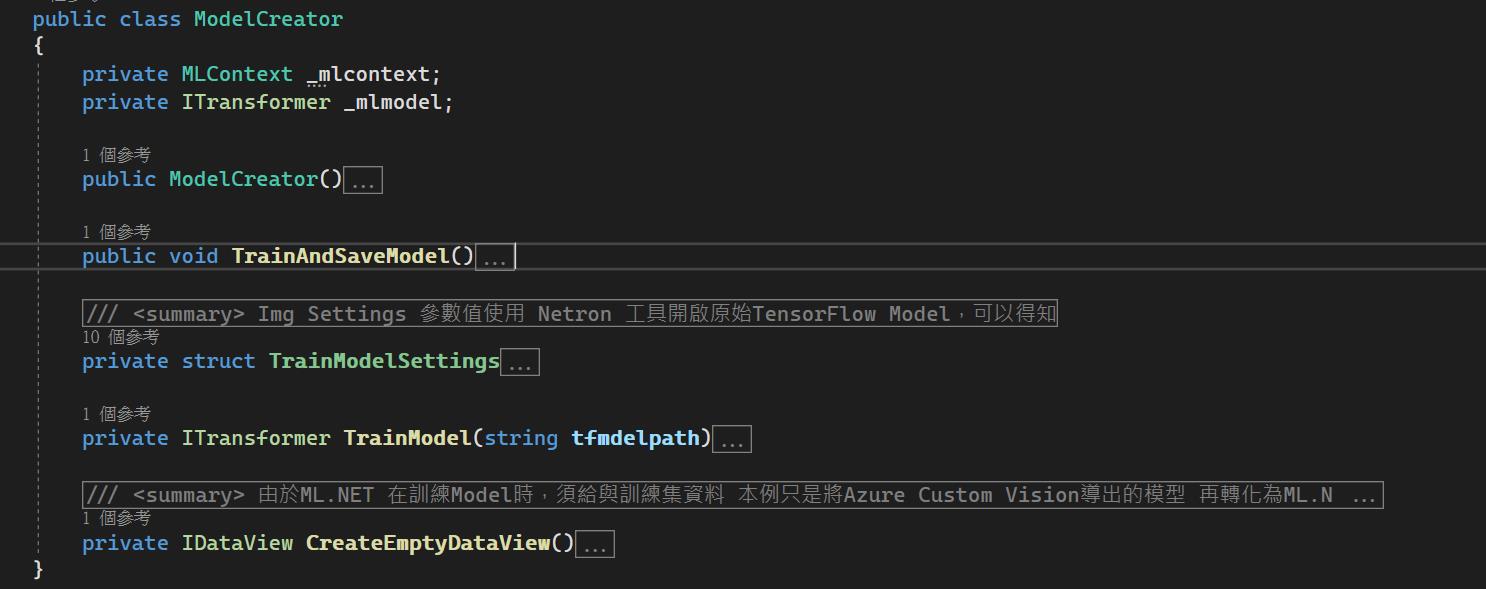
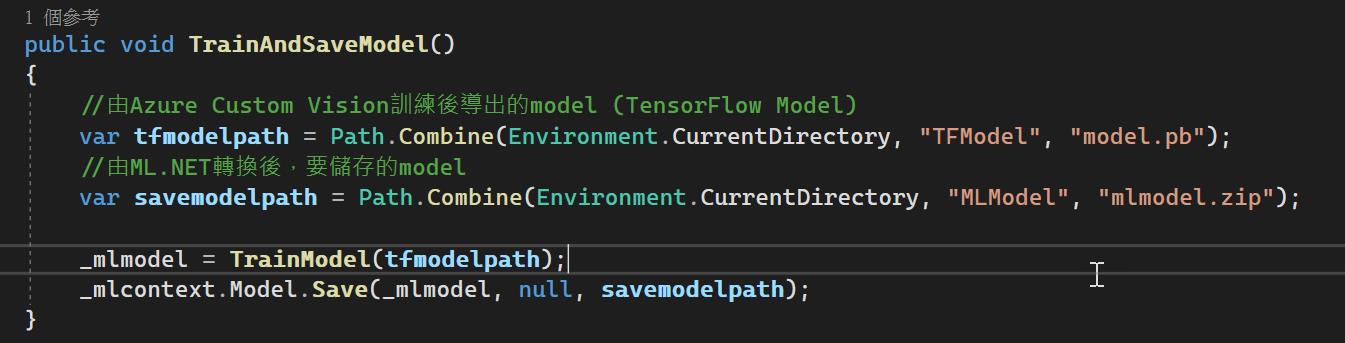
TrainAndSaveModel方法,做為主要呼叫入口,設定好原始TensorFlow Model檔案位置,以及由ML.NET轉換後,要儲存的model位置
TrainModel方法,主要邏輯所在,設置ML.NET的pipeline,並呼叫Fit方法,轉出ML.NET模型,這裡會使用到一些參數值,而這些參數值我們必須打開原始的TensorFlow Model檔案才能得知。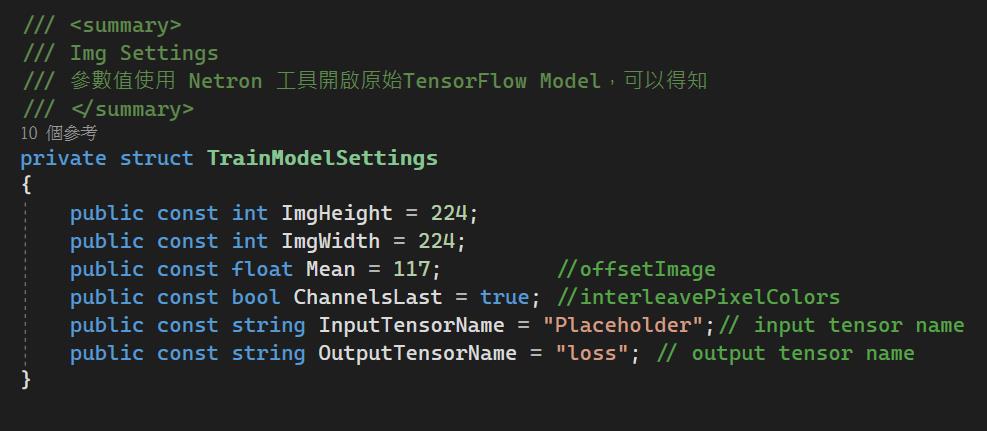
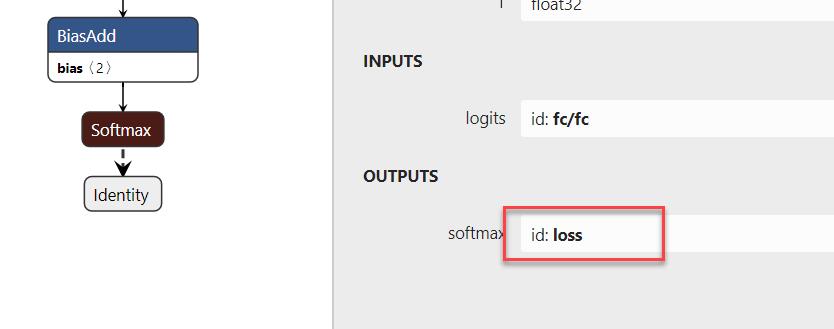
為了要能取得TensorFlow Model參數值,我們需要借由一個工具來幫忙,可以直接使用線上版(https://lutzroeder.github.io/netron/)或是下載安排APP(https://github.com/lutzroeder/netron)都可以,這裡我們必須找到幾個必要參數,inputs(224*244,變數名稱為Placeholder),output(變數名稱為loss),事實上基於ImageNet預訓練的model,圖形大小就是224*224,offset value 則為117。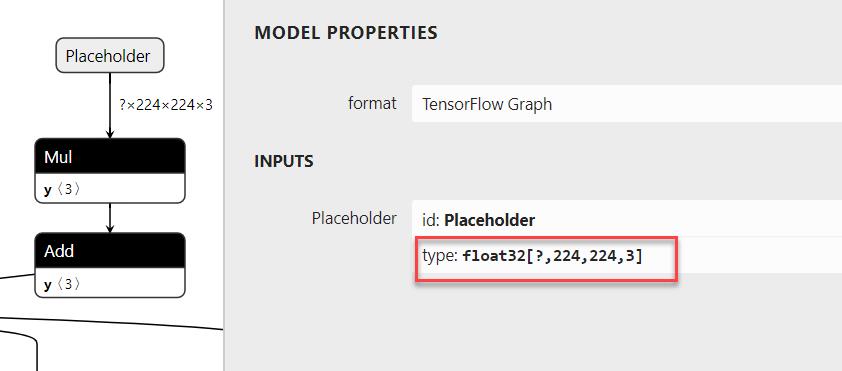
在TrainModel方法裡,配置好pipeline,最後叫用Fit進行訓練,由於ML.NET 在訓練Model時,須給與訓練集資料,以取得資料的Schema,但本例是將Azure Custom Vision導出的模型,再轉化為ML.NET 模型,並不需要重新訓練Model,故直接建立一個假的Image資料即可(Schema要符合)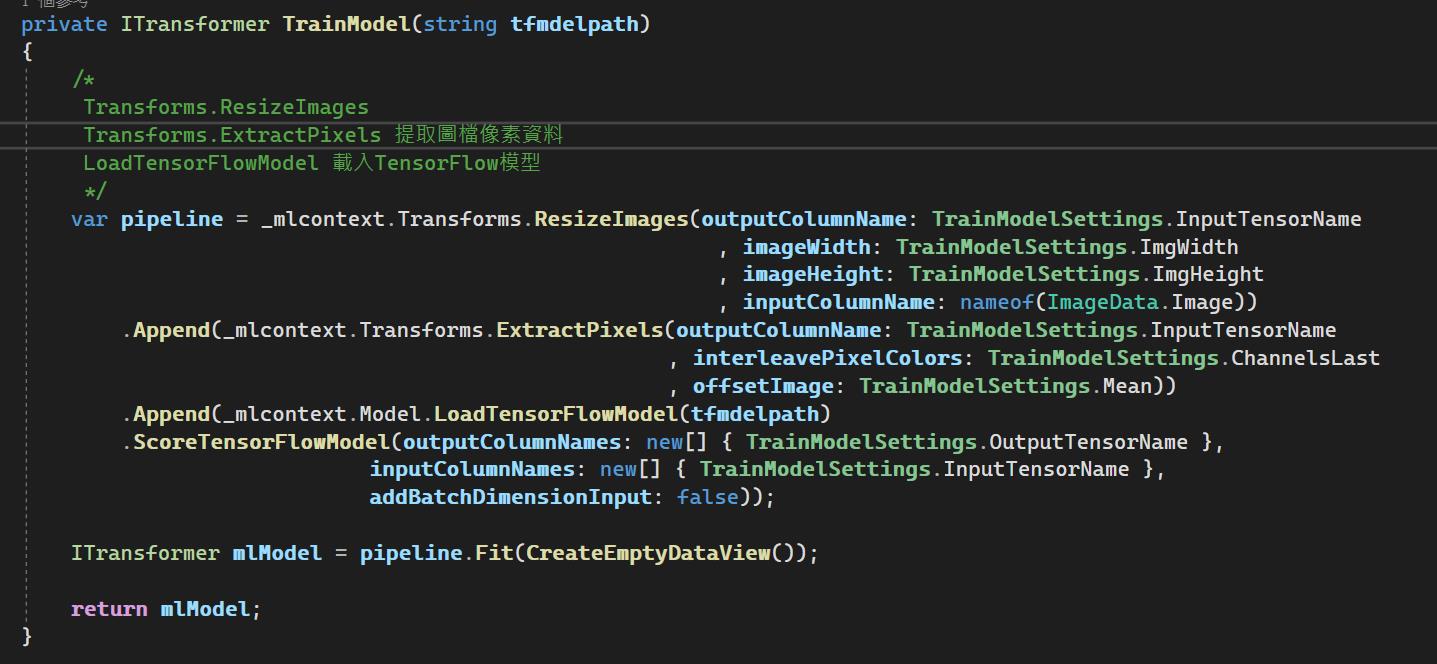
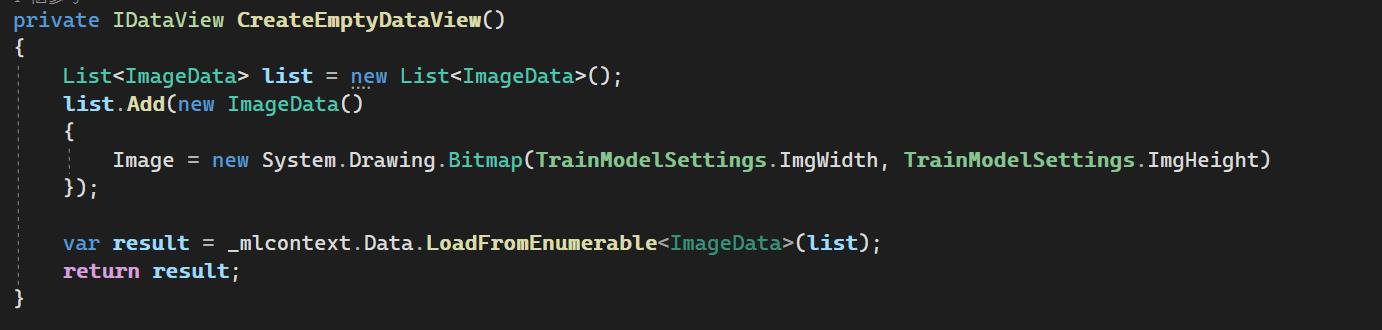
最後訓練完成,就可以產出ML.NET格式的模型出來,呼叫Save方法儲存模型,它會是一個zip檔,不需要再解壓縮直接就拿來用。


到這裡就完成了我們的第3步,最後一步就是同樣使用ML.NET來叫用這個模型,進行預測,完成本地端的應用。
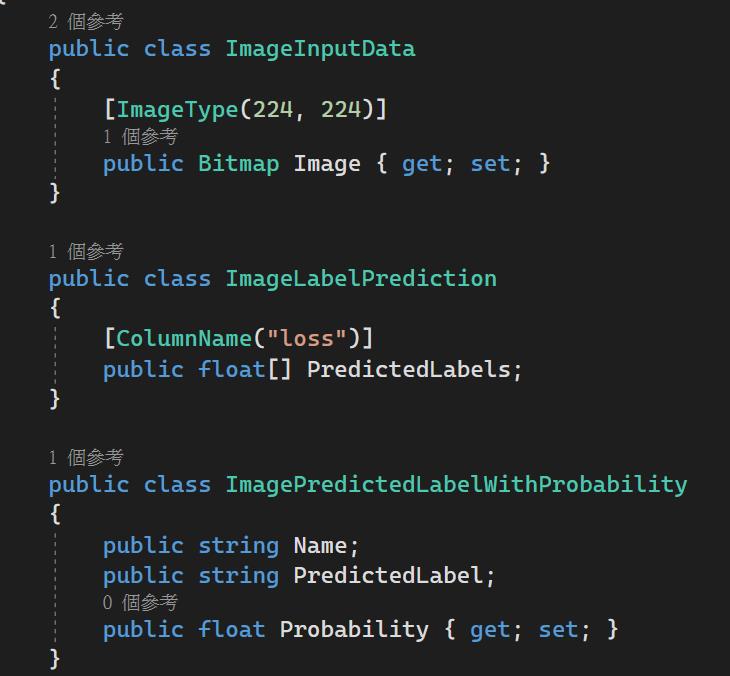
在上一個步驟我們有建立二個主控台應用程式,其中一個拿來轉換模型,另一個拿來示範本地端應用,我們先在專案內建立二個目錄,分別是ImgDatas以及MLModel,其中ImgDatas目錄內放置幾張照片待會用來測試的,而MLModel目錄把上一步我們轉完後的模型(zip檔)放進來以及從Custom Vision轉出的label.txt檔也一併放入,同時在MLModel目錄內,新增3個類別(在這裡我把它都放在ImageInputData.cs內,把它拆開也可以的),分別定義了資料輸入的格式、輸出格式以及預測結果
接著同樣的我們定義一個ConvertToBitmap方法,作用是用來把圖檔轉為Model需要的輸入格式Bitmap。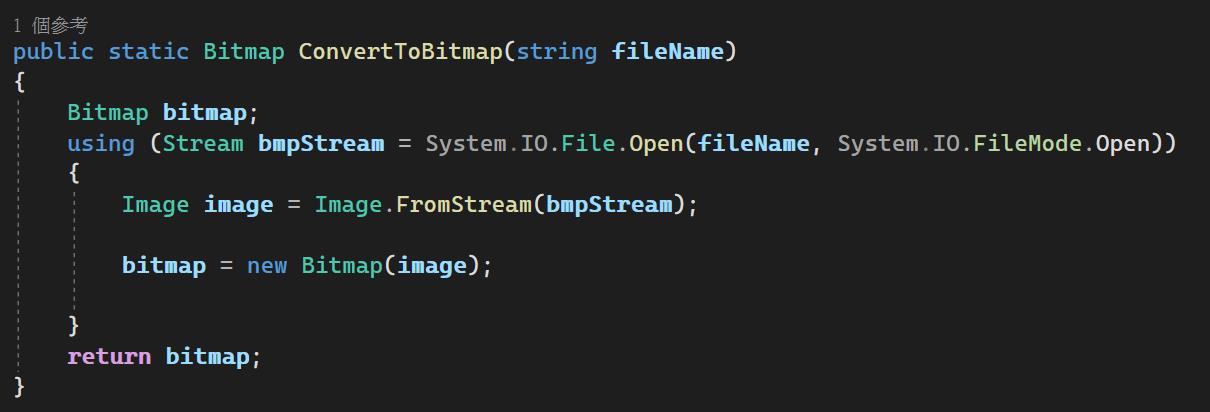
在Main方法裡,我們前面有提到過,整個ML.NET都是圍繞著MLContext物件,我們一樣必須先建立MLContext物件,同時定義了幾個變數,分別是模型位置、圖片檔案位置以及標注類別
緊接是叫用Load方法,以進行模型的載入,然後建立預測引擎,此時必須把模型傳入。
而最後就是把我們的圖片丟進去,讓模型進行預測,所有的執行過程都是在應用程式內部進行,完全不需要依賴外部API的呼叫,因此得以實現本地端離線預測應用的情境,在邏輯裡面我們這裡放置了一個maxresult >= 0.9的判斷,用來判斷最大預測分數是否有超過0.9,若有才認定,若是最大預測分數未達標則認定該圖片無法預測成功,這完全是一個客製化的邏輯,並不是絕對要的,完全取決個人需求,你也可以直接以最大預測分數值認定預測結果。
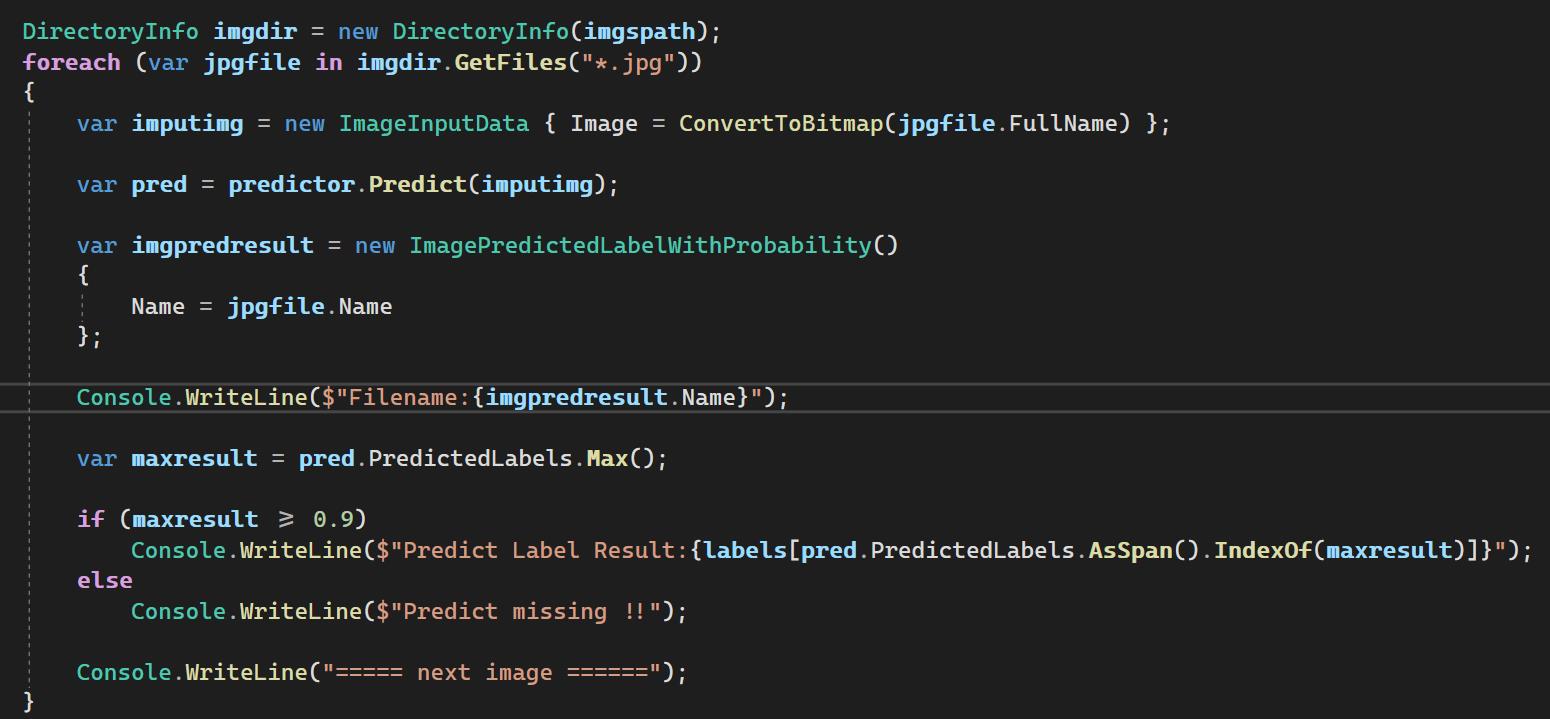
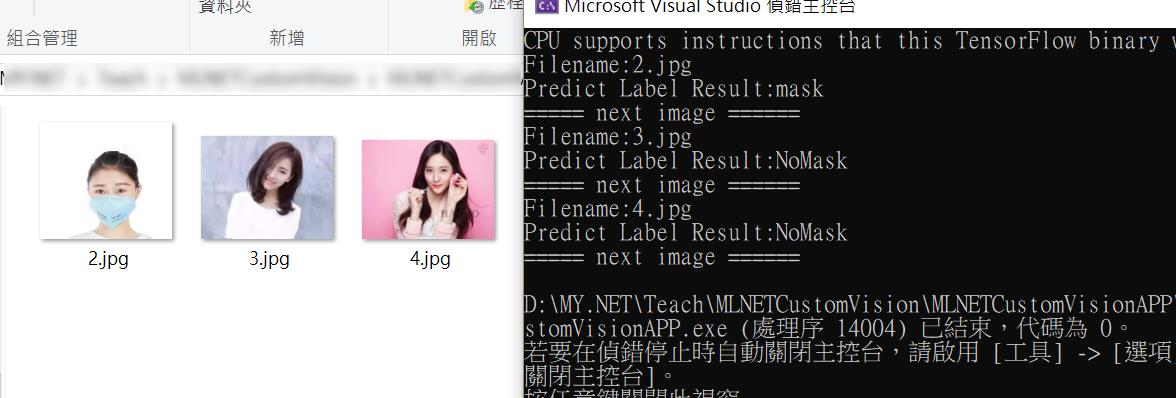
最後就看實際輸出的結果吧。
By No.18