筆記下 Google Machine Learning 的那些事
筆記一下
AutoML 訓練用於分類/迴歸的每節點時數價格 $21.252 美元
流程
https://console.cloud.google.com/
啟用 API

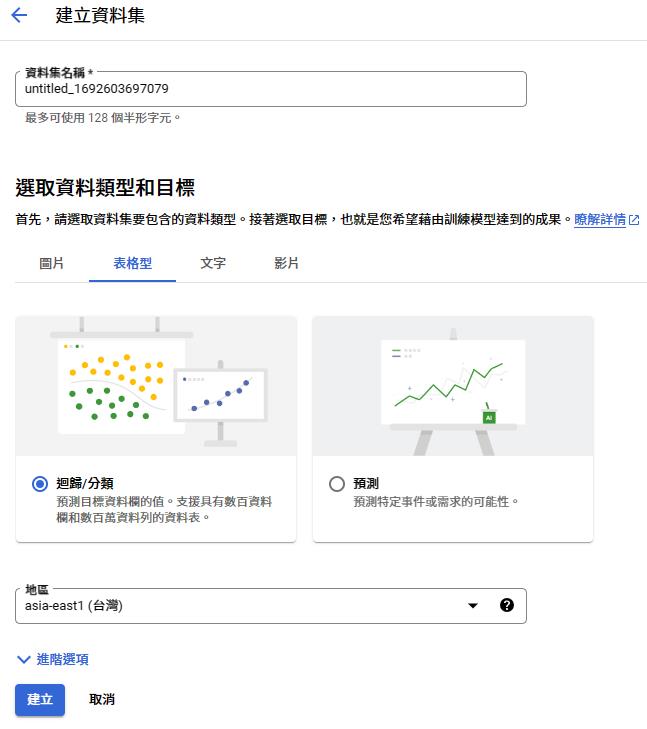
新建資料集
這邊會定義資料集名稱與種類,並可以直接從這邊選本機檔案上傳到 Storage
※ 反過來可以先把資料上傳到 Storage 再來這裡直接設定資料集來源 from Storage

DataSet
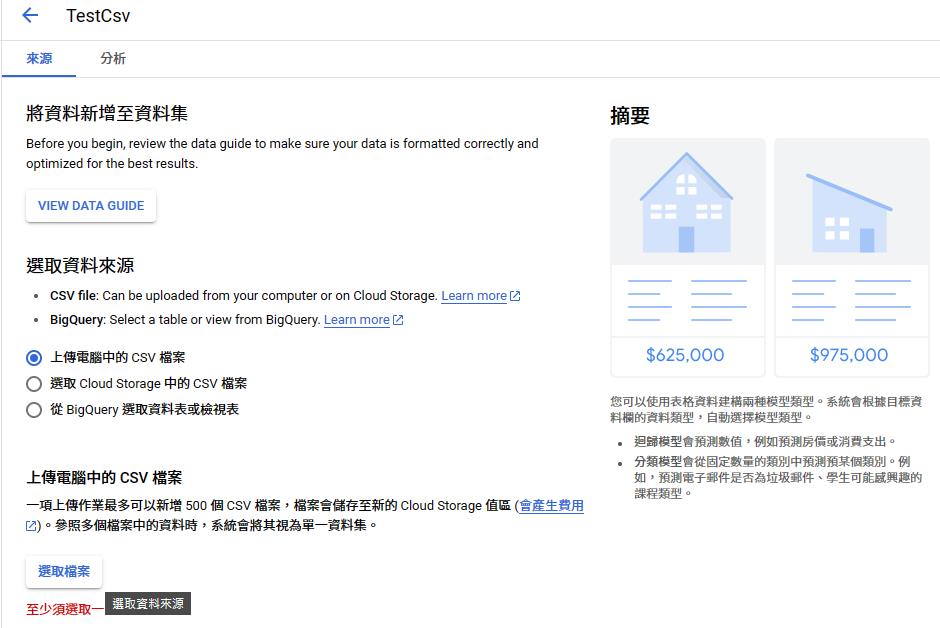
上傳資料
https://github.com/dsindy/kaggle-titanic/blob/master/data/train.csv
※ 這份資料只有八百多筆,Azure可以用,GCP說要一千筆以上資料才能跑
Storage
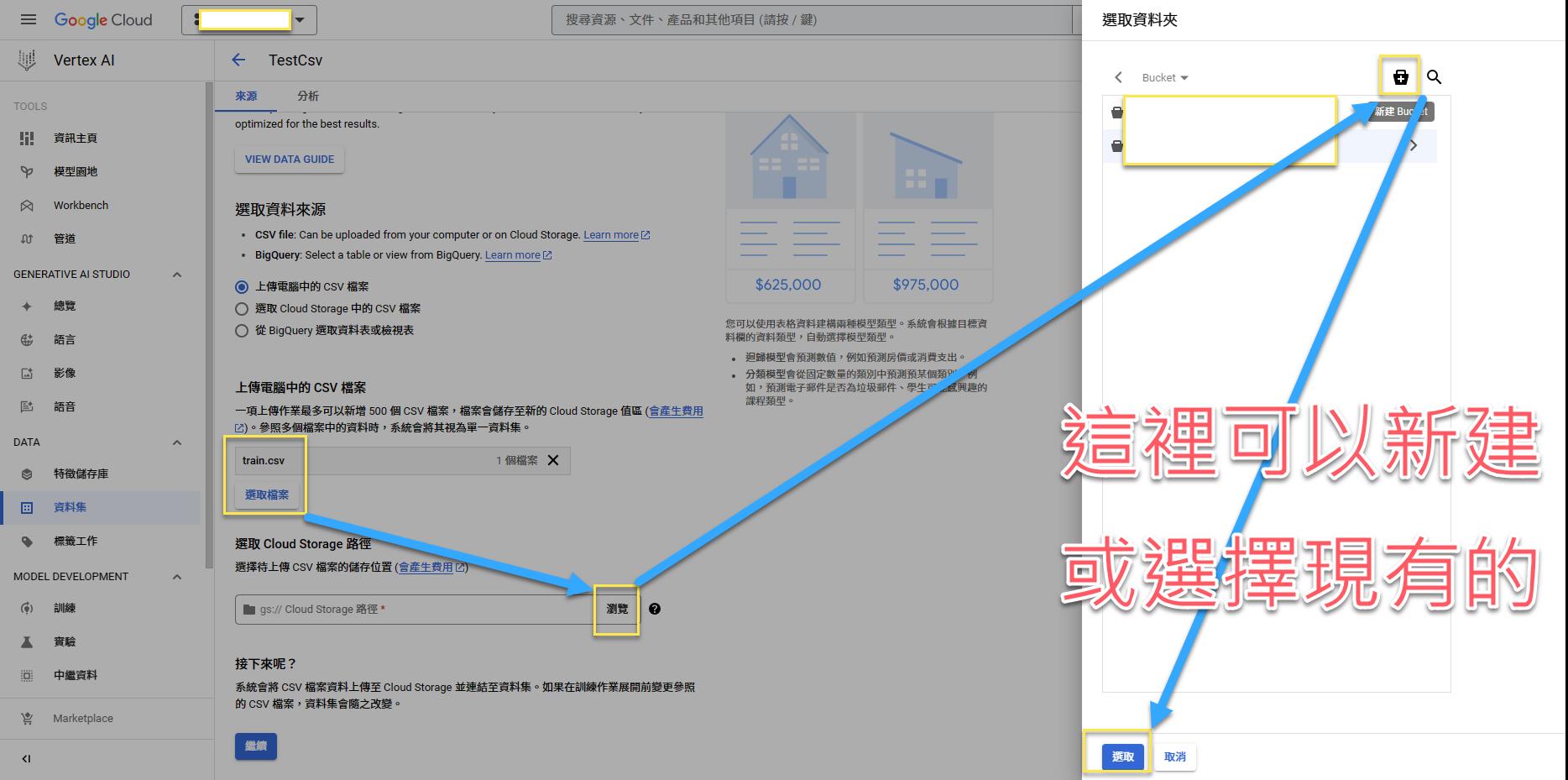
新建 Storage

主畫面會有最近的資料

在資料集內可以訓練新模型

AutoML
目標這邊要改回歸

選擇欄位
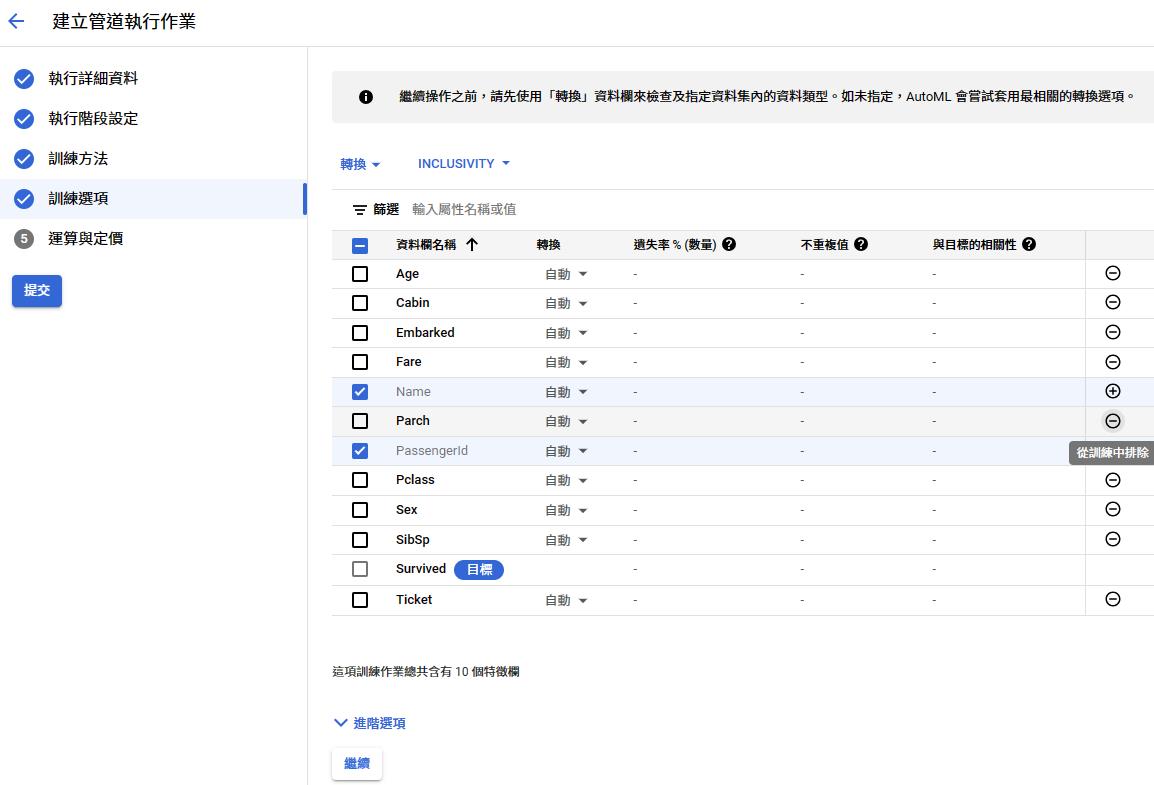
提交
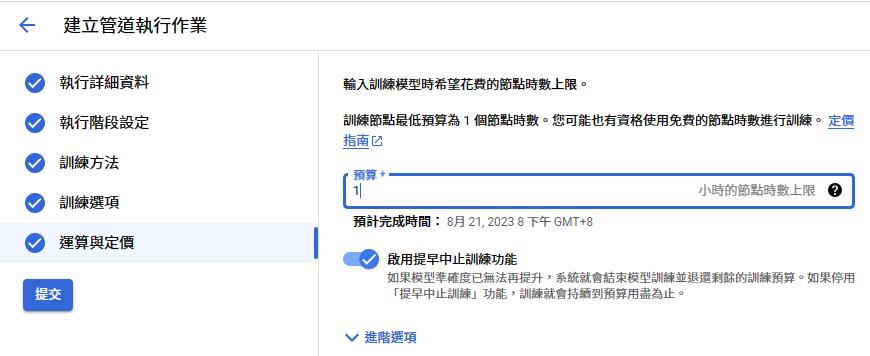
結果
成功畫面
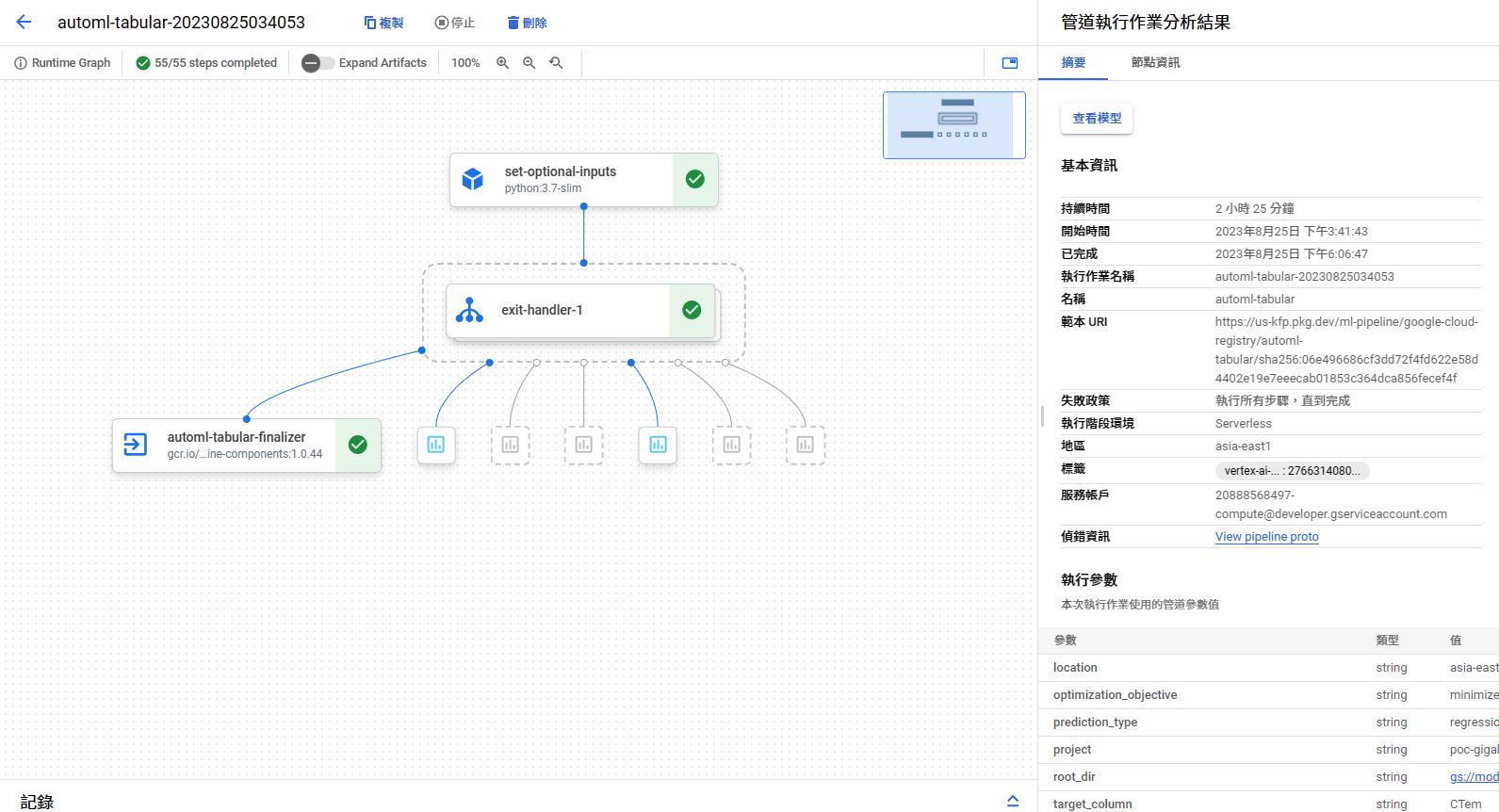
pipelines
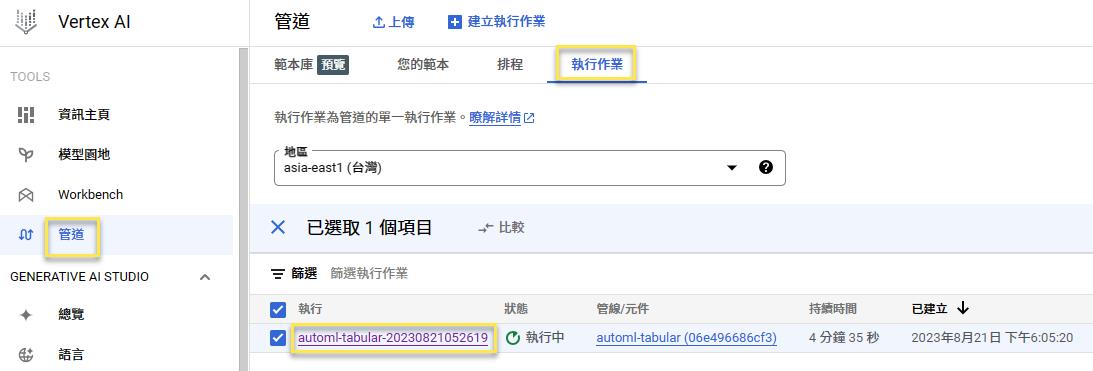
跑完之後可以到模型園地
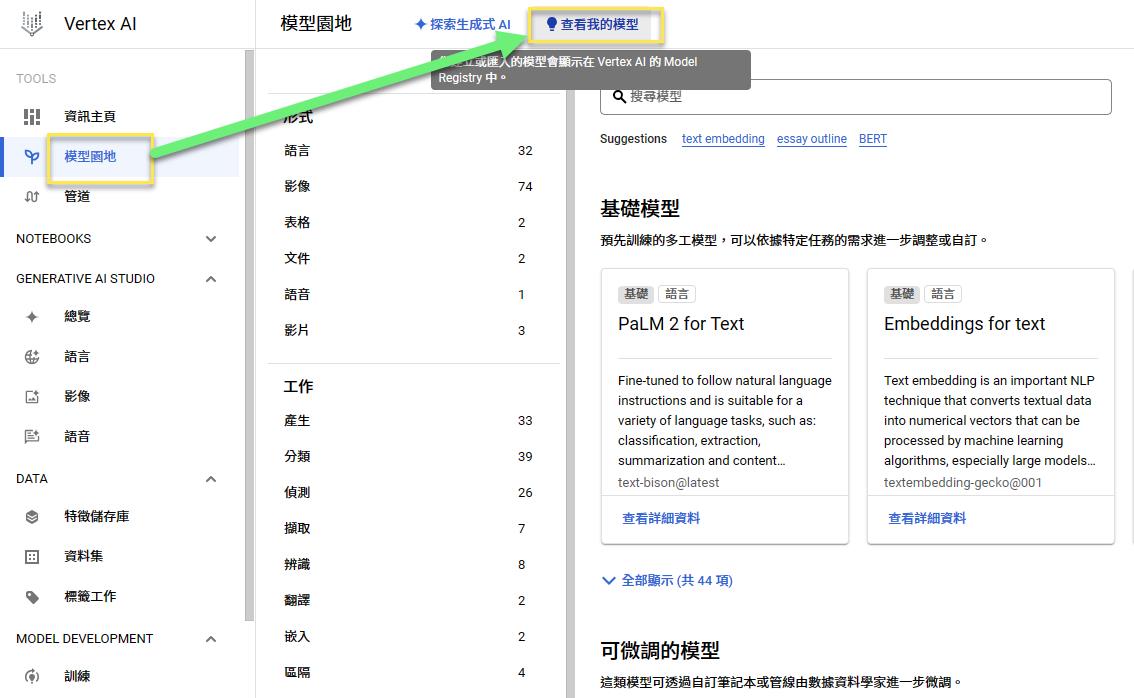
我的模型中找到剛剛(兩個多小時)訓練好的模型
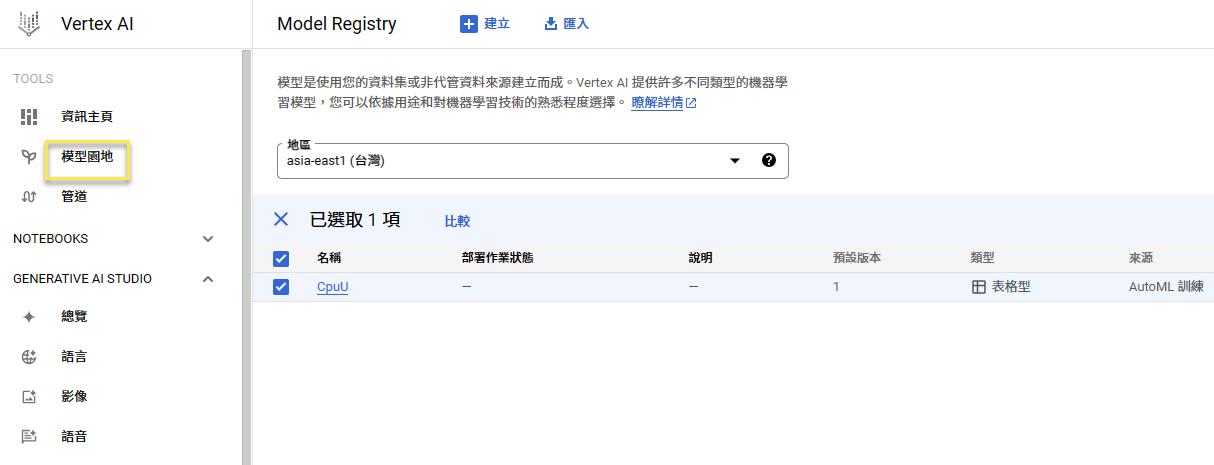
點進去可以看參數

Deploy
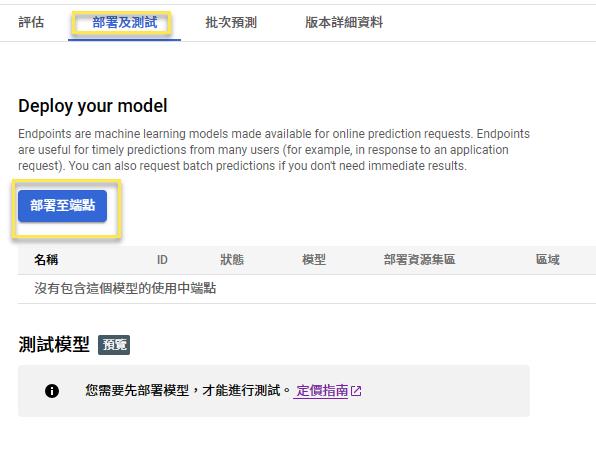
Endpoint
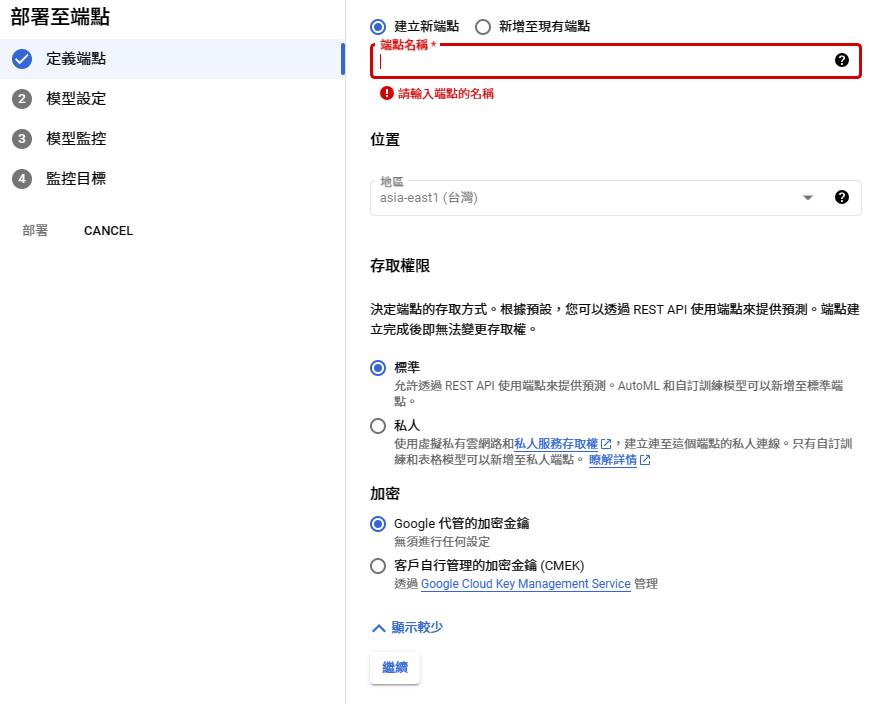
Spec

模型監控

監控目標
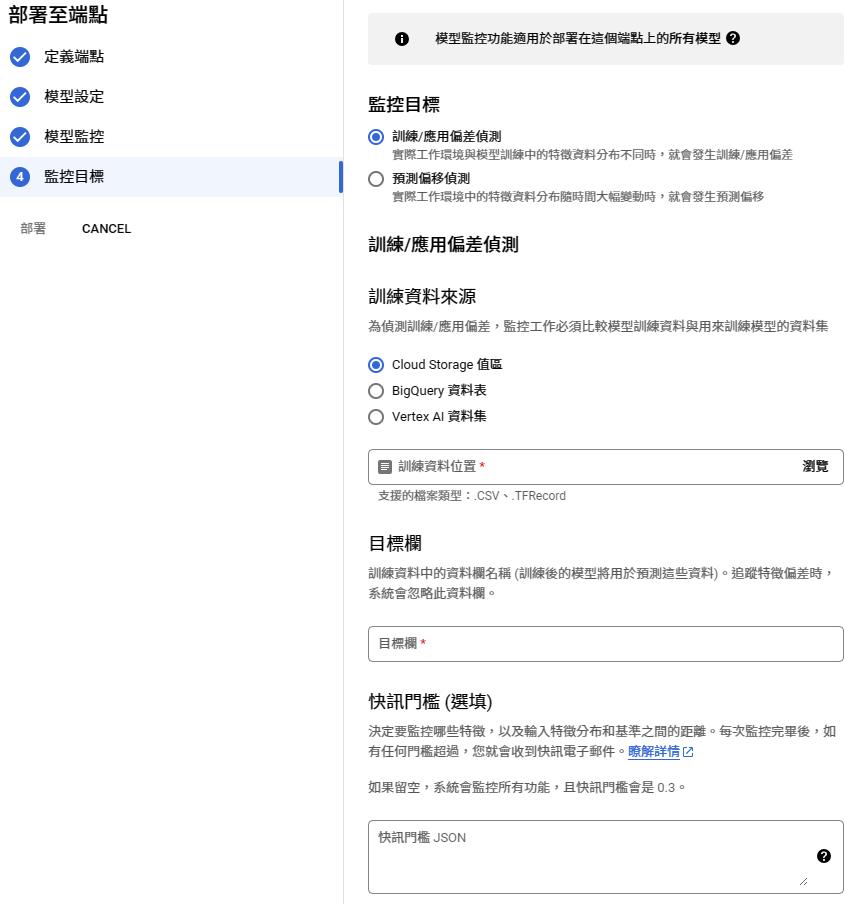
也可以關閉監控直接部署
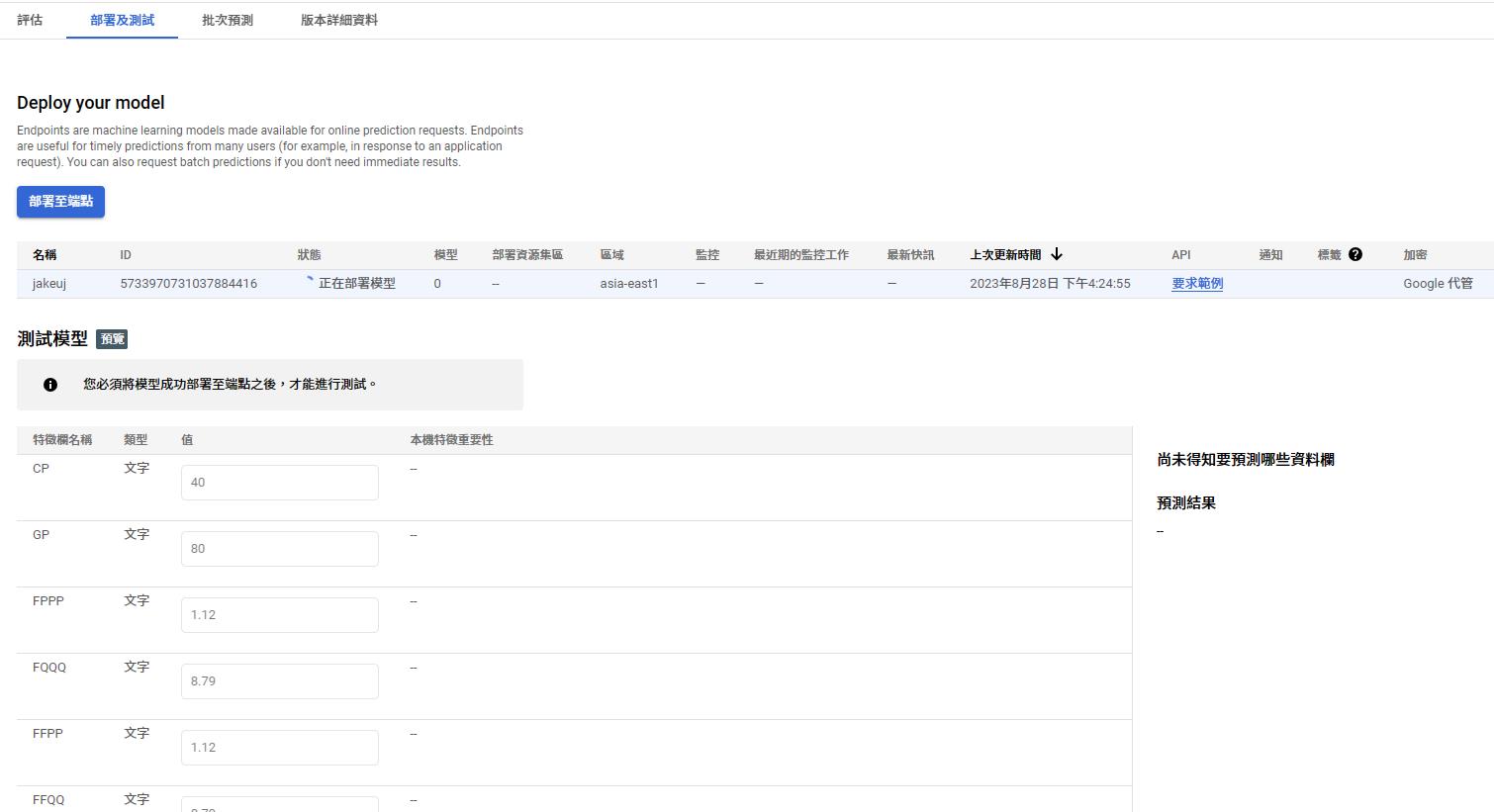
Rest
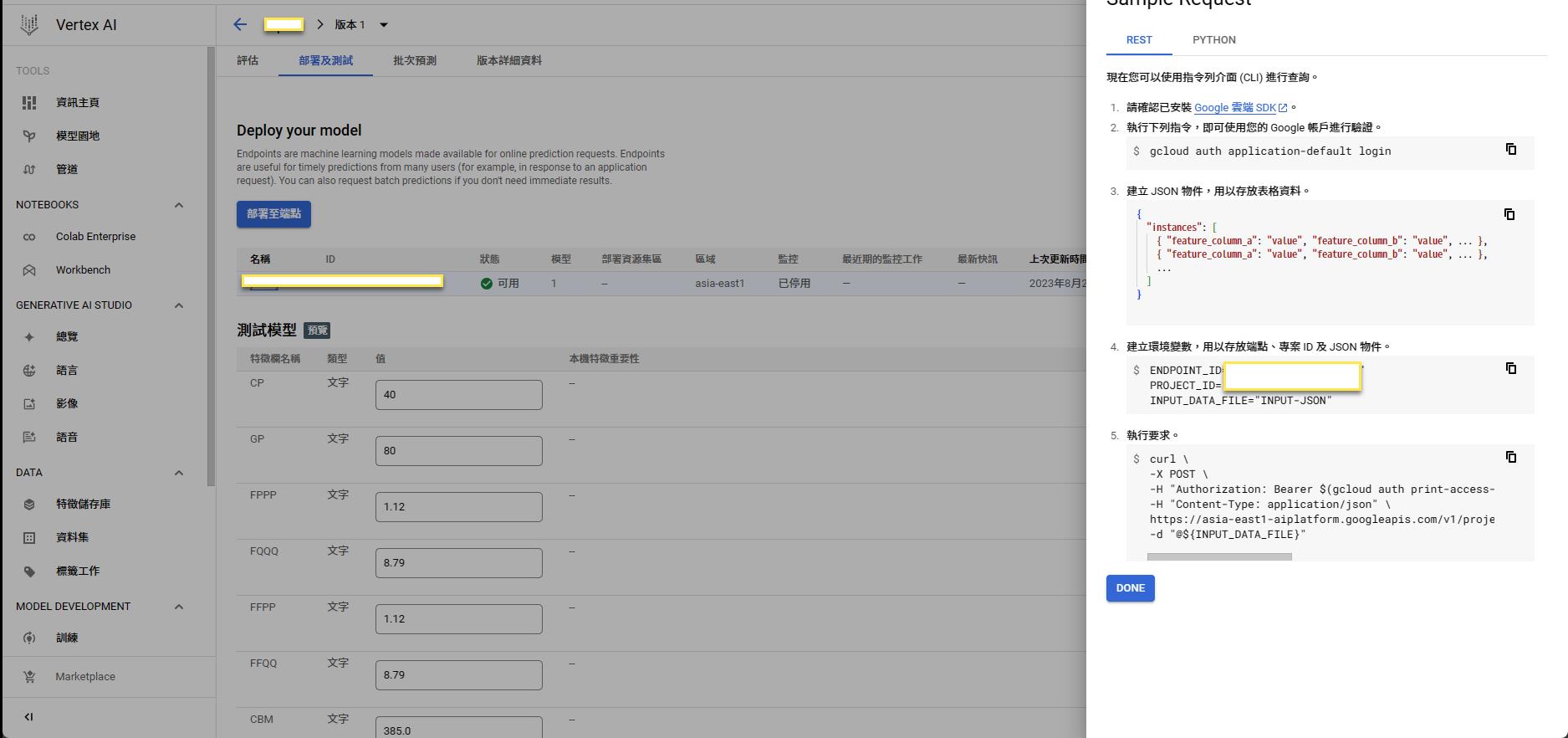
Batch
最後可以在線上預測中找到端點
注意
線上預測端點一但部署就會開始算錢(因為要起一台機器隨時提供Rest API)
練習完千萬記得刪除端點(要先到端點裡面取消模型註冊方可刪除)
Error
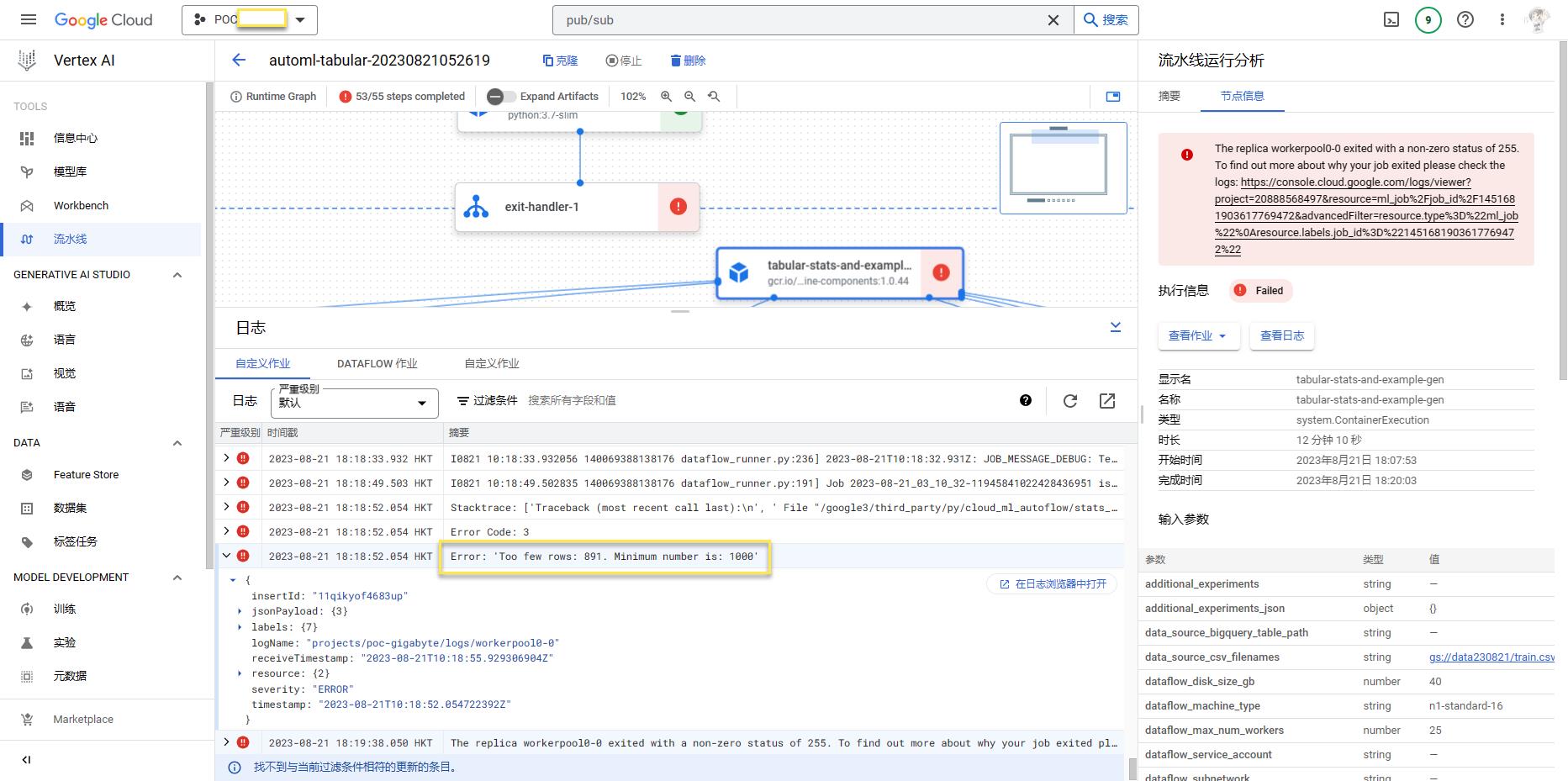
資料少於1000筆會失敗
Invalid CSV file: 'utf-8' codec can't decode byte 0xad in position 129: invalid start byte
上傳資料遇到錯誤,看了一下手上是 Big5,我改成 UTF8 後可以正常分析統計資料,但訓練會失敗,最後改成UTF8BOM。
- 資料筆數最少要1000筆以上。
- 權重欄位不重複值不能超過10000筆以上。
- 欄位名稱無法解析(每個欄位開頭要用英文字母,『-』、『?』、『:』和中文好像有問題)。
Required column(s) not included in the provided schema: ['A', 'B', 'C']
我最終重建 DataSet 來重跑 AutoML 之後就成功了
猜測一開始建立 DataSet 時的欄位就已經固定了,後續改 csv 欄位會導致錯誤?
參照
介紹Vertex(1) | ML#Day18 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
