前陣子在 FB 寫了「為什麼都要拿 GUID 來使用」,造成一些朋友的回應,因此我先利用一點時間來整理一下自己的幾個案例,當然這些案例並不是要去說用 GUID 的欄位型態就完全不好,只是想說明當如果要採用 GUID 的時候,可能相關的問題要去注意一下,這樣可以減少一些不必要的效能問題。
在談這個 GUID 問題之前,我們可能要先說三件事情,這樣或許會比較容易說明後面的狀況
1. Cluster Index vs. Noncluster Index : 對使用 SQL Server 的朋友來說,應該對這個題目不陌生。在 SQL Server 的架構中,一個資料表最多只能有一個 Cluster Index ( 叢集索引 ),因為資料會按照 Cluster Index 的 Key 值,將資料按照這樣的順序去排列,而其他的索引都只能是 Noncluster Index。而從 SQL Server 2005 開始,當你建立 Primary Key 的時候,如果資料表沒有其他叢集索引的時候,預設就會建立成為叢集索引。如果資料表都沒有任何叢集索引的時候,則會使用 Heap 的方式,將所有的資料頁涵蓋在內。
做一個簡單的範例
CREATE DATABASE DEMO1
GO
USE DEMO1
GO
CREATE TABLE INDEXDEMO( F1 int , F2 nchar(100) )
GO
SET NOCOUNT ON
DECLARE @Lower INT;
DECLARE @Upper INT;
DECLARE @Total INT;
DECLARE @PTR INT;
DECLARE @Random INT;
SET @Lower = 1
SET @Upper = 999999 ;
SET @Total = 1000;
SET @PTR = 1 ;
WHILE @PTR < @Total
BEGIN
SET @Random = ROUND(((@Upper - @Lower -1) * RAND() + @Lower), 0);
INSERT INTO INDEXDEMO( F1, F2 ) VALUES ( @Random , RIGHT( '0000000000'+CAST(@PTR AS VARCHAR ),10 ));
SET @PTR += 1 ;
END
SET NOCOUNT OFF
GO
所以當我們建立 PRIMARY KEY 在資料表上之後,因為預設是重集索引,因此資料就會按照索引的順序排列,甚至後續做其他資料維護,也會按照索引的順序去排列。
ALTER TABLE INDEXDEMO ALTER COLUMN F1 INT NOT NULL
GO
ALTER TABLE INDEXDEMO ADD PRIMARY KEY( F1 )
GO
2. Index Fragment : 索引破碎是我們在 OLTP 環境中時常遇到的一種狀況,如果要細看,會分成 External 和 Internal,不論是哪一種的狀況,主要都會影響到當資料讀取的時候,要耗費比較多的磁碟 I/O,一般來說我們可以透過 sys.dm_db_index_physical_stats 這個 DMV 來查看索引破碎的狀況,可以依照破碎的狀況,我們可以使用 ALTER INDEX 的指令,來搭配 REBUILD 或者是 REORGANIZE 的參數。下面我做一個範例來測試,在這裡我們要去找 ABC 這個資料庫下面的 EmpFamilyDetail 這個資料表的破碎狀況,如果想更清楚知道每個參數的用題,可以參考 MSDN 上的說明。
select
OBJECT_NAME(p.object_id) TableName,
i.name IndexName,
index_type_desc,
avg_fragmentation_in_percent,fragment_count,page_count
from sys.dm_db_index_physical_stats(DB_ID('ZCK'),OBJECT_ID('EmpFamilyDetail'),NULL,NULL,NULL) p
join sys.indexes i on p.object_id=i.object_id and p.index_id=i.index_id

當我們知道那些資料表和索引破碎,那我們就可以用類似幾下幾種用法來處理,一般來說我們會按照所有調整的幅度來使用前兩種方式;而第三種可按照所指定核心數平行必且保持在線上運作 ( ONLINE 是只能用在 Enterprise 版本 );但如果你的資料表沒有叢集索引,那麼當資料表破碎的時候,從 SQL Server 2008 開始可以比較簡單的採用 ALTER TABLE REBUILD 的方式來處理了。
-- 指定特定資料表的特定索引做重建
ALTER INDEX PK__EmpFamil__58B7DD7118027DF1 ON EmpFamilyDetail REBUILD
-- 指定特定資料表的索引做重建
ALTER INDEX ALL ON EmpFamilyDetail REBUILD
-- 指定特定資料表的索引使用兩個核心,並保持在線上做重建索引
ALTER INDEX ALL ON EmpFamilyDetail REBUILD WITH ( MAXDOP=2, ONLINE = ON )
-- 當資料表採用 HEAP 時可透過 REBUILD 來重建資料表
ALTER TABLE EmpFamilyDetail REBUILD
當我們透過上述指令重建索引之後,再重新查看索引的實體統計資訊,就會發現所占用的資料頁面因為重建之後有所改善了。
如果覺得下指令太麻煩了,也可以透過 SSMS 的報表和索引維護,來完成這些工作。
3. 統計資訊 : 一般當我們建立好資料庫之後,如果沒有做甚麼特別處理,預設「AUTO_CREATE_STATISTICS 選項」和「AUTO_UPDATE_STATISTICS 選項」這兩個設定都是開啟的,雖然看起來這裡設定之後,統計資料我們就不用去煩惱了,SQL Server 會自動維護,但在 MSDN 上有一篇文章「Statistics Used by the Query Optimizer in Microsoft SQL Server 2008」上關於「Maintaining Statistics in SQL Server 2008」中有詳細說明 SQL Server 會自動更新的時間點,當資料量大於 500 筆的時候,資料庫會當資料表的異動大於「500 + 20% * 總筆數」的時候,這個時候才會重新更新索引。因此假設您的資料有一萬筆的時候,那麼這個值就會是 2,500 ( 500 + 20% * 10,000 ),所以也就是表示當你資料越來越多的話,當你資料的異動量不夠多時,會有一段時間統計資料是有落差的。
這裡我用原本的 INDEXDEMO 的資料表,重新清除資料之後塞入 10000 筆的紀錄,接下來就可以透過 sp_updatestats 這個預存程序更新統資料,接著透過 DBCC SHOW_STATISTICS 來查看統計資訊
EXEC sp_updatestats
GO
DBCC SHOW_STATISTICS (N'dbo.INDEXDEMO',PK__INDEXDEM__321492703B95798E)
GO
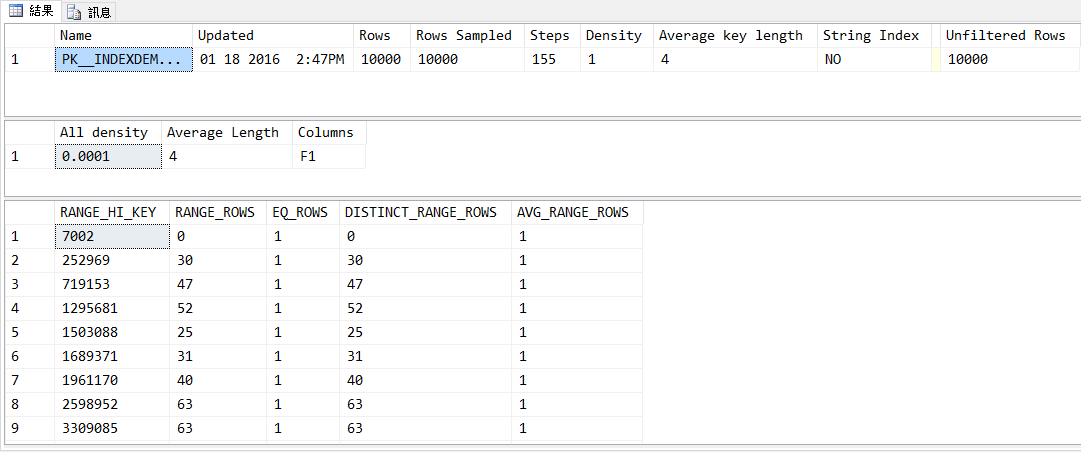
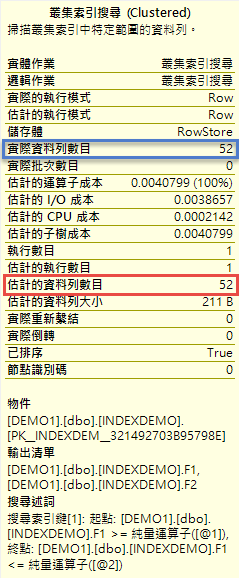
因為有這些統計資料,當我們下指令去查 F1 介於 719154 和 1295680 之間的時候
SELECT * FROM INDEXDEMO WHERE F1 BETWEEN 719154 AND 1295680
因為統計資料目前是正確的,因此當我們查看執行計畫的時候,可以看到預估的資料筆數和實際的資料筆數是相同的。
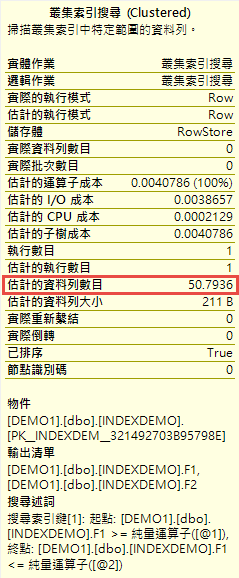
這個時候要是我們下一筆刪除的指令,把 F1 <= 1961170 的資料刪除 232 筆 ( 1+30+1+47+1+52+1+25+1+31+1+40+1 ) 之後,這個時候在重新下一次之前的查詢指令,當我們再次查看執行計畫的時候,會發現估計的資料數目和實際已經有很大的落差了。
PS. 在 2015/11 月的 SQL Pass,Rico 有分享一個利用開啟 Trace Flag 2371 的方式 ( 可參考網址 ),可以讓資料筆數增加之後,縮小資料異動比例,當有大量異動資料的狀況下,也是一個不錯的方式。

而在這個部分要稍微注意一個地方,也就是統計資料更新是發生查有需要查詢的狀況下,假設你下指令更新很多筆紀錄,就算達到需要更新的數量時,SQL Server 並不會馬上更新,而是當你有需要使用該統計資料的時候,那個時候才會去做更新,這點要稍微注意一下。
而在接下來要介紹的這個案例,剛好有點特別,他使用 GUID 當成 PK,另外資料表的資料筆數也非常的多,其中有個 View 會搭配一些比較複雜的查詢條件,在測試環境下第一次大約執行 3 秒鐘,找出一筆符合條件的資料,後續再執行的話,因此資料表都已經載入記憶體,因此執行的話都可以在一秒內解決。
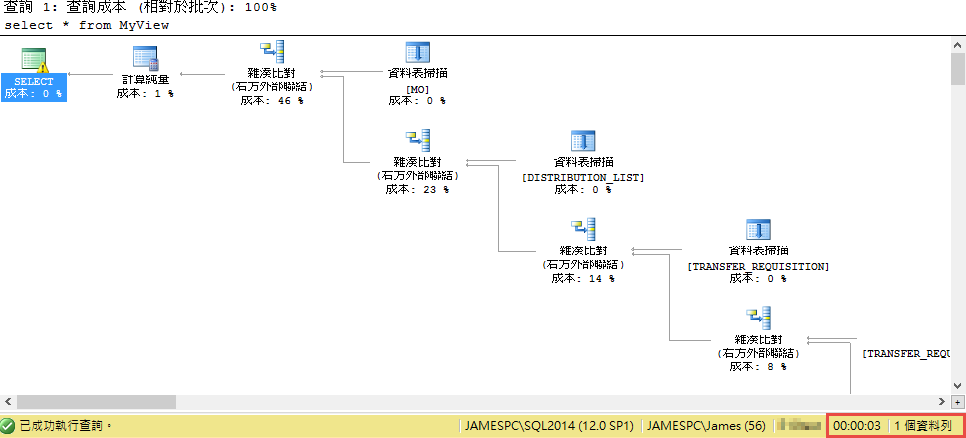
此時我們會用以下的指令建立一個資料表,會用來存放透過 View 所取出來的資料
CREATE TABLE MySample
(
REQUISITION_ID uniqueIdentifier NOT NULL PRIMARY KEY,
ITEM_CODE nvarchar(40),
UNIT_NAME nvarchar(40),
EMPLOYEE_NAME nvarchar(40),
PLANT_NAME nvarchar(40),
WAREHOUSE_NAME nvarchar(40),
REFERENCE_ID uniqueIdentifier
)
接著我們將 SELECT 的資料放到這個 Table 內
INSERT INTO MySample
SELECT NEWID(),ITEM_CODE,UNIT_NAME,EMPLOYEE_NAME,PLANT_NAME,WAREHOUSE_NAME,REFERENCE_ID
FROM MyView ;
但這樣一個簡單的動作,卻花費掉 40 秒以上的時間,明明我們的資料只有一筆,單獨執行指令也只需要 0~3 秒鐘的時間,就算磁碟在慢應該也不會這麼悽慘吧。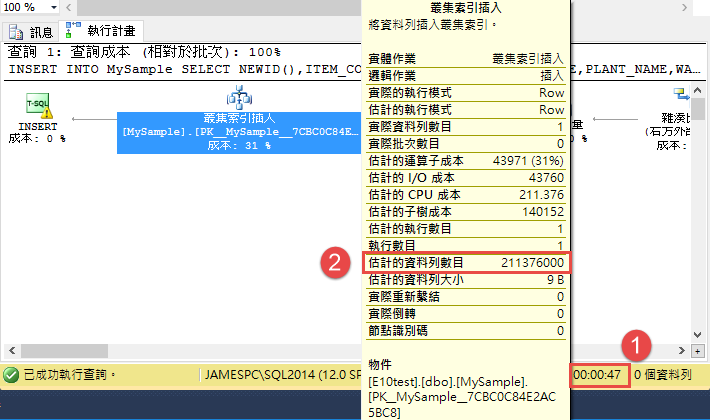
但在這個例子,如果仔細看一下執行計畫,主要是因為估計的資料列數目這裡落差太大,造成 SQL Server 在 SELECT 的時候,加上透過 NEWID() 這個函數產生一個新的 GUID,因此在這裡 SQL Server 會去誤判去產生一堆的 GUID 值,導致雖然實際只有一筆資料的產生,但因為種種的錯誤,導致到這裡會發生這樣的異常。而這個估算錯誤,主要是因為在 View 裡面的很多個 Table 關聯一起,這些資料表內都有非常多資料,加上這些索引和鍵值欄位又是 GUID的型態,導致估算的時候偏差很多。
既然知道問題發生的原因,那接下來就好改了,一種是建立資料表的時候,我們利用 DEFAULT 的方式,將欄位的預設值使用 NEWSEQUENCEID() 函數,這樣不需要 SELECT 的時候去利用 NEWID() 來取值就可以了。但有朋友在問,那為什麼不把原本 「SELCT NEWID(),..... 」 改成 「SELECT NEWSEQUENCEID(),..... 」呢 ? 主要是因為 NEWSEQUENCEID() 這個不能放在 SELECT 這裡來使用,因此我們把這個放在欄位的預設值內,這樣就可以避開這個統計資料和 GUID 的問題了。當然另外也可以直接把這個欄位改成 bigint 的欄位,然後搭配 IDENTITY 去給值,也是一種解決的方式囉。或者是如同前面的統計資料說明,我們可以利用排程的方式,定時去手動更新統計資訊和索引,也可以避開這樣的問題。