前一篇我們介紹一個特別的案例,主要是因為 GUID 和錯誤的執行計畫所造成的問題,這次我們換比較簡單一點的狀況,來說明使用 GUID 所要注意的事項
在以往學開發程式的時候,以及自己所開發一些產品上的經驗,在設計資料表的時候都常都會從 ER Model 的分析中,找到一組合適的欄位來當主鍵,也都覺得這個是很正常的事情。但曾幾何時,開始接觸一些使用 ORM ( Object-relational mapping ) 的開發技術時,感覺很多書籍和開發人員,都會採用 GUID 的型態來當成鍵值,也漸漸成為主流的一種方式。
就技術而言,GUID 是一個 128 位元長的二進位整數,基本上他會發生重複的機率非常的低,可以說趨近於 0,因此當如果採用 GUID 來當成鍵值使用的時候,就可以避免會有同時間有相同鍵值的資料,相對來說對開發資料庫應用程式來說,這一點非常的方便。因為傳統的鍵值都會搭配一些取號原則,在資料還沒有正式存入之前,很有可能會有多個處理對同一個資料表會取得相同的一個鍵值,而存入資料庫的時候主鍵只能唯一,造成只有一個可以正常存入,其他的就要靠 TRY CACHE 去做後續的處理,有些人設計上會利用自動跑幾次存入,來避開這樣的問題;也有人會考慮利用 Identity 的方式,利用流水號產生來避開存入時取號的問題,但變成當你要處理 Master-Detail 型態的資料表設計時,則要多做一些處理才能讓 Detail 取得 Master 的鍵值。
那這樣說來,乍聽下來採用 GUID 應該是個很不錯的選擇啊,為什麼要反對呢 ? 我個人覺得 GUID 在很多處理上是很方便的,但不代表整個資料庫設計的時候,所有主鍵都一定要採用,因為她還是會有一些地方要考慮,下面我就幾個範例來說明使用 GUID 該注意的地方。
首先我先用以下的語法建立一個資料庫 DEMO1,並且在這個資料庫裏面建立四個範例用資料表,分別取名為 T1 , T2 , T3 , T4,這四個資料表的主鍵欄位 F1 分別設定為 Int、Bigint、Uniqueidentifier 和 Char 型態 ( 這裡會拿 Char 來比較,是看到有部分人會從程式來產生 GUID,因此就直接把 GUID 當成字串來處理 );另外針對另外一個欄位 F2 建立索引。在這四個資料表內都放入一百萬筆資料。( 如果有興趣測試是可以放比較多的資料,但我的電腦速度太慢了,不想浪費太多時間等待,基本上資料筆數越多狀況越不好 )
use [master]
GO
IF DB_ID('DEMO1') IS NOT NULL DROP DATABASE DEMO1 ;
GO
CREATE DATABASE DEMO1
GO
ALTER DATABASE [DEMO1] SET DELAYED_DURABILITY = FORCED WITH NO_WAIT
GO
USE DEMO1
GO
CREATE TABLE T1( F1 int , F2 nchar(10), F3 nchar(100) )
GO
CREATE TABLE T2( F1 bigint , F2 nchar(10), F3 nchar(100) )
GO
CREATE TABLE T3( F1 uniqueidentifier, F2 nchar(10), F3 nchar(100) )
GO
CREATE TABLE T4( F1 char(36), F2 nchar(10), F3 nchar(100) )
GO
SET NOCOUNT ON
DECLARE @I INT = 0;
DECLARE @J INT = 0;
DECLARE @Value INT;
WHILE ( @I < 500 )
BEGIN
SET @J = 0 ;
BEGIN TRAN
WHILE @J < 2000
BEGIN
SET @Value = @I * 2000 + @J
INSERT INTO T1( F1, F2, F3 ) VALUES ( @Value , RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
INSERT INTO T2( F1, F2, F3 ) VALUES ( @Value , RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
INSERT INTO T3( F1, F2, F3 ) VALUES ( NEWID(), RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
INSERT INTO T4( F1, F2, F3 ) VALUES ( NEWID(), RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
SET @J += 1 ;
END
COMMIT
SET @I += 1 ;
END
SET NOCOUNT OFF
GO
當前面的 Script 執行完畢後,我們可以使用 sp_spaceused 來查看資料表的狀況,從下面的結果看起來,四個資料表的資料筆數都一樣,但 Size 會有點不同
exec sp_spaceused 'T1'
exec sp_spaceused 'T2'
exec sp_spaceused 'T3'
exec sp_spaceused 'T4'
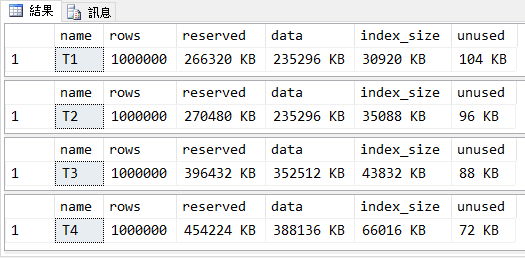
從這樣的資料看起來,似乎也只多占用一點空間,因為 Uniqueidentifier 是 16 Bytes,所以比 Int 型態 4 Bytes 多了 12 Bytes,比較大一點應該沒有甚麼問題才對,那更別說用 char 型態來存放會更浪費磁碟的空間了。可是我們要是稍微再精算一點,一筆資料多了 12 Bytes,那一百萬筆資料應該也才多 12MB 才對啊,看從 T1 和 T3 的 data 大小,看起來相差有 117MB,而同樣都是型態的 Index,T3 也比 T1 的索引多了 12MB,這個部分就合理多了。
接下來我們透過另外一個 DMV 來查看,這裡我們借用 sys.dm_db_index_physical_stats 來查看索引的狀況,這個是非常有用的一個 DMV ,可以讓我們很清楚了解索引實體結構的資訊
SELECT
OBJECT_NAME(p.object_id) TableName,
i.name IndexName, i.type_desc IndexType,
p.avg_fragmentation_in_percent, p.fragment_count, p.page_count, p.page_count*8/1024 'pagesize(MB)'
FROM sys.dm_db_index_physical_stats(DB_ID('DEMO1'),NULL,NULL,NULL,NULL) p
JOIN sys.indexes i ON p.object_id=i.object_id AND p.index_id=i.index_id
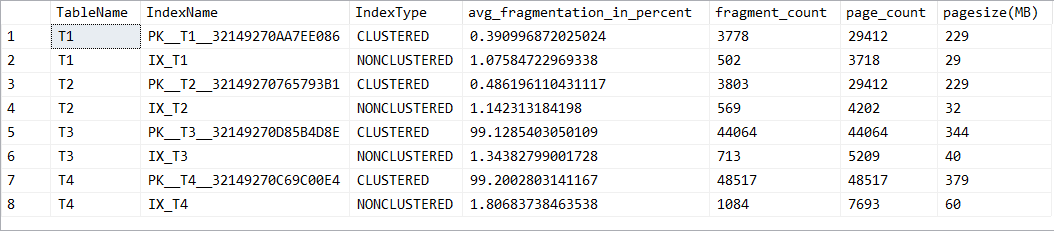
從結果中可以看出來,因為 T1 & T2 在產生的時候,我們是直接給流水號,因此資料在放入到資料表的時候,其實索引的破碎程度並不嚴重;但反觀 T3 & T4,因為鍵值欄位分別採用 Uniqueidentifier 和 char的資料型態,就會造成非常大量的索引破碎的狀況。此部分我們先透過 ALTER INDEX 的部分,看重建之後是否效果有所改善。
這裡我們採用以下的指令來進行索引重建
ALTER INDEX ALL ON T1 REBUILD;
ALTER INDEX ALL ON T2 REBUILD;
ALTER INDEX ALL ON T3 REBUILD;
ALTER INDEX ALL ON T4 REBUILD;
GO
經過一些時間等待處理完畢,接著透過之前所使用的 DMV 再重新查看一下索引的實體統計資料,看起來似乎狀況改善不少 ( 這裡要稍微注意一下,如果你的不是 SQL Server Enterprise 版本,沒有辦法 REBUILD Index 的時候設定 ONLINE 屬性的話,那麼重建所引的時候會整個資料表鎖定,造成要使用該資料表資訊的查詢會被鎖定,因此如果是正式線上的資料庫,可能要注意一下使用時機 )
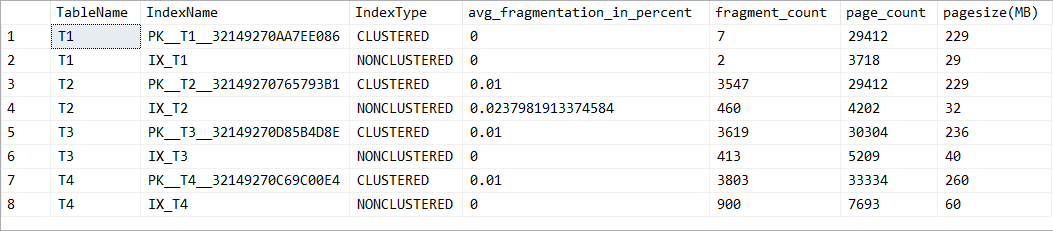
那麼接著我們再把二十萬筆資料刪除,再新增二十萬筆資料
DELETE TOP(10000) T1 WHERE F2 < '0000200000'
DELETE TOP(10000) T2 WHERE F2 < '0000200000'
DELETE TOP(10000) T3 WHERE F2 < '0000200000'
DELETE TOP(10000) T4 WHERE F2 < '0000200000'
GO 20
SET NOCOUNT ON
DECLARE @I INT = 0;
DECLARE @J INT = 0;
DECLARE @Value INT;
WHILE ( @I < 100 )
BEGIN
SET @J = 0 ;
BEGIN TRAN
WHILE @J < 2000
BEGIN
SET @Value = 1000000 + @I * 2000 + @J
INSERT INTO T1( F1, F2, F3 ) VALUES ( @Value , RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
INSERT INTO T2( F1, F2, F3 ) VALUES ( @Value , RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
INSERT INTO T3( F1, F2, F3 ) VALUES ( NEWID(), RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
INSERT INTO T4( F1, F2, F3 ) VALUES ( NEWID(), RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
SET @J += 1 ;
END
COMMIT
SET @I += 1 ;
END
SET NOCOUNT OFF
GO
這個時候重新查看索引的狀況
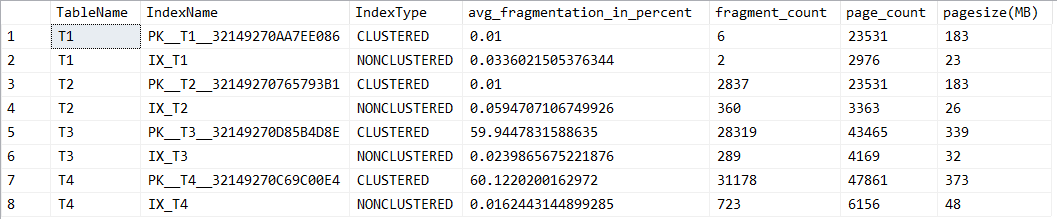
會發現才刪除 1/5 的資料,再增加 1/5 的資料後,使用 GUID 的欄位所搭配的索引破碎程度會非常地的高了。因此在一般會很頻繁變動資料的作業,在使用 GUID 上可能要特別注意一下,如果真的要使用的話,是可以把那個欄位建立成 Unique 索引,選擇用其他欄位來當成 PK 會比較合適一點。
而在跟一些朋友討論的時候,他們表示他們已經已經使用習慣了,要改變這樣的習慣有點困難,而他們也知道會有這樣的問題發生,因此目前都改用 NEWSEQUENCEID() 的方式來給鍵值,那這裡我們再來做一個範例,類似前面的指令去建立一個新的 T5 的資料表,來看看狀況是否會有所改善。
USE DEMO1
GO
CREATE TABLE T5( F1 uniqueidentifier default NEWSEQUENTIALID() primary key, F2 nchar(10), F3 nchar(100) )
GO
CREATE INDEX IX_T5 ON T5( F2 );
GO
SET NOCOUNT ON
DECLARE @I INT = 0;
DECLARE @J INT = 0;
DECLARE @Value INT;
WHILE ( @I < 500 )
BEGIN
SET @J = 0 ;
BEGIN TRAN
WHILE @J < 2000
BEGIN
SET @Value = @I * 2000 + @J
INSERT INTO T5( F2, F3 ) VALUES ( RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
SET @J += 1 ;
END
COMMIT
SET @I += 1 ;
END
SET NOCOUNT OFF
GO
從資料面看起來每次產生的 GUID 就比較有連貫性了,那實際看一下索引破碎的狀況是否會好一點呢 ?
SELECT
OBJECT_NAME(p.object_id) TableName,
i.name IndexName, i.type_desc IndexType,
p.avg_fragmentation_in_percent, p.fragment_count, p.page_count, p.page_count*8/1024 'pagesize(MB)'
FROM sys.dm_db_index_physical_stats(DB_ID('DEMO1'),OBJECT_ID('T5'),NULL,NULL,NULL) p
JOIN sys.indexes i ON p.object_id=i.object_id AND p.index_id=i.index_id
從 DMV 所回傳的結果看起來,似有採用 Int 型態的時候稍微大一點,但至少破碎程度也不會那麼糟糕了。

雖然使用 NEWSEQUENTIALID() 看起來不錯,但要注意它的使用是有限制的,一般來說只能把它用在 CREATE TABLE 或 ALTER TABLE 中,把 NEWSEQUENTIALID() 用在欄位型態是 UNIQUEIDENTIFIER 的欄位 DEFAULT 屬性內,不可以和其他運算合併使用。這點要稍微注意一下,不要只看部分說明就覺得 NEWSEQUENTIALID() 好像比 NEWID() 來的好,要全部把所有有使用的地方都給換掉,那樣可能是不行的。
因此最後如果要結論的話,就如同一個朋友所言 "因為程式不是你寫,DB不是我維護,類似騎車的會罵開車的,開車的會罵騎車的一樣" ,不同的角度去看待問題的出發點是不同的,因此如果您的開發團隊中有 DBA 的成員的話,或許可以大家先討論看看,找出一個大家都可以接受且又可以讓系統好維護的方式。至少也讓 DBA 先了解系統後續可能會有那些地方會造成瓶頸,因此可以先事先預想後續該如何來做維護或者是增加那些 Index 來協助,而非等到系統都上線爆發效能之後,那問題就比較不好處理了。