在使用 SQL 做模糊查詢的時候,如果要查字尾符合的條件時,往往因為不能有效使用索引,導致系統效能不佳的狀況,因此在這裡我們利用 REVERSE 的函數並且搭配計算欄位來反轉資料,讓原本查詢字尾的變成查詢字首,這樣就可以有效運用到索引來提升效能了。
對很多人來說,在 SQL 語法內使用 LIKE 的敘述句來做模糊查詢,這個是很常見的。一般最常見的用法會是 LIKE '字首%' 或者是 LIKE '%字尾' 的模糊查詢方式。而這樣的方式在做查詢的時候,相信大家都很有經驗,前者如果該欄位有建立 INDEX 的情況下,則可能因為估算符合資料的筆數多少,而決定是否會使用索引搜尋;而或者就是索引掃描和資料表掃描,效能就會變成非常的不好。
而這幾天剛好看到 FB 上有朋友在詢問一個 Case,就是使用 LIKE '%字尾' 的時候,因為資料表內有很多筆紀錄,使得這樣搜尋的速度非常慢,因此希望找到比較簡單的方式來做處理。
這裡我做一個範例來做展示,利用 REVERSE 函數搭配計算欄位,這樣可以在使用者幾乎不用修改程式下,而達到不少的效能改善。
1. 首先我先建立一個範例資料庫來做測試,透過迴圈的方式填入一百萬筆的紀錄
CREATE DATABASE DEMO1;
USE [DEMO1]
GO
CREATE TABLE T1( F1 int , F2 nchar(10), F3 nchar(100) )
GO
SET NOCOUNT ON
DECLARE @I INT = 0;
DECLARE @J INT = 0;
DECLARE @Value INT;
WHILE ( @I < 500 )
BEGIN
SET @J = 0 ;
BEGIN TRAN
WHILE @J < 2000
BEGIN
SET @Value = @I * 2000 + @J
INSERT INTO T1( F1, F2, F3 ) VALUES ( @Value , RIGHT( '0000000000'+CAST(@Value AS VARCHAR ),10 ),NEWID() );
SET @J += 1 ;
END
COMMIT
SET @I += 1 ;
END
2. 這裡我們針對可能要查詢的欄位建立索引
USE [DEMO1]
GO
CREATE NONCLUSTERED INDEX T1_F2 ON T1(F2);
GO
CREATE NONCLUSTERED INDEX T1_F3 ON T1(F3);
GO
3. 這個時候我們就可以來下語法測試一下了,我們將這兩個語法透過 SSMS 來執行,並且開啟執行計畫來查看
USE [DEMO1]
GO
select * from T1 where F2 like '%13579'
select * from T1 where F2 like '%13579' OPTION (MAXDOP 1)
從下圖中可以看出來,雖然每個指令符合的都只有 20 筆紀錄,但整個的運算成本不低,使得如果沒有調整參數的話, SQL Server 則會採用平行處理,來提升效能。就算利用 OPTION ( MAXDOP 1 ) 的參數,限制只能使用單核心的狀況下,雖然可以避開平行等待所造成的資源浪費,但效能還是不好。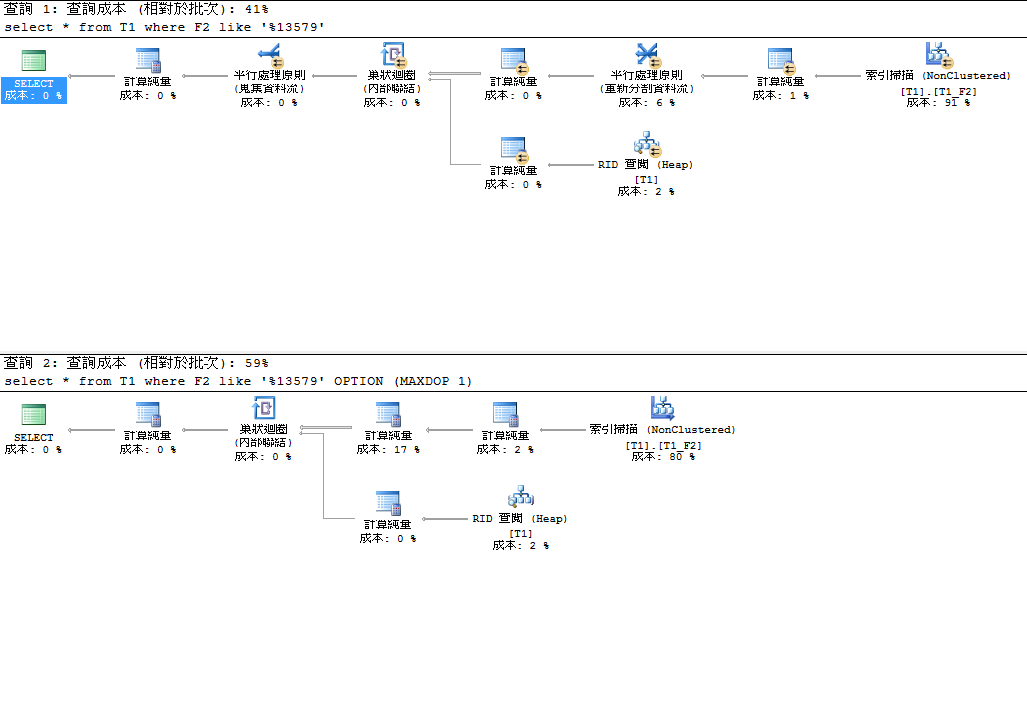
4. 因此為了改善這樣的狀況,我們利用計算欄位和 REVERSE 函數的轉換,針對這個計算欄位加上索引
USE DEMO1
GO
-- 加入計算欄位
ALTER TABLE T1 ADD F2_REVERSE AS ( REVERSE(F2) );
GO
ALTER TABLE T1 ADD F3_REVERSE AS ( REVERSE(F3) );
GO
-- 替計算欄位建立索引
CREATE NONCLUSTERED INDEX T1_F2_REVERSE ON T1(F2_REVERSE);
GO
CREATE NONCLUSTERED INDEX T1_F3_REVERSE ON T1(F3_REVERSE);
GO
5. 建立好之後,我們重新下一次語法來做測試
-- 調整前的指令
select * from T1 where F2 like '%13579'
select * from T1 where F2 like '%13579' OPTION (MAXDOP 1);
-- 調整後的指令
select * from T1 where REVERSE(F2) like '97531%'
select * from T1 where REVERSE(F2) like '97531%' OPTION (MAXDOP 1)
從下圖中可以看出來,當我們搭配 REVERSE 指令之後,這個時候找到的資料筆數是相同的,但指令的效能卻有大幅的提升
因此用這樣的寫法來做改變時候,既有的程式不用做太多的修改,卻可以享有非常大的效能提升。也有效避開原本採用系統預設值,因為平行處理原則的成本臨界值過低,使得估算的成本高於臨界值後,系統啟用平行運算來提升效能,但也因此造成大量的平行等待的資源耗用的問題發生。