常常有人會說使用 LIKE 或比較慢,或者是使用 Substring 會比較慢,到底該怎麼來做選擇呢 ?
早上看到 FB 中有人 Po 了一篇文章 「SQL 「Like +'%'」 與SUBSTRING 進行資料欄位開頭比對」,本來覺得沒有甚麼特別,剛好又遇到有同事轉 Po 給我,跟我說怎麼跟我之前說明的不同,因此決定整理一下自己的想法,來做個說明。
在這個部分我建立一個範例資料表 BigTable 來做個說明
-- 建立資料表
CREATE TABLE [BigTable]
(
A1 INT,
A2 NVARCHAR(10),
A3 VARCHAR(10),
A4 NCHAR(200),
)
GO
DECLARE @I INT;
DECLARE @J INT;
DECLARE @K INT;
SET @J = 0;
-- 產生一千萬筆的資料,為了避免交易記錄檔過大,每一萬筆資料放在一個 Transaction 內
SET NOCOUNT ON;
WHILE @J < 1000
BEGIN
SET @I = 0;
BEGIN TRAN
WHILE @I < 10000
BEGIN
SET @K = @J*10000+@I ;
INSERT INTO [BigTable] ( A1,A2,A3,A4 ) VALUES ( @K, RIGHT('0000000000'+LTRIM(STR(@K)),10), RIGHT('0000000000'+LTRIM(STR(@K)),10), NEWID())
SET @I += 1;
END
COMMIT
SET @J += 1;
END
GO
一開始我們先不建立任何的索引,直接就拿兩種不同的語法來做比較
SET STATISTICS TIME ON
SET STATISTICS IO ON
-- 使用 LIKE
select * from BigTable
where A3 LIKE '00000001%'
-- 使用 Substring
select * from BigTable
where SUBSTRING(A3,1,8) = '00000001'
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
當執行之後,從下圖中可以看出來,這兩個指令都會撈出同樣的資料,對資料表讀取的次數也都相同,時間也都是不到一秒的差異,因為都是採用 Table Scan 的方式去取得資料,因此可以視為這兩指令執行的效能看起來是相同的。
可是,如果當我們在這個 A3 的欄位上建立索引的話,那我們來試試看
CREATE INDEX IX_BigTable ON BigTable(A3)
GO
當建立完索引之後,我們再重新下剛剛同樣的查詢指令,從時間和 IO 的存取數據上看起來,當有配合 Index 的時候,使用 「Like +'%'」的方式,效能會比使用 SubString 的方式來的好。
那為什麼會這樣呢 ? 我們來看一下這兩者執行計畫的差異,會發現當使用 LIKE 語法的時候,執行計畫中會採用「索引搜尋」,而使用 Substring 的話,就只能使用「索引掃描」。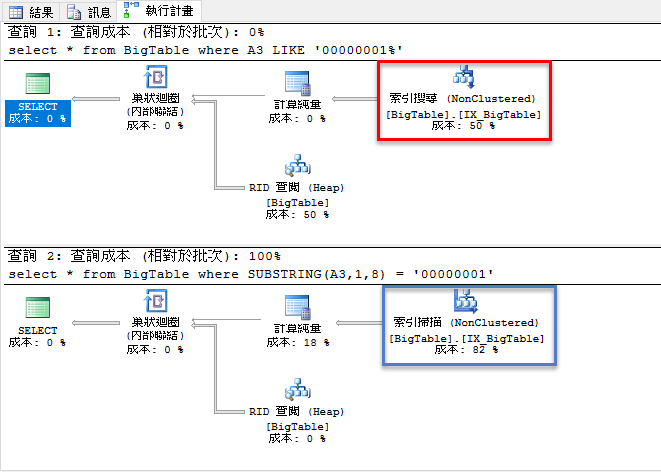
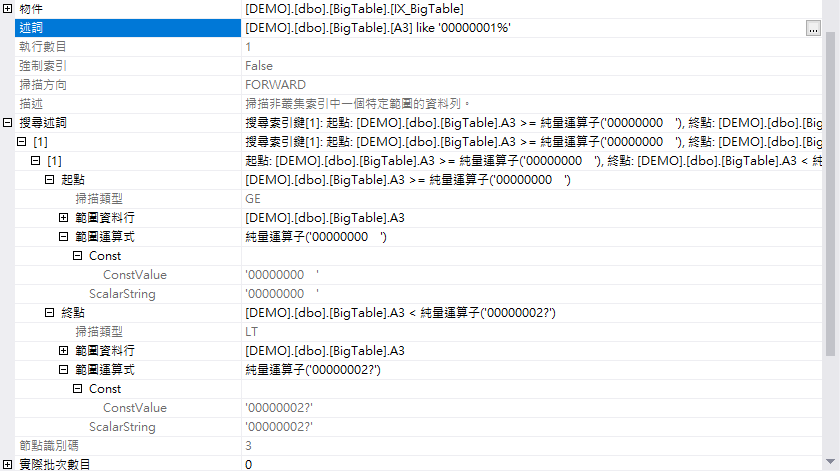
那為什麼使用 LIKE 的話,為什麼可以採用「索引搜尋」而不跟使用 Substring 的方式一樣呢 ? 我們可以更細的來看索引搜尋的那個 Operation ,可以發現當我們使用 「Like +'%'」的方式,資料庫在產生執行計畫的時候,會很聰明的轉換成為起訖資料的方式來做搜尋,因此就可以直接使用 Index 來加速搜尋。但如果使用 Substring 的時候,因為需要把每一筆的那個欄位值丟到 Function 內先做處理才能判斷,因此最多也就只能配合索引掃描了。
那為什麼有些時候有些人做出來的狀況卻是相反的呢 ? 這就有很多的可能性了,有可能他修改前和修改後,剛好資料都已經先載入到記憶體內,或者是因此 SQL Server 變更成為不同的執行計畫,都是有可能造成可能會有不一樣的結果,因此當我們在測試的時候,還是最好要多注意看一下執行計畫和執行統計資訊的結果,這樣才有辦法做出正確的判斷。
如果對這有興趣的朋友,也可以參考另外兩篇的文章