除了重建索引之外,另外一個 Guid 的問題也順便提一下好了
原本只是想寫前面那篇,但想想既然都已經整理好資料,那就再把原本來腳本改變一下,也順便跟大家介紹另外一個案例,在這種形況下也是使用差異備份要注意的一個環節。
首先跟前面的文章類似
-- 建立資料表
CREATE TABLE [BigTable]
(
A1 INT,
A2 NVARCHAR(10),
A3 VARCHAR(10),
A4 NCHAR(36) PRIMARY KEY, -- 關鍵在這裡
)
GO
DECLARE @I INT;
DECLARE @J INT;
DECLARE @K INT;
SET @J = 0;
-- 產生百萬筆的資料,為了避免交易記錄檔過大,每一萬筆資料放在一個 Transaction 內
SET NOCOUNT ON;
WHILE @J < 100
BEGIN
SET @I = 0;
BEGIN TRAN
WHILE @I < 10000
BEGIN
SET @K = @J*10000+@I ;
INSERT INTO [BigTable] ( A1,A2,A3,A4 ) VALUES ( @K, RIGHT('0000000000'+LTRIM(STR(@K)),10), RIGHT('0000000000'+LTRIM(STR(@K)),10), NEWID())
SET @I += 1;
END
COMMIT
SET @J += 1;
END
GO但是這一次跟之前有比較大的區別,在於這次我是採用 Guid 的欄位來當成 Primary Key,而從 SQL Server 2005 開始,Primary Key 預設會採用 Cluster Index。因此上述指令在建立好測試資料之後,我們先來做個備份。
BACKUP DATABASE DEMO
TO DISK='D:\Temp\Backup\Demo_Full.BAK'
WITH NO_COMPRESSION
GO從訊息中可以看到,一開始進行完整備份的時候,我們備份了 22584 頁的資料
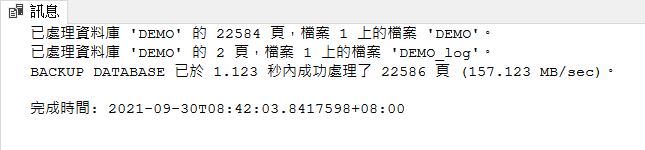
因此在接下來我們將其中的 10000 筆資料刪除,並且新增 10000 筆資料。
-- 第一次異動資料
DELETE FROM BigTable WHERE A1 Between 0 AND 10000-1
GO
DECLARE @I INT;
DECLARE @J INT;
DECLARE @K INT;
SET @J = 0;
BEGIN TRAN
WHILE @I < 10000
BEGIN
SET @K = @J*10000+@I ;
INSERT INTO [BigTable] ( A1,A2,A3,A4 )
VALUES ( @K, RIGHT('0000000000'+LTRIM(STR(@K)),10), RIGHT('0000000000'+LTRIM(STR(@K)),10), NEWID())
SET @I += 1;
END
COMMIT看起來腳本正常,有正常刪除 10000 筆資料後又新增了 10000 筆資料
接下來我們也是來做差異備份
-- 第一次差異備份
BACKUP DATABASE DEMO
TO DISK='D:\Temp\Backup\Demo_DF1.BAK'
WITH NO_COMPRESSION,DIFFERENTIAL
GO從備份的訊息可以看到,雖然我們只有異動 10000 筆資料,但幾乎 95% 的資料頁都有被影響到 ( 21480/22584 )
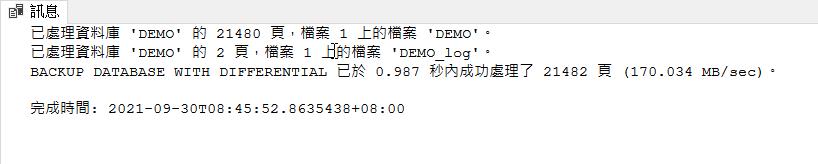
接下來我們也是同樣的方式再做異動,雖然從前面一次的處理就已經有那麼多頁的變更,那後面幾次就只會比他多而不會比他少了,但為了比較我們還是一樣多做幾次
-- 第二次異動資料
DELETE FROM BigTable WHERE A1 Between 10000 AND 20000-1
GO
DECLARE @I INT;
DECLARE @J INT;
DECLARE @K INT;
SET @J = 1;
BEGIN TRAN
WHILE @I < 10000
BEGIN
SET @K = @J*10000+@I ;
INSERT INTO [BigTable] ( A1,A2,A3,A4 )
VALUES ( @K, RIGHT('0000000000'+LTRIM(STR(@K)),10), RIGHT('0000000000'+LTRIM(STR(@K)),10), NEWID())
SET @I += 1;
END
COMMIT-- 第二次差異備份
BACKUP DATABASE DEMO
TO DISK='D:\Temp\Backup\Demo_DF2.BAK'
WITH NO_COMPRESSION,DIFFERENTIAL
GO第二次備份的時候,就幾乎要全部更動了

接下來我們做第三次的更動
-- 第三次異動資料
DELETE FROM BigTable WHERE A1 Between 20000 AND 30000-1
GO
DECLARE @I INT;
DECLARE @J INT;
DECLARE @K INT;
SET @J = 2;
BEGIN TRAN
WHILE @I < 10000
BEGIN
SET @K = @J*10000+@I ;
INSERT INTO [BigTable] ( A1,A2,A3,A4 )
VALUES ( @K, RIGHT('0000000000'+LTRIM(STR(@K)),10), RIGHT('0000000000'+LTRIM(STR(@K)),10), NEWID())
SET @I += 1;
END
COMMIT-- 第三次差異備份
BACKUP DATABASE DEMO
TO DISK='D:\Temp\Backup\Demo_DF3.BAK'
WITH NO_COMPRESSION,DIFFERENTIAL
GO
為了比較差異,最後我們再完整備份一次
BACKUP DATABASE DEMO
TO DISK='D:\Temp\Backup\Demo_Final.BAK'
WITH NO_COMPRESSION
GO看起來總資料頁已經從原本 22584 稍微成長到 22592,看起來還蠻符合預期的結果
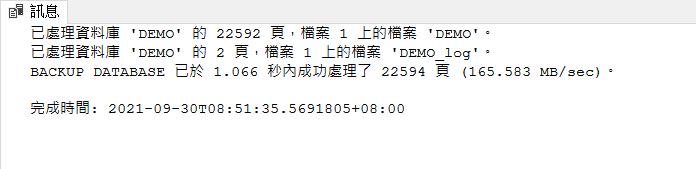
接下來我們查看備份檔案實際大小,再前面的語法中我們為了比較好比較,因此都採用設定不壓縮的方式,這樣比較容易來看出變化。從圖中可以看到,差異備份的檔案幾乎跟完整備份是一樣大的狀況了。
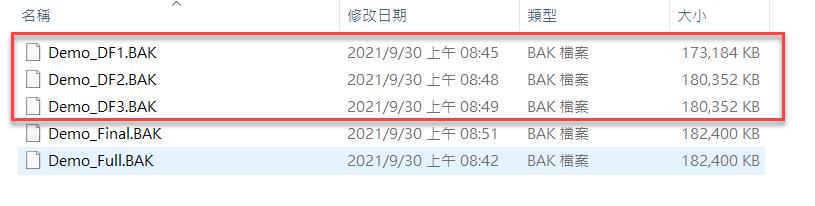
所以當我們在管理資料庫的時候,有時也要注意到資料庫的設計,像在這樣的狀況下,最好不要把 GUID 的欄位設定為 Custer Index ( 我並沒有要去筆戰說用 Guid 當 PK 的優缺點 ),這樣在使用和維護上,應該可以比較有好的效能和效率。