原本在地端可以很順利執行的應用程式,移到雲端後的效能怎麼變成了一場惡夢
前一陣子在跟朋友討論程式撰寫問題的時候,對於要用 Dapper 還是改用 SQL 來做處理,各自有不同的堅持和意見,但因為沒有實際的數據,因此還是無法說服朋友改用 SQL 的 Stored Procedure 來做大量的資料處理。
剛好這個周末在玩 ChatGPT 的時候,就突發奇想說要不然看 ChatGPT 可否自動幫我產生相對應的程式碼,這樣不就可以很快地來做一個比較嗎 ?
因此我就很快的先在我的資料庫建立一個資料表,接下來就用以下的 SQL 語法來做測試,其實這段語法很單純,就是產生 10000 筆資料,然後搭配 Dapper 的擴充,我們一次來做 10000 筆資料的新增
private void InsertData(string connectstr)
{
IDbConnection db = new SqlConnection(connectstr);
db.Open();
var people = Enumerable.Range(1, 10000)
.Select(i => new Person { Id = Guid.NewGuid(), Name = $"Person{i}", Description = Guid.NewGuid().ToString() })
.ToList();
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
db.Execute("INSERT INTO Person (Id, Name,Description) VALUES (@Id, @Name,@Description)", people);
db.Close();
stopwatch.Stop();
Console.Writeln( $"執行時間: {stopwatch.ElapsedMilliseconds} 毫秒" );
}而搭配上述的指令,我同時在地端的 SQL Server 和雲端的 Azure SQL Database 上面建立同樣的資料表來做測試,因此測試出來的數據平均如下
| Local SQL Server | Azure SQL Database S0 | Azure SQL Database S3 | |
| 時間(毫秒) | 2004 | 337450 | 315616 |
從數據上看起來,我們在 Azure SQL Database 雖然 DTU 已經從 S0 (10 DTU) 放大到 S3 (100 DTU),效能上雖然有一點提升,但是遠比地端 SQL Server 上寫入的速度還是相差非常多。但是為什麼會是這樣呢 ? 基本上我們可以在地端的 SQL Server 開啟 SQL Profiler 攔一下相關的 SQL 指令
從下圖中可以看出來,當我們雖然一次給要新增 10000 筆資料,但會變成應用程式要透過網路下 10000 筆 INSERT 的指令,因此在這樣的測試中,網路還是影響很大的測試數據
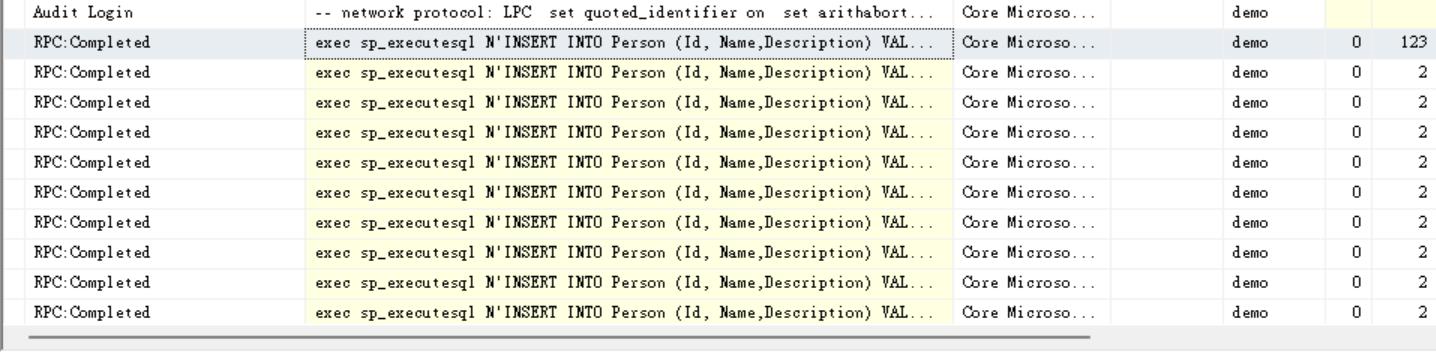
因此我們又將原本的測試,把他改成 Web API 的方式,這樣 Azure Web App 和 Azure SQL Database 都位在同一個地區,這樣網路速度應該可以避免掉,因此又在重作一次測試,把數據整理一下
| 時間(毫秒) | Local SQL Server | Azure SQL Database S0 | Azure SQL Database S3 |
| 地端 WinForm | 2004 | 337450 | 315616 |
| 雲端 Web API | 63024 | 48811 |
這樣速度看起來雖然因為沒有受到網路的延遲而造成的影響,但整體數據上看起來,還是跟我們目標的時間還是有點落差,因此這個時候我們再次使用 ChatGPT , 請他將我們原本使用 Dapper 的範例,改成透過 Bulk Insert 的方式來做處理,看看是否會有所改善。而此時 ChatGTP 居然提供一段令我驚豔的程式碼,透過下面這段的擴充方法,將原本的 List 的資料可以轉換成 DataTable , 這樣就可以搭配 SqlBulkInsert 的來做處理
public static class Extensions
{
public static DataTable ToDataTable<T>(this IEnumerable<T> items)
{
var properties = typeof(T).GetProperties();
var dataTable = new DataTable();
foreach (var property in properties)
{
dataTable.Columns.Add(property.Name, property.PropertyType);
}
foreach (var item in items)
{
var values = properties.Select(p => p.GetValue(item)).ToArray();
dataTable.Rows.Add(values);
}
return dataTable;
}
}因此我的程式碼被調整成為這樣
public async Task<ActionResult> BulkInsert()
{
var person = GetSampleData();
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
using (var bulkCopy = new SqlBulkCopy(_config.GetConnectionString("DefaultConnection")))
{
bulkCopy.DestinationTableName = "Person";
bulkCopy.WriteToServer(person.ToDataTable());
}
stopwatch.Stop();
return Ok(new { Result = person.Count , Time = stopwatch.ElapsedMilliseconds });
}而透過這樣的處理,當我們跟原本使用 Dapper 去塞入 10000 筆資料來做比對
| Azure SQL Database S0 | Azure SQL Database S3 | |
| 使用 Dapper Execute | 63024 | 48811 |
| 使用 SQL Bulk Insert | 4276 | 1076 |
這樣的處理在效能上就能有大幅的改善了。但如果不要用 Bulk Insert 的指令 , 而是用 Stored Procedure 內包成一個交易去填入資料,那其實效果跟 Bulk Insert 的指令差不多,有興趣的朋友可以參考以下的指令來測試看看
SET NOCOUNT ON
DECLARE @Table Table
(
Id uniqueidentifier,
Name NCHAR(20),
Description NCHAR(100)
)
DECLARE @PTR INT = 1
WHILE @PTR <= 10000
BEGIN
INSERT INTO @Table VALUES ( NewID(), 'Person'+CAST(@PTR AS VARCHAR) , NewID() )
SET @PTR += 1
END
INSERT INTO Person SELECT * FROM @Table