Microsoft透過了Cognitive Service API的服務,提供影片的人像辨識,相片樣貌比對以及年齡的判斷等等的功能
這篇文章會說明如何透過影片 Video API,進行影片中人臉的辨識
要使用Microsoft Cognitive Service的服務,必須先申請服務的試用
連上Microsoft Cognitive Service的網頁後,點選Get Start for free的字樣,並登入Microsoft Live ID
在Request new trials的地方,要勾選[Video Preview]的項目,然後按下[Subscribe]
完成申請之後,會看到在Video Preview的地方,會有Key 1與Key 2,按下Show的連結,可以看到提供使用的Key字串,請把這組字串記下來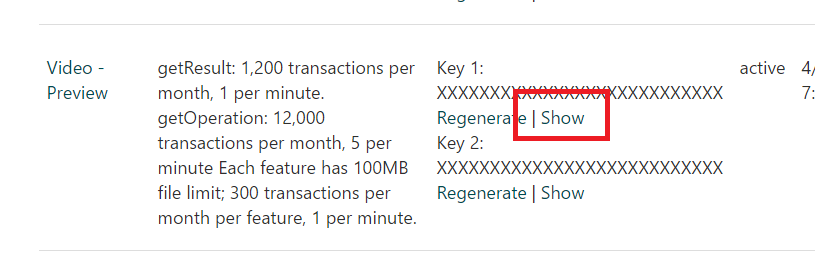
記完Key之後,就可以查看一下Cognitive Service所提供,在影片人臉辨識上有什麼可用的API,API的連結在這裡
https://www.microsoft.com/cognitive-services/en-us/video-api
https://dev.projectoxford.ai/docs/services/565d6516778daf15800928d5/operations/565d6517778daf0978c45e39
在透過影片進行人臉辨識的功能,會用到的主要有三個API,分別是
Face Detection and Tracking:指定要分析的影片網址或是資料流
Get Operation Result:取得指定影片的分析狀態
Get Result Video:取得影片的分析結果
Face Detection and Tracking這個API,可以透過指定網路上的影片網址的方式,或是直接將影片以資料流的方式上傳,Cognitive Service會在接收到檔案後,開始進行影片人臉的辨識分析,然後回傳這段影片在Cognitive Service上分析狀態的API網址,與分析結果的API網址
這段程式碼,可以將網路上的影片,傳送到Cognitive Service進行分析
static async void MakeRequest()
{
var client = new HttpClient();
var queryString = HttpUtility.ParseQueryString(string.Empty);
// Request headers
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", "[在這裡輸入Key]");
var uri = "https://api.projectoxford.ai/video/v1.0/trackface?" + queryString;
HttpResponseMessage response;
// Request body
string strContent = "{\"url\":\"[在這裡輸入要分析影片的網址\"}";
byte[] byteData = Encoding.UTF8.GetBytes(strContent);
using (var content = new ByteArrayContent(byteData))
{
content.Headers.ContentType = new MediaTypeHeaderValue("application/json");
response = await client.PostAsync(uri, content);
}
}
執行完這段程式後,response物件會回傳一個很重要的Header [Operation-Location]回來,這個屬性值會告訴我們,這段影片在Cognitive Service上的oid與資料提供的網址
接取的方式如下面程式碼所示
if (response.StatusCode == System.Net.HttpStatusCode.Accepted)
{
// strOperationUrl是可以取得這段影片目前分析的狀態
string strOprtationUrl = ((string[])response.Headers.GetValues("Operation-Location"))[0];
// strContentUrl可以取得這段影片分析完成後,人臉辨識的資訊
string strContentUrl = strOperationUrl + "/content";
}
else
{
string strErrorMessage = response.ReasonPhrase;
}
若是有接收到Operation-Location的Header值,代表該影片有開始進行辨識的動作了,要知道這段影片有沒有被辨識完成,也是必須透過API去作確認的,確認的方式如下面的程式碼所示
static async void MakeRequest()
{
var client = new HttpClient();
var queryString = HttpUtility.ParseQueryString(string.Empty);
// Request headers
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", "[在這裡輸入Key]");
var uri = "[將Operation-Location參數回傳的Url放進來]?" + queryString;
var response = await client.GetAsync(uri);
}
一樣的,這邊只是向API要求該影片的處理狀態,接下來透過response取回的資訊要進行處理才能知道影片目前的狀態
if (response.StatusCode == System.Net.HttpStatusCode.OK)
{
Stream stream = await response.Content.ReadAsStreamAsync();
byte[] bytes = new byte[stream.Length];
stream.Position = 0;
stream.Read(bytes, 0, (int)stream.Length);
try
{
CognitiveModels.FaceDetection objFaces = JsonConvert.DeserializeObject<CognitiveModels.FaceDetection>(Encoding.ASCII.GetString(bytes));
string strProgress = objFaces.status + ":" + objFaces.progress + "%";
if (objFaces.progress == 100)
{
// 影片已經分析完成
}
}
catch (Exception ex)
{
string strErrorMessage = ex.Message;
}
}
else
{
string strErrorMessage = response.ReasonPhrase;
}
這部份的程式碼主要是在將取得的response接收回來後,將回傳的JSON資料轉成Object,並取得目前的status與progress處理進度,當progress為100時,代表該影片已經分析完成了
影片分析完成後,就必須利用第三個API,Get Result Video,取得人臉辨識的結果,取得的方式如下面程式
static async void MakeRequest()
{
var client = new HttpClient();
var queryString = HttpUtility.ParseQueryString(string.Empty);
// Request headers
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", "[在這裡輸入Key]");
var uri = "[從Operation-Location參數取得的網址]/content?" + queryString;
var response = await client.GetAsync(uri);
}
在取得辨識結果的API網址,需要在Operation-Location參數後面加上/content,接收到的response也同樣的必須進行處理,接收的方式如下
if (response.StatusCode == System.Net.HttpStatusCode.OK)
{
// 取得分析的結果
Stream stream = await response.Content.ReadAsStreamAsync();
byte[] bytes = new byte[stream.Length];
stream.Position = 0;
stream.Read(bytes, 0, (int)stream.Length);
string strContent = Encoding.ASCII.GetString(bytes);
// 取得人臉辨識的資訊
CognitiveModels.FaceDetectionResult objFaces = JsonConvert.DeserializeObject<CognitiveModels.FaceDetectionResult>(strContent);
// 找出影片定義資訊
int intTimeScale = objFaces.timescale;
int intFrameRate = objFaces.framerate;
}
else
{
string strErrorMessage = response.ReasonPhrase;
}
在這裡很簡單的說明一下,回傳的資料主要會用到Timescale,每一個fragments都會有start、duration與interval這三個屬性,而每一個fragments都會有許多的Event,Event下才會有人臉辨識出來的x,y,width,height,id等等的資訊,因為timescale與interval,影片長短之間有一些計算的關係,相關的作法建議有興趣的人直接開啟程式來看會比較快。
在範例程式中,開啟程式後,可以選擇要上傳本機影片,或是直接給一個Internet上的影片網址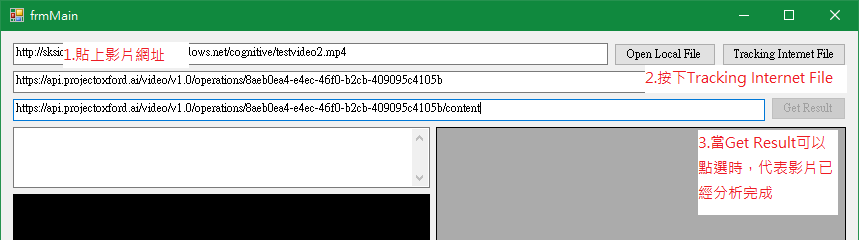
按下Tracking Internet File,或是Open Local File進行檔案上傳後,程式會自動取得Operation-Location的網址,並每90秒自動查詢目前影片的分析狀態
當影片已經分析完成後,,下方的Get Result會開啟供點擊,點擊後,就會從content的API上取得人臉辨識的資料,並開始同步播放影片以及辨識出來的結果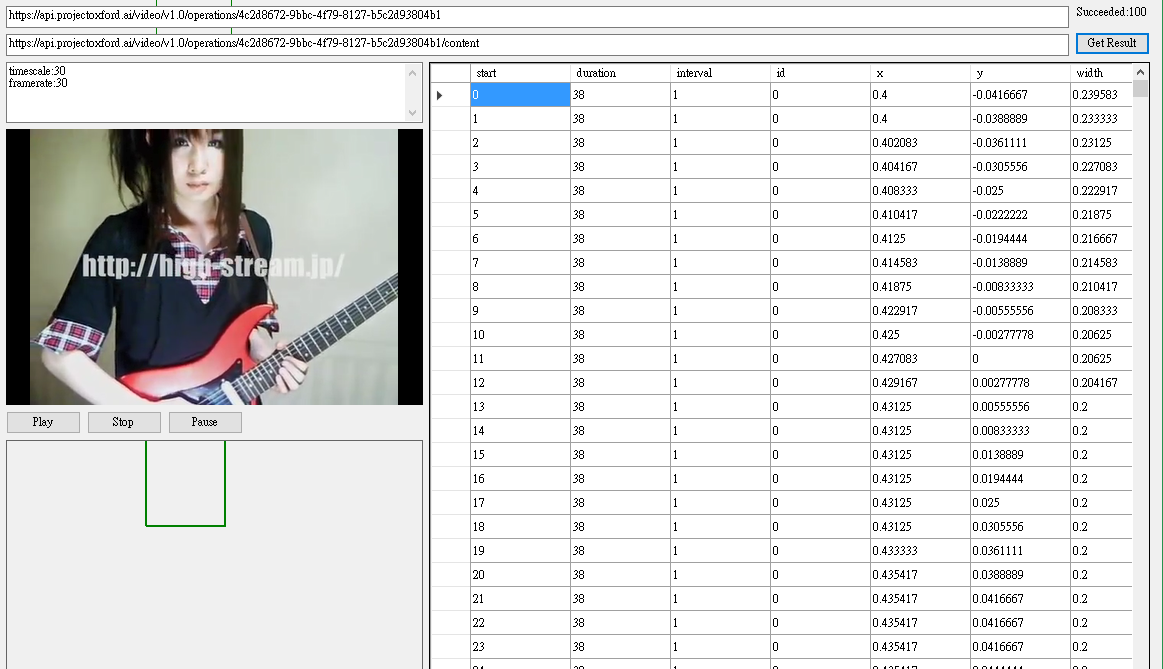
範例程式參考:
https://github.com/madukapai/maduka-Cognitive
參考內容:
Face Detection and Tracking
Get Operation Result
Get Result Video