在微軟的雲端辨識應用中,有包含了一個很有趣的功能,Computer Vision
這個功能可以將影像中的內容轉化為文字描述,並將人臉也能夠辨識出來,當然得到的結果會是英文的內容
所以在這篇文章中,除了會說明怎麼用ComputerVision作影像的辨識外,還會加上Translator Text的功能說明,將英文的辨識結果轉換為中文
因為圖片辨識與文字轉換是兩件不同的事,所以在這裡會分成兩段來進行說明,第一段會先說明如何運用ComputerVision作圖片的辨識
1.首先我們先在Azure上建立一個名為[電腦視覺] (Coputer Vision) 的新服務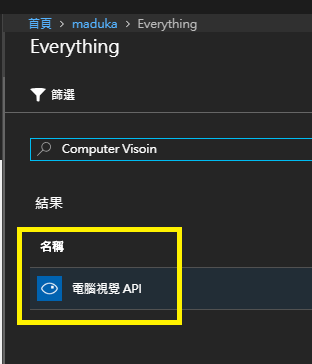
2.建立完成後,把Key的值記下來,在程式碼中會用得到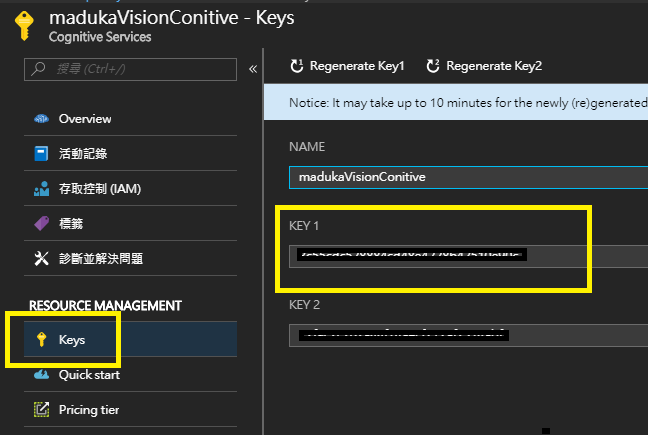
3.把[Overview]裡面的[Endpoint]也記下來,程式中也會用得到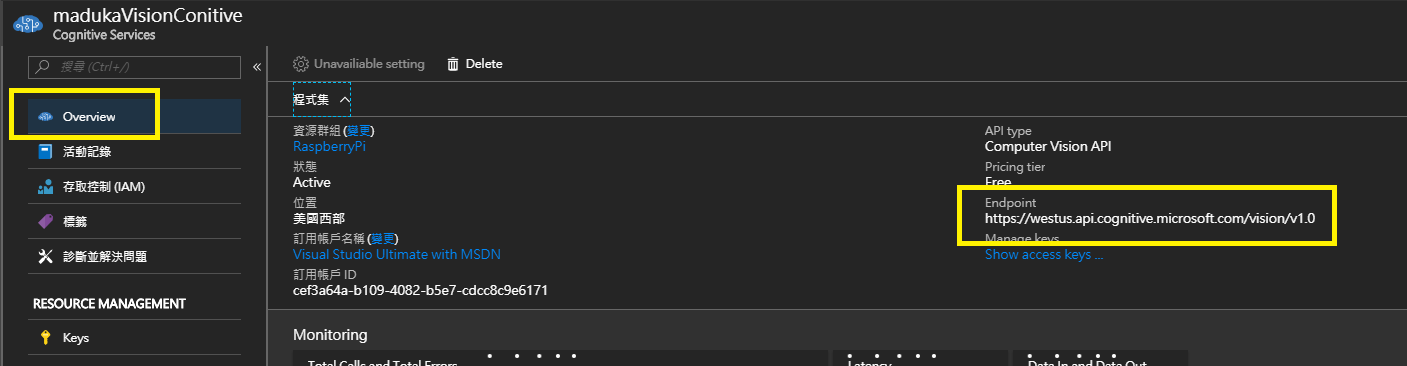
4.接著在Visual Studio中繪製下面的畫面,拉出一個要用來顯示照片以及ComputerVision結果的控制項,最下方的Translator的按鈕可以先拉出來,但是在第一段中並不會用到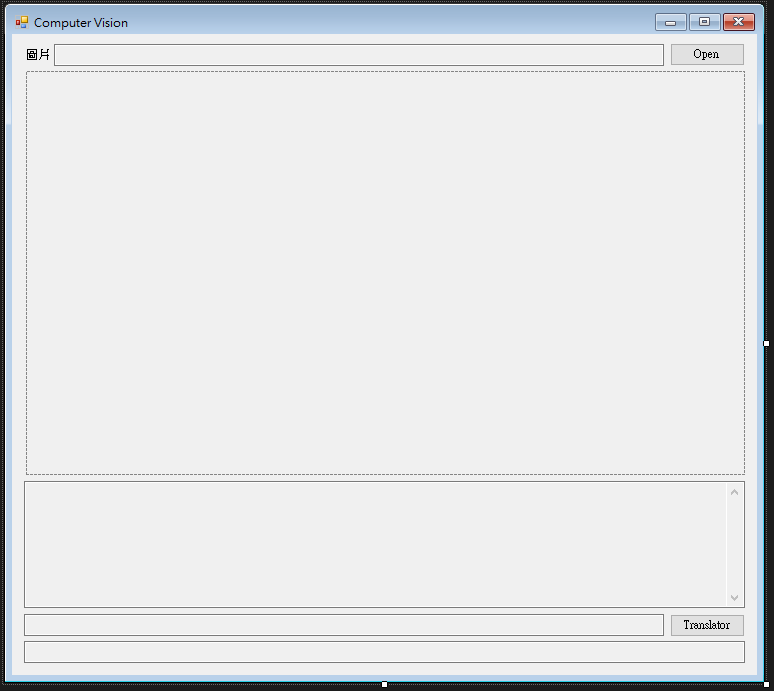
5.在專案中,加入[Microsoft.ProjectOxford.Vision]的Nuget套件
6.在點選Open按鈕的動作中,加上下面的程式碼
string CompoterVisionApiRootUrl = "[在這裡放上ComputerVision的Endpoint]"; // EX:"https://westus.api.cognitive.microsoft.com/vision/v1.0";
string CompoterVisionApiKey = "[在這裡放上ComputerVision的Key]";
VisionServiceClient visionClient;
FacePanelUtility objFace;
public frmMain()
{
InitializeComponent();
visionClient = new VisionServiceClient(CompoterVisionApiKey, CompoterVisionApiRootUrl);
objFace = new FacePanelUtility() { TargetPanel = plImage };
plImage.Paint += objFace.OnPaint;
}
/// <summary>
/// 開啟圖片對話視窗
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void btnOpenImage_Click(object sender, EventArgs e)
{
try
{
FileStream fs = File.Open(openFileDialog1.FileName, FileMode.Open);
// 指定要辨識出的內容有哪些
VisualFeature[] visualFeatures = new VisualFeature[] {
VisualFeature.Color, VisualFeature.Description,
VisualFeature.Faces, VisualFeature.Tags };
// 進行圖片的ComputerVision辨識
AnalysisResult objResult = await visionClient.AnalyzeImageAsync(fs, visualFeatures);
fs.Close();
// 放入分析完之後的JSON內容
txtComputerVisionResult.Text = JsonConvert.SerializeObject(objResult);
// 放入說明
txtCaptions.Text = "";
for (int i = 0; i < objResult.Description.Captions.Length; i++)
txtCaptions.Text += objResult.Description.Captions[i].Text + ".";
txtImagePath.Text = openFileDialog1.FileName;
plImage.BackgroundImage = Image.FromFile(openFileDialog1.FileName);
// 畫出臉的框
objFace.RenderFaceRectangle(objResult.Faces);
}
catch (Exception e)
{
string strErrMsg = e.Message;
}
}
這一段的程式碼,主要的功能就是將從本機中讀取的檔案,送入至ComputerVision進行辨識,然後將辨識得到的所有結果放入到文字方快塊中,最後若是有找到人臉的話,就透過畫框的方式把人臉框出來
7.這樣一來,我們就可以看到選定的圖片,被辨識出來之後的結果與說明文字,當然還有加上人臉畫框的結果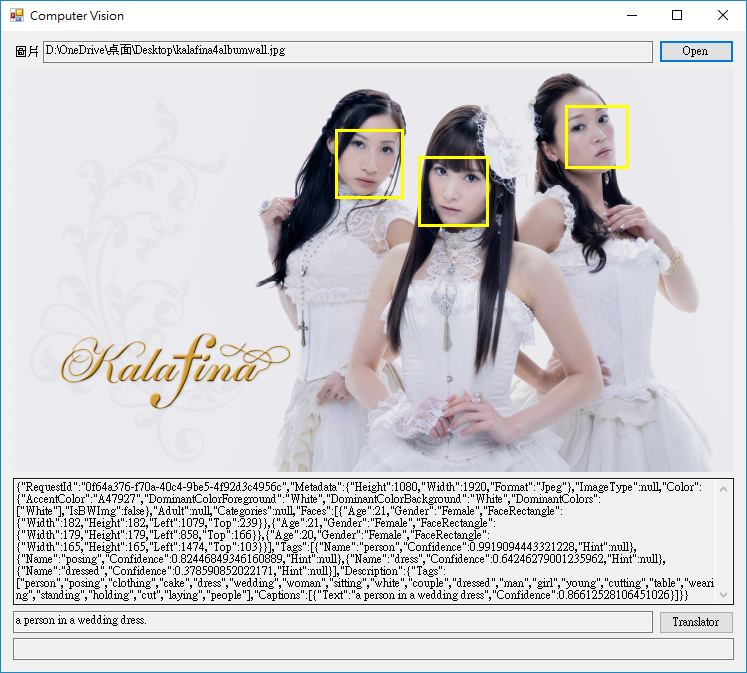
8.有了透過ComputerVision辨識出來的文字,接下來我們就可以透過Translator Text API的功能,將英文字翻譯成我們所需要的中文內容,所以在雲端中必須建立一個名為[翻譯文字 API]的服務
9.建立完成後,一樣將Key記下來,程式中會用到
10.接著在程式中,按下[Translator]按鈕的動作裡,加上下面的程式碼
string TranslaterUrl = "https://api.microsofttranslator.com/V2/Http.svc/Translate";
string TranslaterApiKey = "[這裡放上翻譯文字 API的KEY]";
/// <summary>
/// 將結果文字進行翻譯成中文的動作
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void btnTranslator_Click(object sender, EventArgs e)
{
string strToLang = "zh-Hant";
string strText = txtCaptions.Text;
string strTranslatorUrl = $"{TranslaterUrl}?to={strToLang}&text={strText}";
List<HeaderObject> objHeaders = new List<HeaderObject>();
objHeaders.Add(new HeaderObject() { Key = "Ocp-Apim-Subscription-Key", Value = TranslaterApiKey });
// 呼叫API取得翻譯的結果
HttpStatusCode code = HttpStatusCode.OK;
string strResult = this.CallAPI(strTranslatorUrl, "GET", objHeaders, "", out code);
txtTranslatorResult.Text = strResult;
XmlDocument xmldoc = new XmlDocument();
xmldoc.LoadXml(strResult);
txtTranslatorResult.Text = xmldoc.InnerText;
}
在這段程式碼中,我們將要翻譯的文字內容,以及要翻譯的目的語言作為URL的參數,並透過GET的方式傳入到微軟翻譯文字用的API中
但是因為取回的文字內容是採用XML的格式回傳的,所以必須再透過XmlDocument作處理,將翻譯的結果取回並顯示在畫面上
11.最後我們可以看到結果,翻譯文字的API服務,將英文確實的翻譯成中文了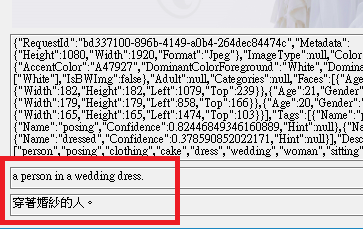
微軟在雲端提供的辨識服務相當的多種,多種辨識的功能整合運用,將會是未來提供企業非常有幫助的服務,就以本文章所提及的兩項功能,就足以進行多種情境的處理並傳回不同語系的說明,縮短了企業研發的時間與成本
參考資料:
Computer Vision
Computer Vision API v1.0 Analyze Image
Translator Text API
Microsoft Translator Text API
Github範例程式下載
https://github.com/madukapai/maduka-ComputerVision