系列:從鐵人賽到 Agent Orchestration — AI 自動建立 .NET 測試的完整方案(4)
前言
上一篇介紹了 VS Code v1.109 帶來的技術突破 — Agent Skills GA、Custom Agent 的 Subagent 機制、Context 隔離。這些能力組合在一起,讓 Agent Orchestration 從概念變成了可以實作的架構。
有了技術基礎之後,接下來的問題是:架構到底該怎麼切?
一開始我嘗試過 3 個 Subagent(把 Executor 的工作併進 Writer),但很快發現 Writer 的 Context Window 會被 Skills 內容和編譯錯誤訊息同時擠壓。最後定案的是 1 Orchestrator + 4 Subagents — 這篇文章會拆解這個架構的設計決策與分工策略。
前置設定
在使用 Agent Orchestration 之前,需要確認 VS Code 的相關設定已正確配置。開啟設定檔(Ctrl+Shift+P → Preferences: Open User Settings (JSON)),確認以下設定:
{
// 允許 custom agents 作為 subagent 被調用(必要)
"chat.customAgentInSubagent.enabled": true,
// AI 推理深度(建議用 high 以獲得更好的推理品質)
"github.copilot.chat.responsesApiReasoningEffort": "high",
// Agent 檔案搜尋位置
"chat.agentFilesLocations": {
"${workspaceFolder}/.github/agents": true,
"~/.vscode/agents": true
}
}
其中 chat.customAgentInSubagent.enabled 是 Agent Orchestration 能運作的前提 — 沒有這個設定,Orchestrator 無法呼叫任何 Subagent。chat.agentFilesLocations 則決定 VS Code 從哪些路徑載入 .agent.md 檔案,.github/agents/ 是預設路徑,不設定也會自動偵測。
更完整的設定說明請參考上一篇文章的「啟用相關設定」段落。
架構總覽
整個 Unit Test Orchestrator 採用 1 Orchestrator + 4 Subagents 的架構,5 個 Agent 定義檔都放在 .github/agents/ 目錄下:
.github/agents/
├── dotnet-testing-orchestrator.agent.md # 指揮中心
├── dotnet-testing-analyzer.agent.md # 程式碼分析器
├── dotnet-testing-writer.agent.md # 測試撰寫器
├── dotnet-testing-executor.agent.md # 測試執行器
└── dotnet-testing-reviewer.agent.md # 品質審查器使用者只需要與 Orchestrator 互動,它會依序委派 4 個 Subagent 完成從分析到審查的完整流程:
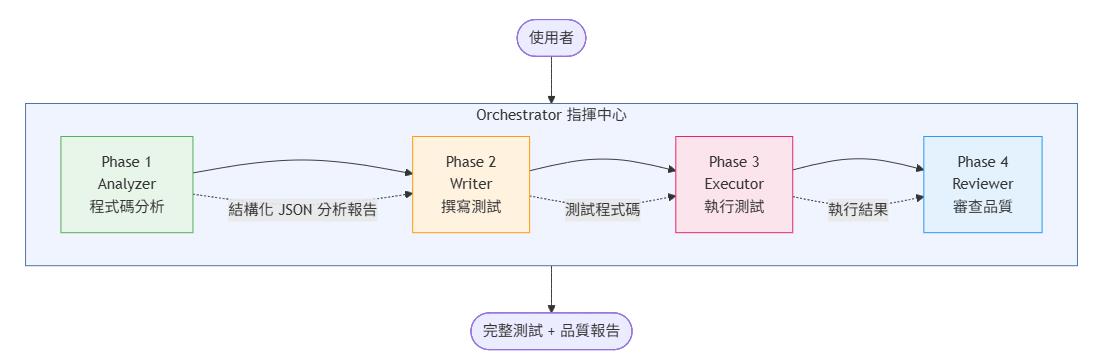
每個 Subagent 都有獨立的 Context Window,這是整個架構能運作的關鍵 — Orchestrator 的主 Context 從約 39K tokens 降到約 12K tokens(減少 69%)。
每個 Subagent 都有獨立的 Context Window,這是整個架構能運作的關鍵 — Orchestrator 的主 Context 從約 39K tokens 降到約 12K tokens(減少 69%)。
Orchestrator — 指揮中心
Orchestrator 是整個架構的核心,但它的角色是「指揮」而不是「執行」。
核心職責
- 接收使用者需求
- 嚴格按序委派 4 個 Subagent(Analyzer → Writer → Executor → Reviewer)
- 傳遞每個階段的輸出給下一個階段
- 整合最終結果回報使用者
HARD STOP 規則
Orchestrator 的 .agent.md 定義了嚴格的限制,這些限制是架構正確運作的保證:
## ⛔ HARD STOP Constraints
The Orchestrator MUST NEVER:
- ❌ Read any SKILL.md file
- ❌ Write any C# test code
- ❌ Modify any .csproj file
- ❌ Skip any of the 4 stages為什麼要「限制」Orchestrator 的能力?
老實說,第一版的 Orchestrator 我沒有加這些限制。結果 AI 很「熱心」地直接讀了 SKILL.md、跳過 Analyzer 就開始寫測試。測試品質當然不好 — 因為它根本不知道被測類別用了 TimeProvider。
所以 HARD STOP 規則是被「教訓」出來的。如果 Orchestrator 可以直接讀取 SKILL.md、直接寫程式碼,就會發生以下問題:
- Context Window 爆炸:29 個 Skills 的 SKILL.md 內容加起來非常龐大,全部載入會擠壓其他工作的空間
- 職責混亂:當指揮者同時也是執行者,就很難確保每個步驟都被正確完成
- 品質不可控:跳過 Analyzer 直接寫測試,就無法根據程式碼特徵選擇正確的技術
HARD STOP 規則強制 Orchestrator 只做「指揮」的事,確保每個 Subagent 在自己的 Context Window 中獨立運作。
Frontmatter 定義
---
name: dotnet-testing-orchestrator
description: '.NET 單元測試指揮中心 — 分析被測試目標、決定技術組合、委派 subagent 撰寫、執行與審查測試'
argument-hint: '描述要測試的類別/方法,例如「OrderProcessingService 的 ProcessOrder 方法」'
tools: ['agent', 'read', 'search', 'search/usages', 'search/listDirectory']
agents: ['dotnet-testing-analyzer', 'dotnet-testing-writer', 'dotnet-testing-executor', 'dotnet-testing-reviewer']
model: ['Claude Sonnet 4.6 (copilot)', 'Claude Opus 4.6 (copilot)']
---
agents: 欄位明確列出可呼叫的 4 個 Subagent,這是 VS Code Subagent 機制的白名單控制。tools: 中有 agent 工具,這是呼叫 Subagent 的關鍵。
注意 Orchestrator 的 tools 中沒有 edit 和 execute/* — 因為它不需要修改檔案或執行命令,這些是 Writer 和 Executor 的職責。
自我檢查清單
HARD STOP 規則要怎麼落實?光寫「禁止」不夠,AI 在長對話中容易忘記限制。所以 Orchestrator 的 .agent.md 中內建了一份自我檢查清單,在每次行動前觸發:
### 自我檢查清單
在每次行動前,問自己:
- 我是否正在嘗試讀取 SKILL.md?→ **停止,這是 Writer 的工作**
- 我是否正在嘗試撰寫 C# 程式碼?→ **停止,委派給 Writer**
- 我是否正在嘗試執行 `dotnet build` 或 `dotnet test`?→ **停止,委派給 Executor**
- 我是否已經收到 Analyzer 的分析報告?→ 沒有的話,**先委派 Analyzer**
這個設計的靈感來自飛行員的 checklist — 不是信不過飛行員的能力,而是在高壓環境下,結構化的檢查比記憶更可靠。實測中,加入這份清單後,Orchestrator 越權行為從約 30% 降到接近 0%。
執行進度顯示規範
Agent Orchestration 的一個實際問題是:使用者不知道目前執行到哪裡了。4 個 Subagent 依序執行,整個流程可能需要幾分鐘,如果沒有任何進度提示,使用者只能盯著 spinner 等。
所以 Orchestrator 的 .agent.md 定義了必要的進度輸出:
| 動作時機 | 必輸出文字 |
|---|---|
| 委派 Analyzer 前 | 階段 1:委派分析(Analyzer) |
| Analyzer 回傳後 | Analyzer 分析完成!識別出 N 個方法、Y 個依賴,需要 [技術清單]。現在委派 Writer 撰寫測試。 |
| 委派 Writer 前 | 階段 2:委派撰寫(Test Writer) |
| Writer 回傳後 | Writer 完成!已建立測試檔案,共 N 個測試案例。現在委派 Executor 建置與執行。 |
| 委派 Executor 前 | 階段 3:委派執行(Test Executor) |
| Executor 回傳後 | 全數通過!N 個測試案例通過,修正 Y 次。現在委派 Reviewer 進行品質審查。 |
| 委派 Reviewer 前 | 階段 4:委派審查(Test Reviewer) |
每個階段之間有明確的過渡摘要,使用者可以即時掌握目前正在執行哪個環節、上個環節的結果是什麼。
四個 Subagent 的角色定位
Orchestrator 依序委派 4 個 Subagent,每個都有明確的職責邊界和獨立的 Context Window。
Analyzer — 程式碼分析器
Phase 1 的執行者。負責深度分析被測類別的結構 — 建構子依賴、方法簽章、目標分類(Service / Validator / Legacy)。最重要的輸出是 requiredTechniques 列表,這份列表決定了 Writer 需要載入哪些 Skills。
Analyzer 不載入任何 Skills,靠 LLM 自身的程式碼理解能力完成分析。
Frontmatter 定義:
---
name: dotnet-testing-analyzer
description: '分析 .NET 被測試目標的類別結構、依賴項、需要的測試技術'
user-invokable: false
tools: ['read', 'search', 'search/usages', 'search/listDirectory']
model: Claude Sonnet 4.6 (copilot)
---
工具選擇的考量:Analyzer 只需要讀取和搜尋程式碼,不需要修改任何檔案,所以 tools 中沒有 edit。search/usages 讓它能追蹤介面的實作位置,search/listDirectory 用來掃描測試專案中既有的基礎設施。
Analyzer 有一個重要的分析流程 — 目標類型識別。讀取被測類別後,它會立即判斷目標屬於哪種類型:
- Service(一般服務類別):走標準的建構子依賴 + 方法簽章分析
- Validator(FluentValidation 驗證器):跳過方法簽章分析,改為掃描建構子中的
RuleFor、SetValidator、Must等規則定義 - Legacy(有靜態依賴的舊程式碼):掃描靜態方法呼叫、寫死的資料,標記不可 Mock 的依賴
這個分類直接影響後續 Writer 使用的測試策略 — Validator 類型使用 TestValidate() 模式,Legacy 類型使用 Characterization Test 模式。
Writer — 測試撰寫器
Phase 2 的執行者,也是整個架構中唯一會大量載入 Skills 的 Subagent。根據 Analyzer 產出的 requiredTechniques,使用 read 工具明確載入對應的 SKILL.md(一般 3~5 個),在獨立的 Context Window 中依照 12 條撰寫規範產出完整的測試程式碼。
這裡的關鍵是明確使用 read 工具讀取 SKILL.md,而不是等待 AI 自動觸發 — 這正是解決第二篇文章提到的觸發問題的核心設計。Writer 不會 build 或執行測試,這是 Executor 的職責。
Frontmatter 定義:
---
name: dotnet-testing-writer
description: '根據分析結果載入對應的 Agent Skills,撰寫符合最佳實踐的 .NET 單元測試'
user-invokable: false
tools: ['read', 'search', 'create', 'edit', 'execute/getTerminalOutput', 'execute/runInTerminal',
'read/terminalLastCommand', 'read/terminalSelection']
model: ['Claude Sonnet 4.6 (copilot)', 'GPT-5.1-Codex-Max (copilot)']
---Writer 的 tools 比 Analyzer 多了 create、edit 和終端機相關工具。create 用來建立新的測試檔案,edit 用來修改既有檔案和 .csproj;終端機工具用來執行 dotnet list package --outdated 查詢套件可升級版本 — 這是為了確保 .csproj 中的套件版本不會停留在 SKILL.md 記載的最低版本上。
Writer 的 model 陣列中有兩個模型(Claude Sonnet 4.6 和 GPT-5.1-Codex-Max),第一個可用的會被採用。這個設計讓 Writer 在主模型不可用時有備援方案。
Writer 的核心工作流程包含六個步驟:
- 載入技術型 Skills — 根據
requiredTechniques清單,用read工具讀取每份 SKILL.md - 掃描既有測試 Pattern — 檢查測試專案是否有
AutoDataWithCustomization等既有基礎設施,有就沿用 - 讀取被測試目標原始碼 — 包含被測類別、依賴介面、相關 Model/DTO
- 查詢可升級套件版本 — 執行
dotnet list package --outdated,作為版本決策的唯一權威來源 - 撰寫測試程式碼 — 依照 12 條撰寫規範產出完整測試(AAA Pattern、中文三段式命名、AwesomeAssertions 等)
- 回傳結果 — 測試程式碼、使用的 Skills 清單、新增的 NuGet 套件、測試檔案路徑
Executor — 測試執行器
Phase 3 的執行者。採用 Build-first 策略,先確認編譯通過再執行測試。如果遇到編譯錯誤或測試失敗,會進入修正迴圈(最多 3 輪)。
Executor 載入的 dotnet-test Skill 並非本專案自製,而是引用社群中 Oleksii Nikiforov 發佈的 dotnet-test Skill,不計入本專案的 29 個 Skills 數量中,但是 Executor 運作時的重要依賴。
Frontmatter 定義:
---
name: dotnet-testing-executor
description: '建置與執行 .NET 單元測試,處理編譯錯誤與測試失敗的修正迴圈'
user-invokable: false
tools: ['read', 'search', 'create', 'edit', 'execute/getTerminalOutput', 'execute/runInTerminal',
'read/terminalLastCommand', 'read/terminalSelection', 'execute/createAndRunTask']
model: Claude Sonnet 4.6 (copilot)
---
Executor 的工具配置是四個 Subagent 中最完整的 — 它需要 create 和 edit 來建立或修正測試程式碼,需要完整的終端機工具來執行 dotnet build 和 dotnet test,還多了 execute/createAndRunTask 用來建立 VS Code Task 執行長時間建置。
修正迴圈的設計考量: 為什麼是 3 輪而不是 5 輪或無限重試?實測中發現,大多數問題(缺少 using、Mock 設定錯誤、型別不匹配)都能在 2 輪內解決。如果 3 輪後仍有失敗,通常代表 Writer 的測試邏輯本身有問題,繼續重試只會消耗 Context Window 而不會收斂。此時回報 Orchestrator「需要 Writer 介入」是更有效的策略。
Executor 的 .agent.md 中還內建了常見修正模式的對照表,例如 CS0246 通常是缺少 using 或 NuGet 套件、CS1061 通常是方法名稱或屬性名稱與被測目標不一致。這些 pattern 讓 Executor 能快速定位問題,而不是每次都從頭分析。
Reviewer — 品質審查器
Phase 4 的執行者,也是最終的品質把關者。與 Writer 的動態載入不同,Reviewer 採用固定 + 條件的 Skills 載入策略 — 固定載入 3 個品質型 Skills(命名規範、斷言指引、測試基礎),條件載入 0~3 個(視測試中使用的技術而定)。
Frontmatter 定義:
---
name: dotnet-testing-reviewer
description: '審查 .NET 單元測試的品質,載入品質相關 Skills 驗證命名、斷言、覆蓋率等最佳實踐'
user-invokable: false
tools: ['read', 'search', 'search/listDirectory', 'execute/getTerminalOutput',
'execute/runInTerminal', 'read/terminalLastCommand', 'read/terminalSelection']
model: ['Claude Sonnet 4.6 (copilot)', 'Claude Opus 4.6 (copilot)']
---
注意 Reviewer 的 tools 中沒有 edit — 這是刻意的設計。Reviewer 只負責審查和產出品質報告,不會直接修改測試程式碼。如果發現問題,它會在報告中提出具體的修正建議,讓使用者或後續的迭代來處理。
Reviewer 對測試程式碼進行六個維度的品質審查:
| 審查維度 | 來源 Skill | 檢查重點 |
|---|---|---|
| 命名品質 | test-naming-conventions | 中文三段式格式、情境與預期描述的具體性 |
| 斷言品質 | awesome-assertions-guide | .Should() 語法、精確度、物件級別比較 |
| 測試結構 | unit-test-fundamentals | AAA Pattern、FIRST 原則、一測試一概念 |
| 程式碼品質 | (內建規則) | 未使用的 using、不必要的命名空間引入 |
| Mock 品質 | nsubstitute-mocking | 是否只 Mock 介面、Received() 驗證是否合理 |
| 覆蓋完整性 | (內建規則) | 正常路徑、邊界條件、例外情境是否都有覆蓋 |
最終輸出結構化的品質報告,包含整體評分(A+ ~ D)、具體的 issues 清單(每個都有 severity、category、suggestion)、遺漏的測試案例建議、以及做得好的 positives。
每個 Subagent 的實戰展示,會在下一篇文章中用一個具體案例走過完整的四階段流程。
Skills 分工策略 — 每個 Subagent 載入什麼
整個架構的 Skills 分工是經過精心設計的。不是每個 Agent 都需要載入所有 Skills,而是根據職責分配:
Skills 分工策略

| Agent | Skills 載入策略 | 說明 |
|---|---|---|
| Orchestrator | 不載入任何 Skills | 只負責指揮和傳遞 |
| Analyzer | 不載入任何 Skills | 靠自身能力分析程式碼 |
| Writer | 技術型 Skills(動態,3~5 個) | 如:nsubstitute-mocking、autofixture-basics、datetime-testing-timeprovider |
| Executor | 執行型 Skill(固定,1 個) | dotnet-test |
| Reviewer | 品質型 Skills(固定 3 + 條件 0~3 個) | 固定:naming、assertions、fundamentals;條件:mocking、comparison、coverage |
Context Window 使用分析
這個分工策略帶來的 Context Window 效益:
| Agent | Skills 載入量 | 預估 Context 使用 |
|---|---|---|
| Orchestrator | 0 個 | 約 12K tokens(指令 + 對話) |
| Analyzer | 0 個 | 約 8K tokens(指令 + 分析結果) |
| Writer | 3–5 個 | 約 15K–25K tokens(Skills + 程式碼) |
| Executor | 1 個 | 約 5K tokens(Skill + 錯誤修正) |
| Reviewer | 3–6 個 | 約 12K–20K tokens(Skills + 審查報告) |
對比單一 Agent 載入 5 個以上 Skills 的約 39K tokens,每個 Subagent 都在合理的 Context 範圍內運作。
為什麼不讓 Orchestrator 和 Analyzer 載入 Skills?
這個問題我也思考過。直覺上覺得「多讀一些 Skill 不是更好嗎?」,但實測發現答案是否定的:
- Orchestrator:它的職責是指揮,載入 Skills 只會浪費 Context Window。我試過讓 Orchestrator 載入 Skills,結果它開始「越權」自己寫測試,完全跳過了 Writer
- Analyzer:它需要的是「理解程式碼結構」的能力,這是 LLM 本身就具備的。它需要知道的是「偵測到 TimeProvider 依賴就加入
datetime-testing-timeprovider到 requiredTechniques」,而不是需要讀取整份TimeProvider SKILL.md
多目標平行執行
當使用者要求為多個類別建立測試時,Orchestrator 支援平行執行模式:
- Analyzer 階段:可平行分析多個目標類別
- Writer 階段:可平行為多個目標撰寫測試
- Executor 階段:必須循序執行(避免 Build 衝突)
- Reviewer 階段:可平行審查多個測試檔案
階段間的資料傳遞
Agent Orchestration 能否正確運作,很大程度取決於 Orchestrator 傳給每個 Subagent 的 prompt 是否包含足夠的資訊。這裡的設計原則是:每個 Subagent 只收到它需要的資料,不多也不少。
Orchestrator → Analyzer
Orchestrator 傳給 Analyzer 的 prompt 相對簡單:
- 被測試目標的檔案路徑或類別名稱
- 測試專案的路徑(讓 Analyzer 能掃描既有基礎設施)
- 使用者的特殊需求(如果有的話)
Analyzer → Orchestrator → Writer
這是最關鍵的傳遞環節。Analyzer 回傳結構化的 JSON 分析報告,Orchestrator 會將完整的分析報告轉傳給 Writer,同時附上額外的指示。Writer 收到的 prompt 必須包含:
- 完整的分析報告 JSON — 包含
requiredTechniques、suggestedTestScenarios、existingTestInfrastructure等 - 被測試目標與依賴介面的檔案路徑 — 讓 Writer 能用
read工具讀取原始碼 - 測試檔案的預期輸出路徑 — 依照現有專案結構推導
- 沿用既有基礎設施的提醒 — 如果 Analyzer 發現測試專案有
AutoDataWithCustomization等基礎設施,明確告知 Writer 必須沿用
這裡有一個經驗教訓:第一版設計中,我只傳了 requiredTechniques 清單給 Writer,沒有傳完整的分析報告。結果 Writer 不知道被測類別有哪些方法、有幾個依賴,只能自己重新分析一遍 — 浪費了 Context Window,也可能與 Analyzer 的分析結果不一致。
Writer → Orchestrator → Executor
Writer 完成後回傳測試程式碼的檔案路徑和新增的 NuGet 套件資訊。Orchestrator 傳給 Executor 的 prompt 包含:
- 測試專案路徑
- 被測試目標的專案路徑(供修正錯誤時參考)
- Writer 修改的 NuGet 套件資訊
Executor → Orchestrator → Reviewer
Executor 回傳 dotnet test 的執行結果。Orchestrator 傳給 Reviewer 的 prompt 包含:
- 測試檔案路徑(Executor 已在原檔案上完成修正,Reviewer 直接讀取最終版本)
- 被測試目標的檔案路徑(供比對覆蓋率)
- Analyzer 的分析報告(讓 Reviewer 知道使用了哪些技術、是否有特殊依賴)
- Executor 的執行結果(是否全數通過)
這裡值得注意的是:Reviewer 也需要收到 Analyzer 的分析報告。因為 Reviewer 要根據 dependencies 判斷是否需要額外載入 nsubstitute-mocking Skill 來審查 Mock 品質,也要根據 complexModelAnalysis 判斷是否應該使用 BeEquivalentTo() 做物件比對。
錯誤處理策略
Agent Orchestration 不是每次都能順利跑完四個階段。Orchestrator 的 .agent.md 定義了每個階段的錯誤處理策略:
Analyzer 失敗
最常見的原因是找不到被測試目標。處理方式:
- 向使用者確認檔案路徑是否正確
- Orchestrator 自己用
read和search工具嘗試找到目標檔案 - 重新委派 Analyzer
Executor 修正後仍有失敗
如果 Executor 經過 3 輪修正後仍有測試失敗:
- 將失敗訊息和 Executor 的分析一併傳給 Reviewer
- 在最終結果中明確標示哪些測試仍然失敗
- 提供修正方向建議(讓使用者決定是否手動修正或重新執行)
Reviewer 發現重大品質問題
如果 Reviewer 的 overallScore 為 C 或以下:
- 在結果中凸顯主要問題
- 建議使用者手動修正,或再次執行 Orchestrator 並附上改善方向
這些錯誤處理策略的共同原則是:不隱藏問題,讓使用者做最終決策。 Agent Orchestration 的定位是助手而不是黑箱。
小結
回頭看這個架構,核心想法很單純:讓每個 Agent 專注做一件事,在有限的 Context Window 中發揮最大效能。
5 個 Agent 定義檔共同構成了一個從分析、撰寫、執行到審查的完整流水線。HARD STOP 規則是被踩坑踩出來的、自我檢查清單是對抗 AI 越權的有效手段、Skills 分工策略是反覆調整 Context Window 使用量後定案的、資料傳遞協定是踩過「資訊不足」的坑後才完善的。
這篇聚焦在「為什麼這樣設計」— Orchestrator 的職責限制與進度顯示、4 個 Subagent 的角色定位與工具配置、Skills 的分工原則、階段間的資料傳遞協定、以及錯誤處理策略。下一篇會深入每個 Subagent 的運作機制,並用一個具體的案例走過完整的四階段流程。
參考資源
- dotnet-testing-agent-orchestration:https://github.com/kevintsengtw/dotnet-testing-agent-orchestration
- dotnet-testing-agent-skills:https://github.com/kevintsengtw/dotnet-testing-agent-skills
- VS Code Custom Agents:https://code.visualstudio.com/docs/copilot/customization/custom-agents
- VS Code Subagents:https://code.visualstudio.com/docs/copilot/customization/custom-agents#_subagents
純粹是在寫興趣的,用寫程式、寫文章來抒解工作壓力