系列:從鐵人賽到 Agent Orchestration — AI 自動建立 .NET 測試的完整方案(5)
前言
上一篇拆解了 dotnet-testing-orchestrator 的架構設計 — 1 + 4 的分工策略、HARD STOP 規則、Context Window 的使用效益。但架構圖終究只是設計,真正重要的是:每個 Subagent 實際上做了什麼?它在實際使用中表現如何?
說實話,在第一次按下 Enter 讓 Orchestrator 跑起來的時候,我是很忐忑的。畢竟 4 個 Subagent 要在各自獨立的 Context Window 中接力完成工作,任何一個環節出錯都會影響最終結果。
這篇文章會深入每個 Subagent 的運作機制,並用一個具體的案例帶你走過四階段流程的完整過程 — 從一句話到可執行的完整測試。
Demo 情境設定
被測類別:OrderProcessingService
選擇 OrderProcessingService 作為展示案例,因為它涵蓋了多種測試技術需求:
public class OrderProcessingService
{
private readonly IOrderRepository _orderRepository;
private readonly IPaymentGateway _paymentGateway;
private readonly IEmailService _emailService;
private readonly TimeProvider _timeProvider;
public OrderProcessingService(
IOrderRepository orderRepository,
IPaymentGateway paymentGateway,
IEmailService emailService,
TimeProvider timeProvider)
{
_orderRepository = orderRepository;
_paymentGateway = paymentGateway;
_emailService = emailService;
_timeProvider = timeProvider;
}
// 多個業務方法...
}這個類別的特徵:
- 4 個建構子依賴(3 個介面 + 1 個 TimeProvider)
- 需要 NSubstitute Mock 3 個介面
- 需要 FakeTimeProvider 處理時間相關邏輯
- 有多個分支路徑(成功、失敗、邊界條件)
使用者操作
在 VS Code 中:
- 開啟 Chat(
Ctrl + Shift + I) - 切換到 Agent Mode
- 在 Agent 選擇器中選擇
dotnet-testing-orchestrator - 輸入:「為 OrderProcessingService 建立完整的單元測試」
就這樣,一句話。接下來的一切都由 Orchestrator 自動完成。
Phase 1:Analyzer 分析
Orchestrator 收到使用者需求後,第一步是委派 Analyzer 進行程式碼分析。
Analyzer 的運作機制
Analyzer 採用 6 步驟分析流程:
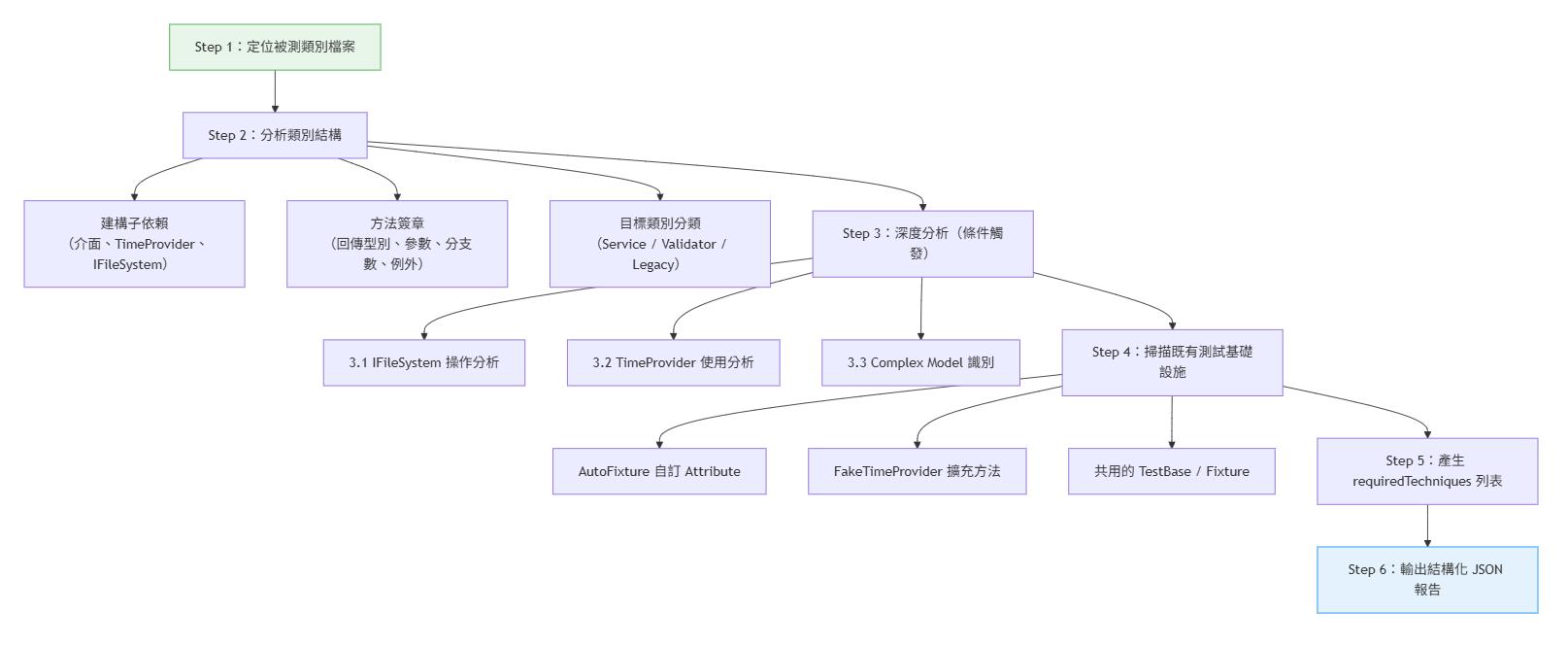
三種目標類型
Analyzer 會將被測類別分為三種類型,這個分類決定了後續 Writer 使用的寫作策略:
| 目標類型 | 判斷條件 | Writer 策略 |
|---|---|---|
| Service | 一般服務類別,有建構子注入依賴 | 標準 Mock + AAA Pattern |
| Validator | 繼承 AbstractValidator<T>(FluentValidation) | TestValidate() 方法、對稱驗證覆蓋 |
| Legacy | 缺少介面注入、static 方法、直接 new 外部依賴 | Characterization Tests、行為記錄 |
requiredTechniques — 連結 Analyzer 與 Writer 的關鍵
Analyzer 最重要的輸出之一是 requiredTechniques 列表,這個列表會告訴 Writer 需要載入哪些 Skills。
Analyzer 內部有一張完整的技術對照表,將 19 種技術 ID 對應到具體的偵測條件:
| 偵測條件 | requiredTechniques |
|---|---|
| 建構子有介面依賴 | nsubstitute-mocking |
| 方法有複雜參數 | autofixture-basics |
建構子注入 TimeProvider | datetime-testing-timeprovider |
建構子注入 IFileSystem | filesystem-testing-abstractions |
繼承 AbstractValidator<T> | fluentvalidation-testing |
| 專案有 AutoFixture 自訂 Attribute | autofixture-customization |
| 方法回傳複雜物件 | complex-object-comparison |
輸出格式
Analyzer 的完整輸出是一份結構化 JSON 報告,包含:
targetType:service / validator / legacyrequiredTechniques:技術需求列表suggestedTestScenarios:建議的測試情境(中文三段式命名)existingTestInfrastructure:既有測試基礎設施complexModelAnalysis:複雜物件分析結果fileSystemOperations:檔案系統操作分析timeProviderUsage:TimeProvider 使用分析validatorInfo:Validator 相關資訊(若為 Validator 類型)legacyInfo:Legacy 相關資訊(若為 Legacy 類型)
Demo:OrderProcessingService 的分析結果
以 OrderProcessingService 為例,Analyzer 自動執行以下分析:
- 定位
OrderProcessingService.cs檔案 - 分析建構子依賴:
IOrderRepository→ 需要 Mock(介面)IPaymentGateway→ 需要 Mock(介面)IEmailService→ 需要 Mock(介面)TimeProvider→ 需要 FakeTimeProvider(特殊依賴)
- 分析每個公開方法的簽章、回傳型別、參數、分支數
- 判斷目標類型 → Service(非 Validator、非 Legacy)
- 掃描既有測試基礎設施(AutoFixture Attribute、共用 Fixture 等)
產出的分析報告:
{
"targetType": "service",
"requiredTechniques": [
"nsubstitute-mocking",
"autofixture-basics",
"datetime-testing-timeprovider",
"awesome-assertions-guide"
],
"existingTestInfrastructure": {
"hasAutoFixtureAttributes": true,
"hasFakeTimeProviderExtensions": false,
"hasSharedFixtures": false
},
"suggestedTestScenarios": [
"ProcessOrder_訂單金額為正值且庫存充足_應成功處理訂單並發送確認信",
"ProcessOrder_付款閘道回傳失敗_應拋出PaymentFailedException",
"ProcessOrder_訂單已過期_應回傳訂單過期錯誤",
"CancelOrder_訂單存在且未出貨_應成功取消並退款",
"CancelOrder_訂單不存在_應拋出OrderNotFoundException"
]
}關鍵觀察:
requiredTechniques有 4 項 — 這決定了 Writer 會載入 4 個 SKILL.md- 偵測到
TimeProvider— 自動標記需要datetime-testing-timeprovider技術 - 掃描到既有 AutoFixture Attribute — Writer 必須重用而非重新建立
Phase 2:Writer 撰寫
Orchestrator 將 Analyzer 的分析報告傳給 Writer,Writer 開始撰寫測試。
Writer 的運作機制
Skills 動態載入策略
Writer 的第一步是根據 requiredTechniques 列表,使用 read 工具明確載入對應的 SKILL.md 檔案。這裡的關鍵是明確使用 read 工具讀取,而不是等待 AI 自動觸發 — 這正是解決第二篇文章提到的觸發問題的核心設計。
我在 Writer 的 .agent.md 裡直接寫了一張對照表,告訴它「看到這個 technique,就去讀這個路徑的 SKILL.md」。不靠 AI 的判斷力,靠明確的指令。這招比改 Description 有效太多了。
Writer 內部有一張完整的技術對應表,把每個 requiredTechniques ID 對應到具體的 SKILL.md 路徑。以下列出幾個常見的對應:
| requiredTechniques | SKILL.md 路徑 |
|---|---|
nsubstitute-mocking | .github/skills/dotnet-testing-nsubstitute-mocking/SKILL.md |
autofixture-basics | .github/skills/dotnet-testing-autofixture-basics/SKILL.md |
datetime-testing-timeprovider | .github/skills/dotnet-testing-datetime-testing-timeprovider/SKILL.md |
filesystem-testing-abstractions | .github/skills/dotnet-testing-filesystem-testing-abstractions/SKILL.md |
fluentvalidation-testing | .github/skills/dotnet-testing-fluentvalidation-testing/SKILL.md |
complex-object-comparison | .github/skills/dotnet-testing-complex-object-comparison/SKILL.md |
| ... | ...(共 19 個對應,完整表格見 Writer 的 .agent.md) |
一般情況下,Writer 會載入 3~5 個 SKILL.md,視被測類別的特徵而定。
12 條撰寫規範
Writer 遵循 12 條明確的撰寫規範,這些規範確保產出的測試程式碼品質一致:
- 使用 AAA Pattern(Arrange / Act / Assert)並加上對應註解
- 中文三段式命名(方法_情境_預期結果)
- 使用 AwesomeAssertions(
.Should())而非 xUnitAssert.* - AutoFixture-first 資料建構策略
- 複雜物件比對使用
BeEquivalentTo() - Validator 測試使用
TestValidate()方法 - Legacy Code 使用 Characterization Tests
- 邊界值需加註計算過程
- 掃描專案既有測試模式並重用
- 不引入未使用的
using指令 - Mock 設定要明確(避免
ReturnsForAnyArgs) - Legacy Code 測試命名需保持一致性
工作流程
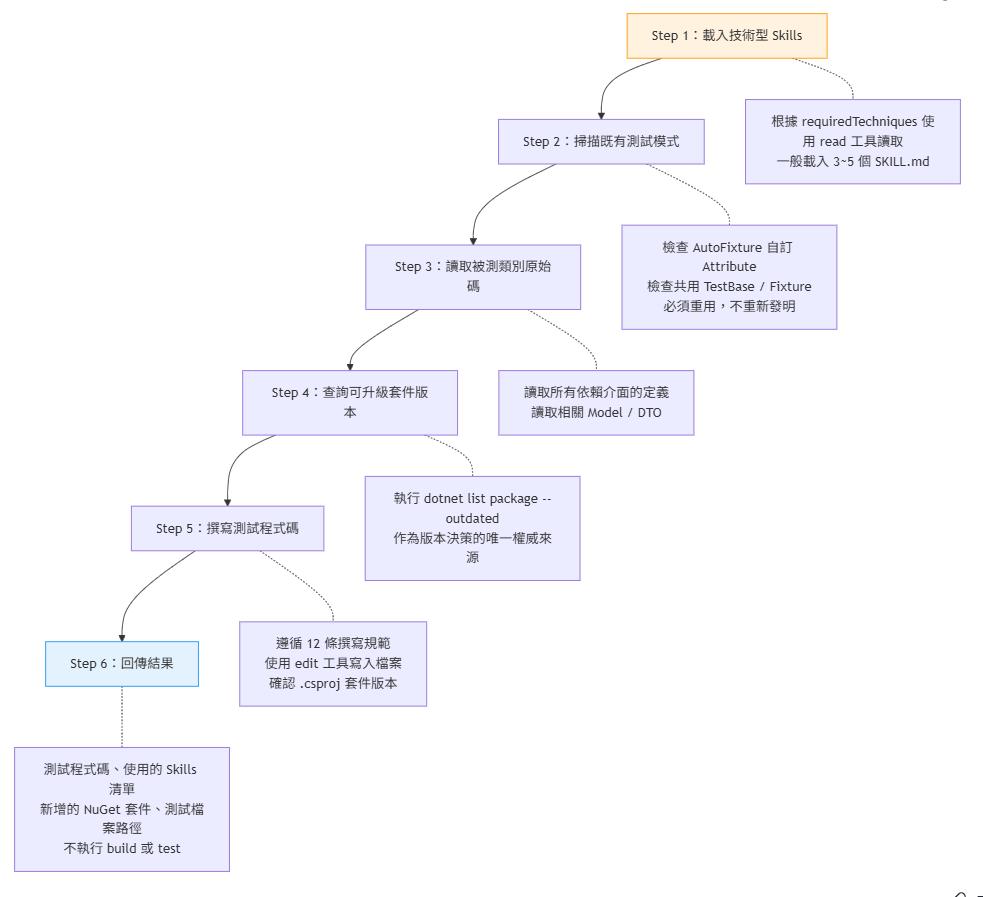
Writer 不會 build 或執行測試 — 這是 Executor 的職責。這個分離確保每個 Subagent 專注於自己的工作。
Demo:OrderProcessingService 的測試撰寫
Writer 根據 requiredTechniques 使用 read 工具載入 4 個 SKILL.md:
.github/skills/dotnet-testing-nsubstitute-mocking/SKILL.md— NSubstitute Mock 設定.github/skills/dotnet-testing-autofixture-basics/SKILL.md— AutoFixture 測試資料產生.github/skills/dotnet-testing-datetime-testing-timeprovider/SKILL.md— TimeProvider 時間測試.github/skills/dotnet-testing-awesome-assertions-guide/SKILL.md— AwesomeAssertions 斷言
讀取完 Skills 之後:
- 掃描專案中既有的測試模式(發現有 AutoFixture 自訂 Attribute,決定重用)
- 讀取
OrderProcessingService.cs和所有依賴介面的原始碼 - 依照 12 條撰寫規範產出測試程式碼
Writer 產出 25 個測試方法,涵蓋:
- 正常路徑(成功處理訂單、成功取消訂單)
- 例外路徑(付款失敗、訂單不存在、訂單過期)
- 邊界條件(金額為零、庫存剛好足夠、時間邊界)
- TimeProvider 相關測試(使用 FakeTimeProvider 控制時間)
每個測試都遵循中文三段式命名、AAA Pattern、AwesomeAssertions 斷言。
Phase 3:Executor 執行
Writer 完成後,Orchestrator 委派 Executor 執行測試。
Executor 的運作機制
Build-first 工作流
Executor 載入的 dotnet-test Skill 並非本專案自製,而是引用社群中 Oleksii Nikiforov 發佈的 dotnet-test Skill。這個 Skill 定義了 dotnet build → dotnet test 的標準執行流程,包含 -p:WarningLevel=0 降噪、--no-build 避免重複編譯等最佳實踐。它不計入本專案的 29 個 Skills 數量中,但是 Executor 運作時的重要依賴。
它定義了 Build-first 策略,先確認編譯通過再執行測試:
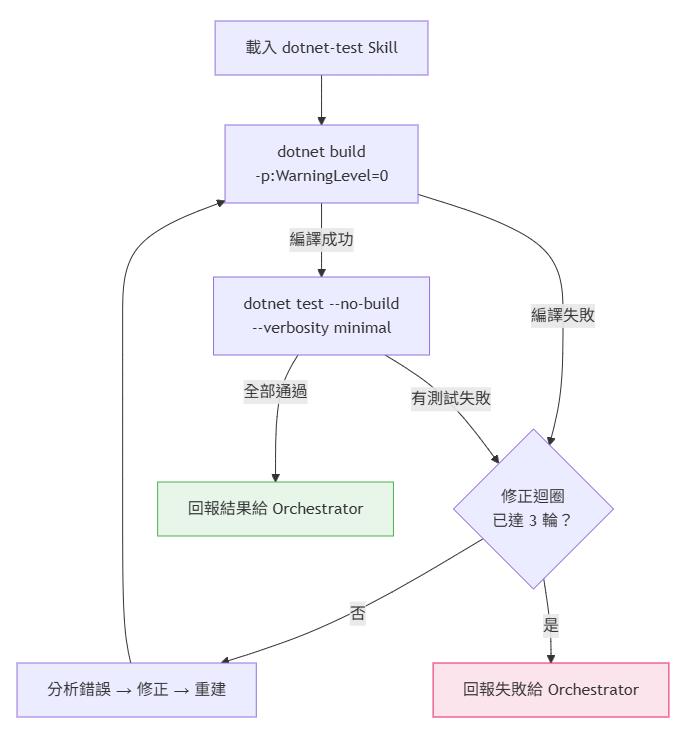
常見錯誤修正模式
Executor 的 .agent.md 中記錄了常見的錯誤修正模式,讓 AI 能快速定位問題:
編譯錯誤:
| 錯誤碼 | 常見原因 | 修正方式 |
|---|---|---|
| CS0246 | 缺少 NuGet 套件或 using | 加入缺少的套件引用 |
| CS1061 | 方法名稱拼錯或不存在 | 對照原始碼修正方法名 |
| CS0029 | 型別轉換錯誤 | 修正回傳型別的處理方式 |
| CS7036 | 建構子參數數量不符 | 補齊缺少的 Mock 依賴 |
測試失敗:
| 失敗類型 | 常見原因 | 修正方式 |
|---|---|---|
| 斷言不符 | 預期值與實際值不同 | 檢查業務邏輯,修正預期值 |
| NSubstitute 例外 | Mock 了具體類別而非介面 | 改為 Mock 介面 |
| 時區問題 | 未使用 FakeTimeProvider | 改用 TimeProvider 注入 |
防幻覺機制
這條規則是我在早期測試時加上的。有一次 AI 回報「25/25 測試通過」,但我實際去跑 dotnet test 卻發現只有 20 個測試,而且有 3 個失敗。AI 把預期的結果當成了實際結果回報 — 這就是幻覺。
所以 Executor 現在有一條明確的規則:所有回報的測試名稱和結果必須來自實際的 dotnet test 輸出,不允許憑空編造。
Demo:OrderProcessingService 的測試執行
Step 1:載入 dotnet-test Skill ✓
Step 2:dotnet build -p:WarningLevel=0 /clp:ErrorsOnly
→ 編譯成功 ✓
Step 3:dotnet test --no-build --verbosity minimal
→ 25/25 通過 ✓(0 輪修正)
回報結果給 Orchestrator
在這個案例中,Writer 產出的測試一次通過,不需要任何修正。說實話,我看到 25/25 全過的時候是有點驚訝的 — 因為在沒有 Orchestrator 的時代,AI 寫出的測試常常有編譯錯誤或型別不匹配。這也反映了 Skills 指導的效果 — 因為 Writer 依照 SKILL.md 的最佳實踐撰寫,編譯和執行錯誤的機率大幅降低。
Phase 4:Reviewer 審查
最後,Orchestrator 委派 Reviewer 進行品質審查。
Reviewer 的運作機制
Skills 載入策略
與 Writer 的動態載入不同,Reviewer 採用固定 + 條件的載入策略:
固定載入(每次都載入):
| Skill | 用途 |
|---|---|
test-naming-conventions | 審查命名規範 |
awesome-assertions-guide | 審查斷言品質 |
unit-test-fundamentals | 審查測試結構 |
條件載入(視情況載入):
| Skill | 載入條件 |
|---|---|
nsubstitute-mocking | 測試中使用了 NSubstitute |
complex-object-comparison | 測試中有複雜物件比對 |
code-coverage-analysis | 需要評估覆蓋率完整性 |
六大審查維度
Reviewer 對測試程式碼進行六個面向的品質審查:
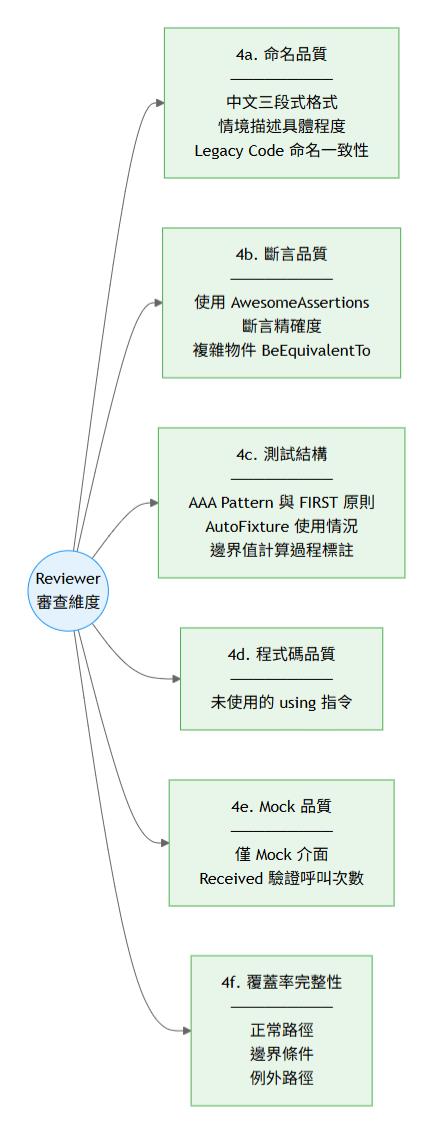
品質評分
Reviewer 輸出結構化 JSON 報告,包含整體評分:
| 評級 | 標準 |
|---|---|
| A+ | 所有維度都優秀,無 error 或 warning |
| A | 整體優秀,少量 warning |
| A- | 良好,有改善空間 |
| B+ | 合格,有明確問題需修正 |
| B | 合格但品質不足 |
| C ~ D | 品質不足,需要大幅改善 |
報告中每個問題都標記嚴重等級(error / warning / suggestion),並附帶具體的修正建議和正面亮點。
Demo:OrderProcessingService 的品質審查
Reviewer 載入的 Skills:
- 固定載入:
test-naming-conventions、awesome-assertions-guide、unit-test-fundamentals - 條件載入:
nsubstitute-mocking(因為測試使用了 NSubstitute)
審查結果(節錄):
| 嚴重等級 | 審查維度 | 發現問題 | 修正建議 |
|---|---|---|---|
| ⚠️ warning | 命名品質 | Test_Process_Success 未使用中文三段式命名 | 改為 處理訂單_正常訂單_應回傳成功結果 |
| ⚠️ warning | 斷言品質 | 使用了 Assert.Equal 而非 AwesomeAssertions | 改為 result.Should().Be(expected) |
| 💡 suggestion | 測試結構 | Arrange 區塊過長,可讀性降低 | 將共用設定提取到 TestBase 或使用 AutoFixture.Customize |
| ✅ pass | Mock 品質 | 僅 Mock 介面,Received() 驗證正確 | — |
| ✅ pass | 覆蓋率 | 正常、邊界、例外路徑都有覆蓋 | — |
整體評分:B+(有明確問題需修正)
完整流程時序
從使用者輸入一句話到收到完整測試和品質報告的完整流程:
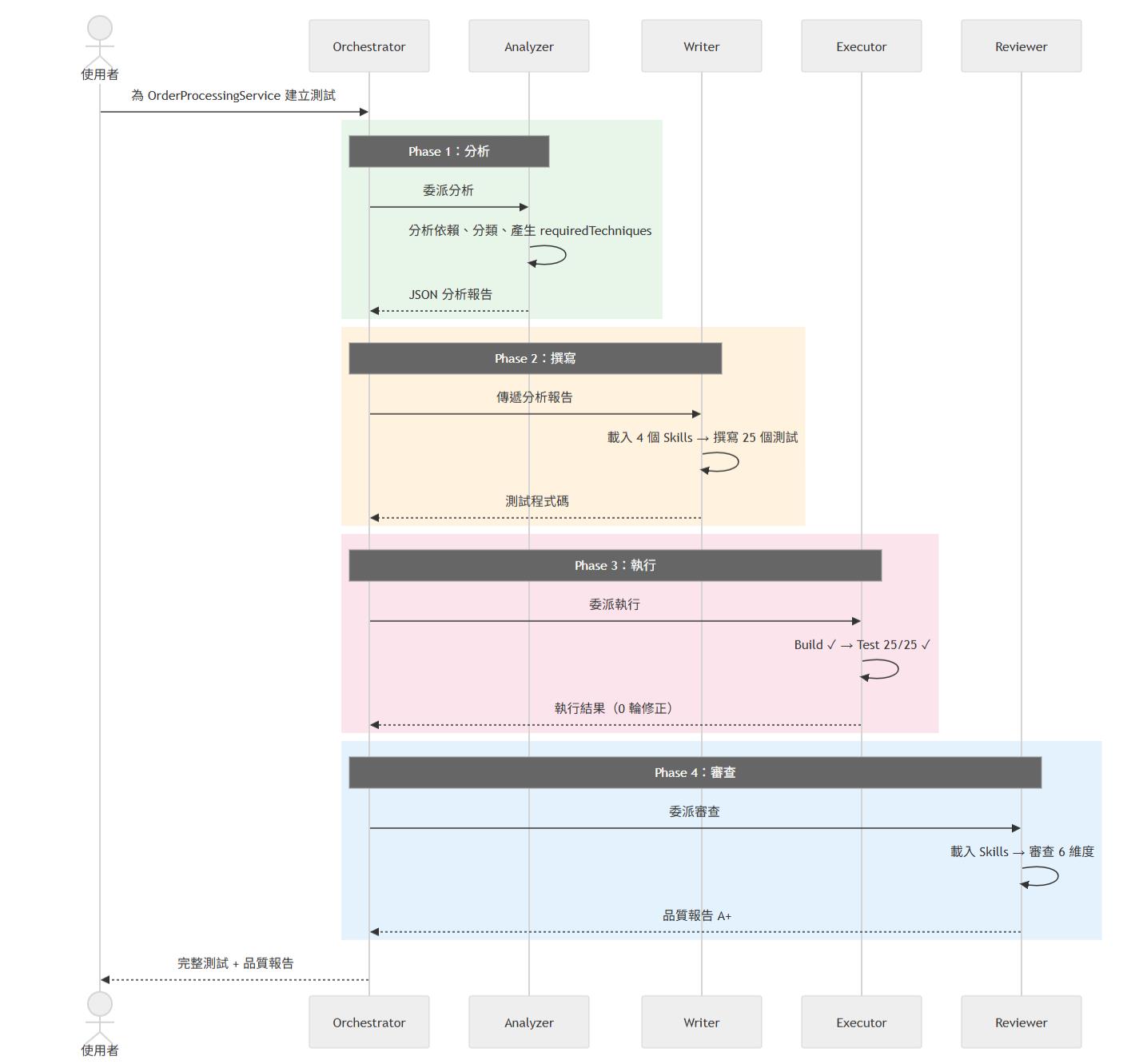
整體評分:B+(有明確問題需修正)
使用者體驗對比
最後做一個對比,從使用者的角度來看三種方式的差異:
| 方法 | 使用者需做的事 |
|---|---|
| 純 Skills | 手動分析需要哪些技術、祈禱 AI 載入正確 Skill |
| Custom Prompts | 從 16 個指令中選擇正確的 |
| Orchestrator | 輸入一句話 |
Orchestrator 的核心價值就在這裡:使用者不需要理解 29 個 Skills 的分類、不需要從 16 個 Prompts 中挑選正確的指令,只需要告訴 AI 「我要為哪個類別建立測試」。
剩下的一切 — 分析程式碼特徵、選擇正確的技術、載入對應的 Skills、撰寫測試、執行驗證、品質審查 — 全部由 Orchestrator 自動完成。
驗證 dotnet-testing-orchestrator
你可以透過我所準備的操作指南以及 Practice 專案(.NET8.0, .NET9.0, .NET10.0)在 VS Code 裡使用 Github Copilot 操做驗證
實際操作執行記錄
指定單一類別撰寫單元測試
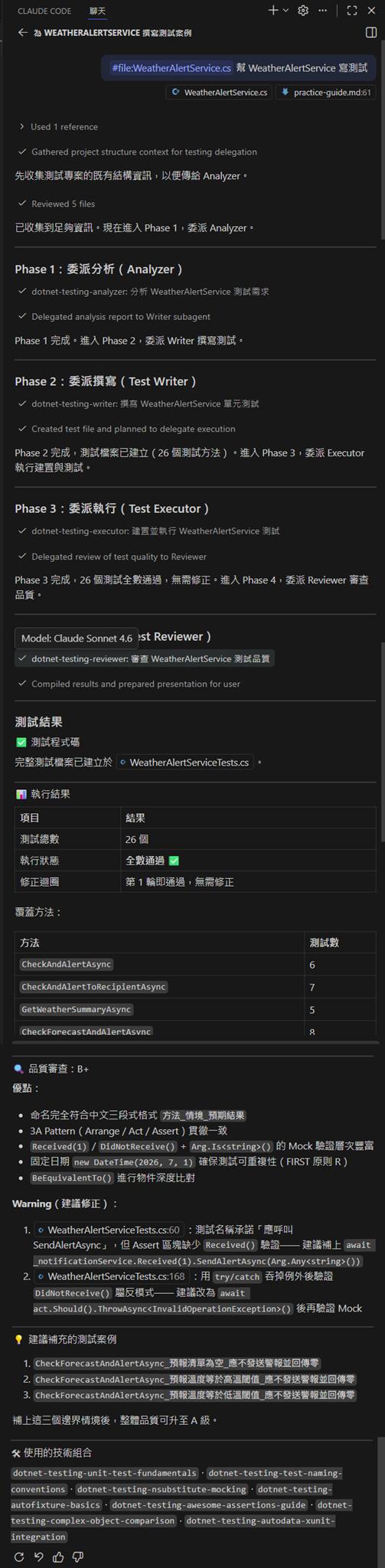
指定多個類別撰寫單元測試
在 Phase 1 (Analyzer)、Phase 2 (Weiter)、Phase 3 (Reviewer) 會平行委派同時執行

P.S. 小提示
一回合的整個四階段都執行完成後,Reviewer 如果所提供的「品質檢查」不是 A 或 A+ 或者有提供建議,可以在 Agent 仍然是 dotnet-testing-orchestrator 的狀況下,直接輸入指令「依據 Reivewer 所提供的建議內容進行修改」,Agent 就會對之前第一回合依據 Reviewer 的修改建議進行修改。
小結
這篇文章從兩個層面展示了 Orchestrator 的四階段流程 — 先介紹每個 Subagent 的運作機制(Analyzer 的 6 步驟分析、Writer 的 Skills 動態載入與 12 條規範、Executor 的 Build-first 策略與防幻覺機制、Reviewer 的六大審查維度),再用 OrderProcessingService 的實際案例走過完整流程。
對我來說最重要的收穫是:當品質不如預期時,解法是改進 Agent 定義,而不是推翻架構重來。 這讓整個系統的維護成本非常可控。
但單元測試只是故事的一半。實際專案中,整合測試面對的挑戰完全不同 — Docker 容器、DbContext 衝突、API 端點分析。下一篇會介紹 Integration Test Orchestrator,看看同樣的 1 + 4 架構如何適應整合測試的需求。
參考資源
- dotnet-testing-agent-orchestration:https://github.com/kevintsengtw/dotnet-testing-agent-orchestration
- dotnet-testing-agent-skills:https://github.com/kevintsengtw/dotnet-testing-agent-skills
- VS Code Custom Agents:https://code.visualstudio.com/docs/copilot/customization/custom-agents
- VS Code Subagents:https://code.visualstudio.com/docs/copilot/customization/custom-agents#_subagents
純粹是在寫興趣的,用寫程式、寫文章來抒解工作壓力