用 autoresearch 量化優化 Orchestrator 的 agent 定義 — 七回合的迭代記錄
前四篇談這四個測試 Orchestrator「怎麼用」,這一篇談它們背後的 agent 定義是怎麼被「調」出來的 — 用 autoresearch 跑「改一處 → 量分數 → 進步就留、退步就退回」的迴圈,七個回合、五十多次迭代,連失誤與退步一起記錄。
前言
前四篇把安裝、四個 Orchestrator 的架構與使用都走過一遍。但有一塊一直沒談:這些 Orchestrator 與各個 subagent 的定義檔(.claude/agents/ 與 .claude/skills/ 裡那一堆 .md),本質上就是一大包 prompt — 那它們是怎麼調到現在這個樣子的?
問題在於:agent 定義是 prompt,而 prompt 的改動好壞,肉眼幾乎看不出來。你把某條規則往前挪、把某段描述改得更精確,到底讓測試的通過率變高還是變低?LLM 對措辭的反應沒辦法事前推斷,不實際跑一輪測試,誰也說不準。一開始我是手動改、憑感覺,改完跑個幾次看看 — 但這種方式既無法累積,也很容易自我感覺良好。
後來我改用 autoresearch:把「好不好」變成一個可以機械化算出來的數字,讓 AI 自己跑「改一處 → 量分數 → 進步就保留、退步就 git 退回」的迴圈,一輪一輪逼近更好的定義。這一篇就是這段過程的記錄 — 包含七個回合在調什麼、量到的成果,以及一個改錯檔案的失誤和一堆被退回去的失敗嘗試。
兩個前提先講清楚:
- 這套優化是在四個 Orchestrator 的遷移與驗證都完成之後才做的(遷移那段是另一個故事,這裡不展開)。
- 這次實驗的完整設定與版控記錄並沒有公開,所以這篇著重在「做法與結論」,沒辦法提供一個能讓你直接重跑的 repo。
一、autoresearch 是什麼
概念源頭:Karpathy 的 autoresearch
autoresearch 這個概念來自 Andrej Karpathy 在 2026 年 3 月放出的同名專案(GitHub 上約 84.2k 星,簡介就是一句「AI agents running research on single-GPU nanochat training automatically」)。想法很單純:給 AI agent 一個小而完整的 LLM 訓練環境,讓它整夜自己做實驗 — 改一版程式、訓練固定 5 分鐘、看驗證指標(val_bpb,越低越好)有沒有進步,有就保留、沒有就 git reset 退回,如此不斷重複。人睡前啟動,早上起來就有一份實驗記錄和(順利的話)一個更好的模型。
它刻意極簡:整個 repo 只有三個關鍵檔 — prepare.py(資料準備與評分,唯讀)、train.py(模型與訓練迴圈,agent 唯一能改的檔)、program.md(人類寫給 agent 的指令)。精神是「人類編輯 program.md 決定策略、agent 改 train.py 執行戰術」。驗證是真的在單張 NVIDIA GPU 上跑 5 分鐘訓練,時間固定所以每次實驗都可比較,一小時約 12 次、一晚約 100 次。
它證明了一件事:只要把範圍限縮、把成功標準變成一個機械化的數字、把驗證自動化,AI agent 就能靠「改 → 量 → 保留或退回」的迴圈自己累積出進步。
我用的是 uditgoenka 的 autoresearch
我實際用的不是 Karpathy 那個(它綁 GPU、只優化 LLM 訓練),而是 Udit Goenka 的同名專案 uditgoenka/autoresearch(約 4.8k 星,簡介寫得很直白:「Claude Autoresearch Skill — Autonomous goal-directed iteration for Claude Code. Inspired by Karpathy's autoresearch. Modify → Verify → Keep/Discard → Repeat forever.」)。它把 Karpathy 那套「限縮範圍 + 機械化指標 + 自律迭代」的核心,泛化成一個跑在 Claude Code(也支援 Codex、OpenCode)裡的 Skill 與斜線指令集(/autoresearch、:plan、:debug、:fix… 指令數量依版本而定)。
它不需要 GPU、不綁語言:優化對象從「固定的 train.py」變成「你自己指定的任意 glob 範圍」,驗證從「固定 5 分鐘訓練」變成「你自己定義、只要會吐出一個數字的任一道 shell 指令」。啟動是用 /autoresearch:plan 精靈逐步問你 Goal / Scope / Metric / Verify / Guard,然後跑 keep/revert 迴圈。
為什麼用它:我要優化的是四個 Orchestrator 與各 subagent 的定義檔(.claude/agents/*.md;SKILL.md 依 CLAUDE.md 規定唯讀、不能動),這正好是「改 prompt → 跑測試 → 看品質分數」的迴圈。uditgoenka 版原生跑在 Claude Code 裡、用斜線指令就能啟動、驗證指令可以直接指向我自己的 benchmark.ps1(跑三個目標、算測試通過率與覆蓋率)。Karpathy 版那種綁 GPU、只改 train.py 的設計完全套不上,uditgoenka 的泛化剛好對上這個需求。
兩者的差異
| 維度 | Karpathy autoresearch | uditgoenka autoresearch(我用的) |
|---|---|---|
| 本質 | 可實際執行的 ML 訓練實驗台(Python) | 跑在 Claude Code 的 Markdown Skill / 指令集 |
| 被優化對象 | 固定一個 train.py | 任意 glob 範圍(我這裡是 .claude/agents/*.md) |
| 驗證方式 | 固定 5 分鐘 GPU 訓練,指標 val_bpb | 自訂 shell 指令(我這裡是 benchmark.ps1) |
| 硬體 / 成本 | 需 NVIDIA GPU(算力費) | 無特殊硬體,耗的是 Claude API token |
| 範圍 vs 深度 | 窄而深(只做 LLM 訓練) | 廣而淺(任何可量測領域) |
| 退回機制 | git reset(丟掉失敗紀錄) | git revert(保留失敗紀錄供學習) |
| 其他機制 | 一個迴圈、一個指令 | 多指令、guard 安全網、卡關自動升級、雜訊處理 |
| 共同核心 | AGENT + 限縮範圍 + 純量指標 + 快速驗證 = 自律改善 | 同左(明白標示衍生自 Karpathy) |
要說明的是,uditgoenka 版相對小眾 — 星數(約 4.8k)遠少於 Karpathy 原版(約 84.2k),網路上也有零星質疑它「過度包裝」的聲音。但那並非主流定論;更重要的是,就我這個「優化 agent 定義」的需求而言,它確實把事情解決了。它真正的代價不在風評,而在 token — 這點留到最後一節講。
二、怎麼量「好不好」:benchmark 與 metric
自律迴圈要能跑,前提是「好不好」必須是一個機械化、可重複算出來的數字。這一節就是在講這個數字怎麼來的。
先看整個優化迴圈長什麼樣 — 這一節要講的 benchmark 與 metric,對應的就是圖裡「執行 benchmark.ps1、算出分數」那一步:
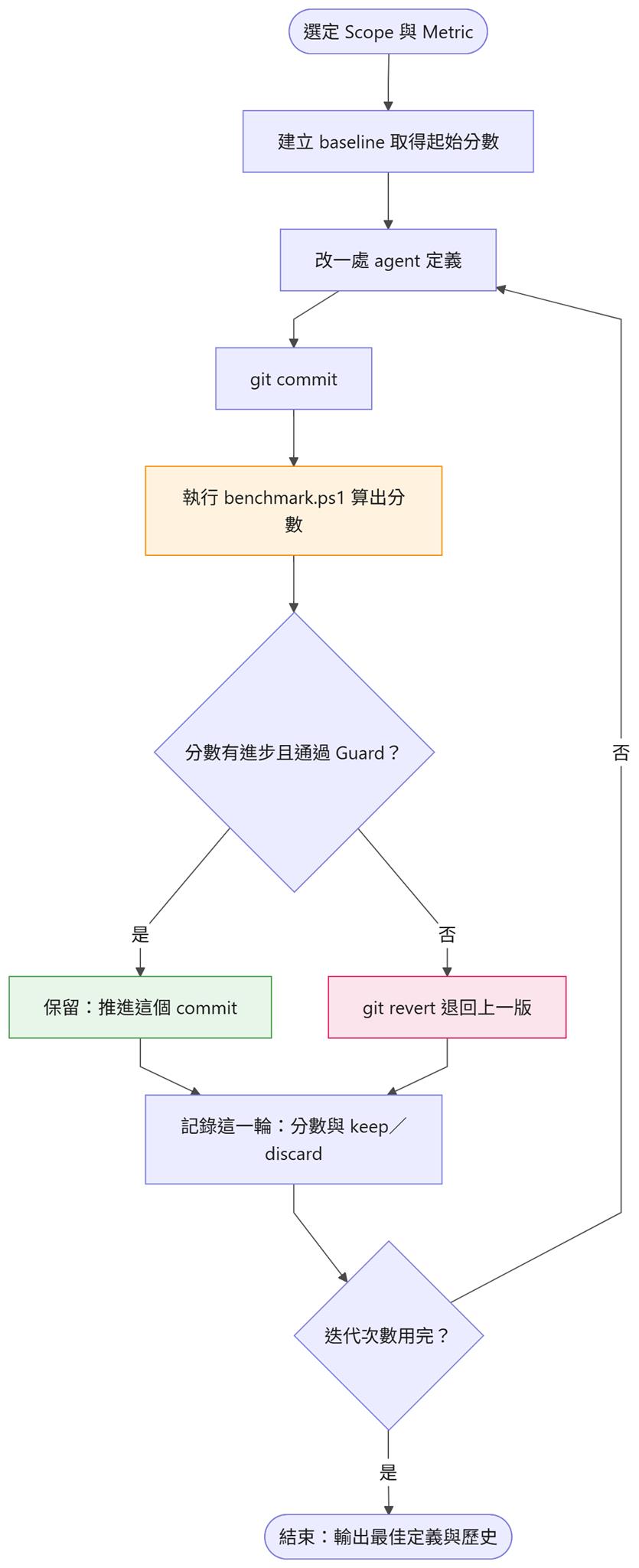
圖一:autoresearch 的優化迴圈 — 改一處、commit、跑 benchmark 算分,進步就保留、退步就 git revert,重複到迭代次數用完。
三個固定 benchmark 目標:我從練習專案裡挑了三個小型、涵蓋不同類型的類別,整段優化期間都不變動,這樣每一輪的分數才可比較。
| # | 目標 | 類型 | 行數 | 測試技術 |
|---|---|---|---|---|
| 1 | WeatherAlertService.cs | service | 154 | Mock + TimeProvider + 斷言 |
| 2 | OrderValidator.cs | validator | 100 | FluentValidation TestHelper |
| 3 | TemperatureConverter.cs | service | 97 | 純邏輯測試 |
刻意都選小型類別(≤ 154 行),是為了讓單次 orchestrator 執行在合理時間內跑完。
metric 三代進化:一開始只衡量品質,後面兩個 Phase 才把耗時、token 也納進來。
| 階段 | 指標公式 | 加進來的維度 |
|---|---|---|
| Phase 1–5 | quality_score = pass_rate×0.6 + coverage×0.25 + build×0.15 | 品質 |
| Phase 6 | quality×0.7 + time_score×0.3 | 耗時 |
| Phase 7 | quality×0.65 + token_score×0.35 | token(JSON 大小) |
Guard 底線:每個 Phase 都設了保護線,避免 LLM 為了壓時間或 token 而犧牲品質 — 主要是「quality_score 必須 ≥ 95」「build 失敗一律立刻 revert,不計入成果」。沒有這條底線,迴圈很可能會「為了某個數字好看而把測試寫爛」。
benchmark.ps1 一輪做的事:先 git restore + git clean 把測試專案還原乾淨,再對三個目標各跑一次完整 orchestrator(Analyzer → Writer → Executor → Reviewer),接著 dotnet build + dotnet test、解析結果、算出分數。把這「一次實驗執行」拆開來看:
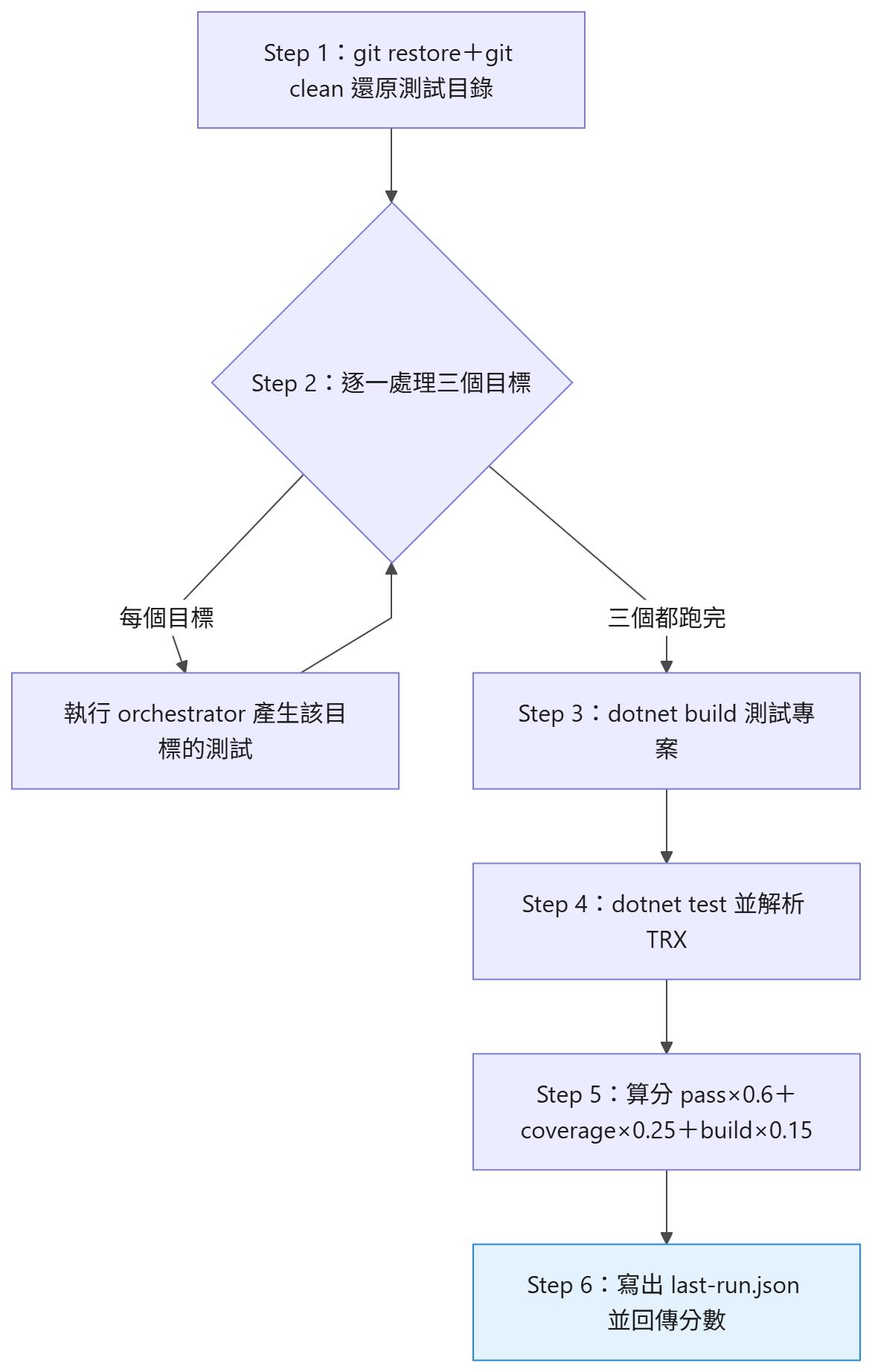
*圖二:一次 benchmark.ps1 執行的內部步驟 — 還原測試目錄、對三個目標各跑一次 orchestrator、build、test、算分,最後寫出 last-run.json 並回傳一個分數。*
其中「執行 orchestrator」那一格,內部就是固定的四個階段:

圖三:一次 orchestrator 執行內部的四個階段 — Analyzer 分析、Writer 撰寫、Executor 建置與測試、Reviewer 審查;發現問題時會回到 Writer 修改、Executor 重跑,再由 Reviewer 複審。
跑完這一輪,留下的記錄分兩層:
| 由誰寫 | 檔案 | 內容 |
|---|---|---|
benchmark.ps1 | results/last-run.json | 這一輪的總分與細項(通過率、覆蓋率、build 狀態、測試數),外加回傳給 autoresearch 的單一分數 |
| autoresearch | results/*.tsv | 每一輪一列,累積成可比較的歷史(含 keep/discard 與說明) |
| autoresearch | autoresearch.jsonl | autoresearch 自己的迭代記錄(這一輪嘗試了什麼、保留還是退回) |
(耗時與 token 階段改用 benchmark-time.ps1/benchmark-token.ps1,輸出對應的 last-run-time.json/last-run-token.json,流程相同。)
這裡有個關鍵數字要先記著:一輪驗證要跑三個完整 orchestrator,大約 30–45 分鐘。這完全不是「秒級驗證」 — 這個代價,最後一節會再回來算帳。
三、七個回合在調什麼
整段優化分成七個 Phase、合計約 52 次迭代。先用一張表帶過,再挑幾個值得講的轉折。
| Phase | 優化對象 | 指標 | 迭代 | 關鍵成果 |
|---|---|---|---|---|
| 1 | Writer 定義 | quality | 10 | 撰寫規範清晰化(Theory 展開、共用欄位) |
| 2 | Analyzer 定義 | quality | 8 | validatorInfo 完整化 + 自我驗證步驟 |
| 3 | Executor 定義 | quality | 6 | NuGet 優先診斷 + 錯誤修正優先序 |
| 4 | Orchestrator(agent) | quality | 6 | prompt 精簡(後廢棄,見下) |
| 5 | Orchestrator(SKILL) | quality | 6 | 快速啟動 + re-review 模式、精簡冗餘 |
| 6 | Writer + Executor | quality×0.7+time | 8 | combined 96.8、耗時大幅下降 |
| 7 | Analyzer JSON | quality×0.65+token | 8 | analysis.json 縮減 43% |
幾個值得單獨講的轉折:
Phase 4 的失誤 — 改了一個沒在用的檔。 那一輪優化的對象是 .claude/agents/_dotnet-testing-orchestrator.md,但這個檔名帶 _ 前綴、其實已經廢棄。原因是 Orchestrator 當時正好從 agent 模式轉成 Skill 模式,實際在跑的是 .claude/skills/.../SKILL.md。結果 6 次迭代的改進全部作用在廢棄檔上,沒有進到真正在執行的 SKILL.md。這是整段過程裡最直接的一個教訓:autoresearch 只會忠實優化你指給它的 Scope,指錯了它不會幫你發現。
Phase 5 是補救。 把 Phase 4 那些有效改進手動搬進真正的 SKILL.md,順便做精簡 — SKILL.md 從 532 行一路往下砍(移除呈現格式範例、合併冗餘的工具呼叫範例、重要原則從 11 條精簡到 4 條…),而 6 次迭代每次都維持品質 100 分。「刪掉東西、分數沒掉」本身就是一種勝利。
Phase 6(耗時)大多數迭代是退步。 這個 Phase 八次迭代裡只有兩次 keep,其餘六次都被退回 — 理由很誠實:「比 baseline 還慢」「orchestrator 直接 crash」「批次讀取造成 context 過載」。耗時這種東西受 API latency 影響很大,多數「看起來該更快」的點子實測下來反而更糟。
Phase 7(token)也有一次 discard。 想省略空陣列欄位來縮小 JSON,結果因為 LLM 的非決定性,某個目標的 JSON 大小反而暴增 78%、品質還跟著掉,只好退回上一版。
這幾個轉折其實就是 keep/revert 迴圈真正的價值:哪些改動有效,事前想不到,得靠實測;而它會老老實實把無效的退回去,不會留下你以為有用、其實沒用的東西。
四、成果:數字說話(但要標雜訊)
七個回合跑下來,量到的結果:
- 品質:三個目標 108 / 108 測試全數通過,
quality_score達到 100(pass / coverage / build 三項都滿分)。 - token(Phase 7):Analyzer 輸出的
analysis.json從 16,534 bytes 降到 9,406 bytes,縮減 43.1%,而品質維持 100。三個目標逐一都變小。靠的是移除冗餘欄位、條件式省略 null、緊湊格式 JSON、場景命名精簡等一連串小改動疊加。 - 耗時(Phase 6):
combined_score96.8,實際耗時從 baseline 壓到約 507 秒(目標線 909 秒)。
但有一點必須誠實標註:耗時與 token 都受 LLM 非決定性與 API latency 影響很大(報告裡自己就寫了 latency 約 ±40%、combined 變化 ≤ 3 視為雜訊)。所以上面這些數字看的是「量級」與「方向」,不是可以重現到小數點的跑分 — 同一個定義今天跑跟明天跑,數字本來就會跳。把它當成「明顯變好了」的證據可以,當成「精準到秒/位元組」的保證則不行。
五、調好一個,怎麼推到其他三個:手動移植
七個回合全都花在 Unit Test 工作流程上。那剩下三個(TUnit、Integration、Aspire)怎麼辦?
我的決定是:不再對它們各跑一輪 autoresearch,改成手動移植。 理由有三:
- 改進內容此時已經明確、也驗證過了,再跑迭代探索的邊際效益遠低於成本(尤其是 token)。
- 各工作流程有自己的領域邏輯要保留,不能無腦跨域套用。
- 手動逐一確認「這個改進是否已經存在」,比自動化更安全。
移植前先把改進依適用範圍分成四類:
| 類別 | 適用範圍 | 代表改進 |
|---|---|---|
| A | 全域通用(三個都適用) | 緊湊 JSON、自我驗證步驟、Orchestrator 快速啟動、Prompt 最小化、Reviewer re-review |
| B | TUnit 專用 | Validator 類型識別、FakeTimeProvider 初始化、共用欄位原則、Multi-Writer 風格一致性指令 |
| C | Integration 專用 | 各 validator 的合法值提示、Executor NuGet 優先檢查 |
| D | Aspire(改動最少) | 只套 A 類全域改進(無 Validator、架構差異最大) |
過程中有個務實的發現:讀過各工作流程現有定義後,才知道有些改進其實早就存在(例如 Integration 與 Aspire 的 Orchestrator 早有快速啟動、Reviewer 早有 re-review 模式),那就不必重複加。最後共修改九個檔案(TUnit 5 個、Integration 2 個、Aspire 2 個)。
要說明的是,這三個工作流程是「套用已在 Unit 上驗證過的改進」 — autoresearch 的量測只在 Unit 上跑出分數,我並沒有對這三個再各跑一輪 benchmark 量測。
六、小結:這套方法值不值得
先講它適合的場景:你有一個客觀、可機械化量測的 benchmark;你要調的東西「改動好壞難以肉眼判斷」(agent 定義、prompt 正是如此);而且這個產物會被長期、反覆使用,值得一次調到位。我這四個 Orchestrator 全中,所以划算。
再講代價 — 而且這是最該誠實交代的一段:它的 token 燒得非常快。 我這次一輪驗證要跑三個完整 orchestrator(30–45 分鐘),七個 Phase、五十多次迭代下來,Claude Max 的 5x 方案根本不夠用,中途得升到 20x 方案才跑得完。所以它適不適合你,很大一部分取決於你願不願意為「把 agent 定義調到最佳」付這個算力代價。
換個角度說:如果只是一次性的小優化,直接請 Claude 改通常更快、也更省 token;autoresearch 的價值,是在「你沒辦法一次想對、必須靠多次實測累積,而且這個產物值得你反覆投資」的時候才真正浮現。對我來說,把「好不好」變成一個數字、再讓迴圈替我跑,是這次最大的收穫 — 前提是你付得起那個算力代價。
寫到這裡,這個系列也告一段落 — 從架構、安裝、四個 Orchestrator 的用法,到這篇背後的調校過程。希望它能幫你在 Claude Code 上,用更少的力氣產出更高品質的 .NET 測試。
參考資源
- uditgoenka 的 autoresearch:本次實際使用的工具,一個給 Claude Code/Codex/OpenCode 的 autoresearch skill。它提供
/autoresearch:plan規劃精靈(設定 Goal/Scope/Metric/Verify/Guard)、git自動退回與 guard 護欄,把「改一處 → 跑驗證 → 留下或退回」的迴圈包成可直接套用的流程,驗證點接到你自己的 benchmark 腳本。https://github.com/uditgoenka/autoresearch - Karpathy 的 autoresearch:autoresearch 概念的源頭。示範用「改一版程式 → 固定時間訓練 → 看驗證指標 → 留下或
git reset退回」的快速迴圈,在單張 GPU 上整夜反覆優化 nanochat 訓練;本文的方法論即源自於此。https://github.com/karpathy/autoresearch - dotnet-testing-agent-orchestration(Claude Code 版):https://github.com/kevintsengtw/dotnet-testing-agent-orchestration-claude
- dotnet-testing-agent-skills(被優化的 agent/skill 定義所在):https://github.com/kevintsengtw/dotnet-testing-agent-skills
- Claude Code 官方文件:https://docs.claude.com/en/docs/claude-code/overview
純粹是在寫興趣的,用寫程式、寫文章來抒解工作壓力