之前聽課時常聽講師提及一些可以提高特定查詢效能的作法,例如計畫指南或索引檢視。今天實作一下索引檢視並記錄一下,分享給大家 !
關於Indexed View的詳細說明大家可以去SQL MVP Rico的部落格看看 ( 善用Indexed View#1簡介 ),內容相當豐富。
我這一篇只單純的LAB Indexed View帶來的查詢效能提升,首先我們先將環境建立起來。語法如下:
--建立測試資料庫
Create Database RockDB
GO
Use RockDB
GO
--建立資料表Sore,並將hy ht stuno欄位設為叢集索引
Create Table score(hy char(3),ht char(1),stuno varchar(9),scro tinyint);
GO
Create Clustered Index CIX_Score on score(hy,ht,stuno);
GO
--建立資料表Stu,並將hy ht stuno欄位設為叢集索引,注意:兩張資料表的hy ht資料型態不同
Create Table stu(hy tinyint,ht tinyint,stuno varchar(9),name varchar(10));
GO
Create Clustered Index CIX_Stu on stu(hy,ht,stuno);
GO
--Stu資料表以name欄位多建立一個index叫IX_Name
Create Index IX_Name on stu(name);
GO
--塞資料到兩張資料表中
Declare @i int;
Set @i=1
While @i<10001
Begin
insert into score values('104','1',@i,100);
insert into stu values(104,1,@i,'rock' + cast(@i as varchar));
set @i+=1;
End
完成基本資料建立後,我們用下面這一個Query來查詢姓名是rock5000這一位學生的成績資料。
set statistics io on;
select a.* from score a
inner join stu b on a.hy=b.hy and a.ht=b.ht and a.stuno=b.stuno
where b.name='rock5000';
set statistics io off
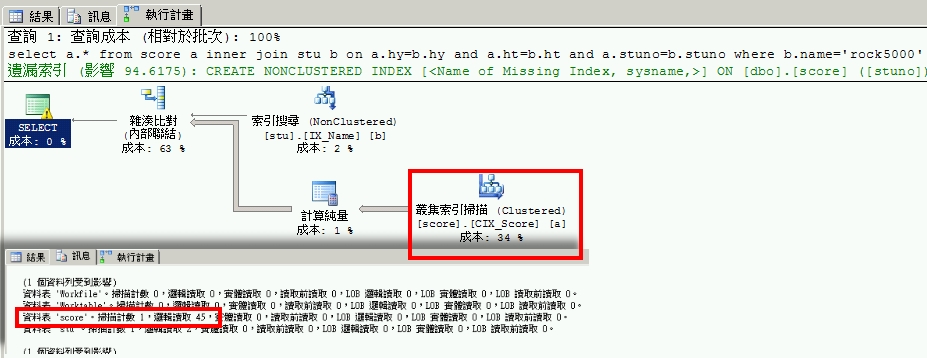
執行完上述語法後我們可以從下圖看到執行計畫及耗費的IO。因為我們有針對學生姓名建立索引IX_Name因此可以看見SQL用Seek去stu資料表搜尋rock5000的資料。而下圖中SQL卻用Scan(下圖紅色圈選處)的方式到score資料表找出rock5000學生的成績。
這是為何呢?答案是因為兩張資料表的hy及ht資料型態不同,stu的是tinyint,而score的卻是char。由於型態不一樣,即使score也是用hy ht stuno三個欄位當叢集索引,但SQL須將欄位從char轉成tinyint才能做比對,因此該叢集索引基本上要被一筆筆抓出來比,所以只能透過Scan方式了。
您看了會不會好奇為何不將兩張表的hy及ht欄位設為相同型態即可呢 ? 筆者工作環境深受這問題困擾。往往不同的SD針對欄位型態會有自己的看法,有的人覺得要用數字,有的人要設計成字元。在自己的系統都可以順順的跑,一但有需求導致兩個系統需要參照對方資料表時,這種因資料型態不同造成的問題就浮現了。因此建議設計階段要有管理DB的同仁加入,來盡量降低這一類的問題產生。
此時我們利用Indexec View看可不可以提升這一句Query的效能呢 ? 語法如下,注意Indexed View要採Schemabinding且要用兩段式命名,例 : dbo.score。
--建立View
Create View vwScores With Schemabinding
AS
Select a.[hy]
,a.[ht]
,a.[stuno]
,a.[scro]
,b.[name] From dbo.score a
inner join dbo.stu b on a.hy=b.hy and a.ht=b.ht and a.stuno=b.stuno;
GO
--對View建立唯一叢集索引
Create Unique Clustered Index CIX_vwScore On vwScores(hy,ht,stuno);
GO
--針對學生姓名再建一index IX_StuName
Create Index IX_StuName On vwScores(name) Include(hy,ht,stuno,scro);
GO
完成Indexed View建立後,我們重新執行一次剛剛的語法。結果如下圖所示,相同的語法,這一次SQL直接去搜尋vwScores檢視中的IX_Stuname索引(紅色圈選處)。耗費的IO數也只有2。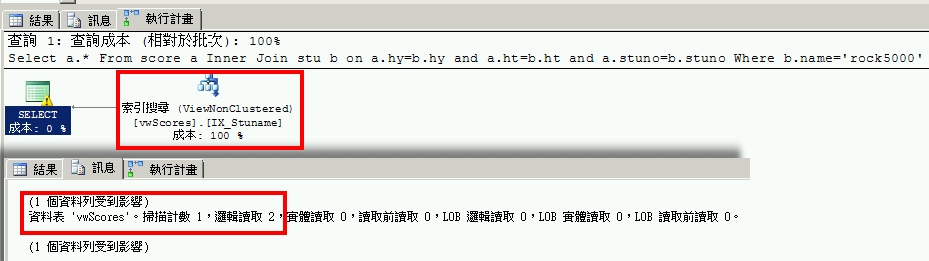
注意 ! 我們建立Indexed View時是採SchemaBinding。因此任何會異動Base Table的指令都會失敗,如下圖所示。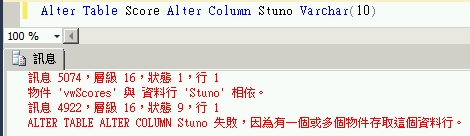
如果您是用SSMS的UI直接修改Base Table時,系統會告警但並不會阻止,所以要非常小心(如下圖所示)。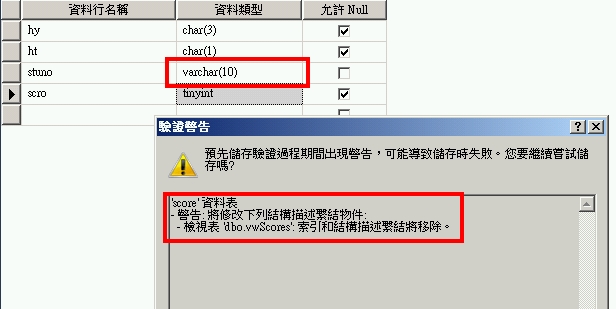
一旦您按下確認鍵時,該View會被重新修改,索引會被移除。因此原有的功能也就不存在了。下圖就是我修改Base Table時,Profiler錄到該View重新被Alter了。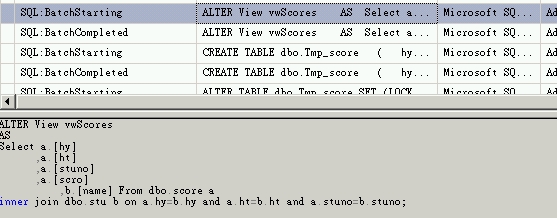
我是ROCK
rockchang@mails.fju.edu.tw


