去年底的跨年,終於把駐點14個月的專案上線了,這個客戶和幾年前上線的客戶最近都遇上統計值影響效能,來記錄問題,順便重修統計值(Statistics)。
統計值是描述欄位值與索引欄位值的分佈統計,也是SQL Query Optimizer進行基數估計(cardinality estimate)的分析來源,透過基數預估,進而決策出優秀的執行計畫來擷取或更新資料。
統計值統治的範圍包含一般資料表、#臨時資料表以及幾個新的企業版本@資料表變數都有統計值。
負責的系統上線了幾年,但不知為何,這幾個月兩家客戶接連發生統計值導致SQL效能的問題, 為了要讓老婆理解並能在專案會議中說明,分成幾篇介紹,今天先看見統計值。
測試SQL版本: (SQL 2014及2017) Enterprise
基數預估(cardinality estimate)
也許我們曾使用過”顯示估計執行計畫”的經驗(Ctrl + L),還沒真的執行,SQL就能掐指一算,資料表內有8個女兒喜歡的迪士尼公主,這種掐指一算就是基數預估(cardinality estimate)。
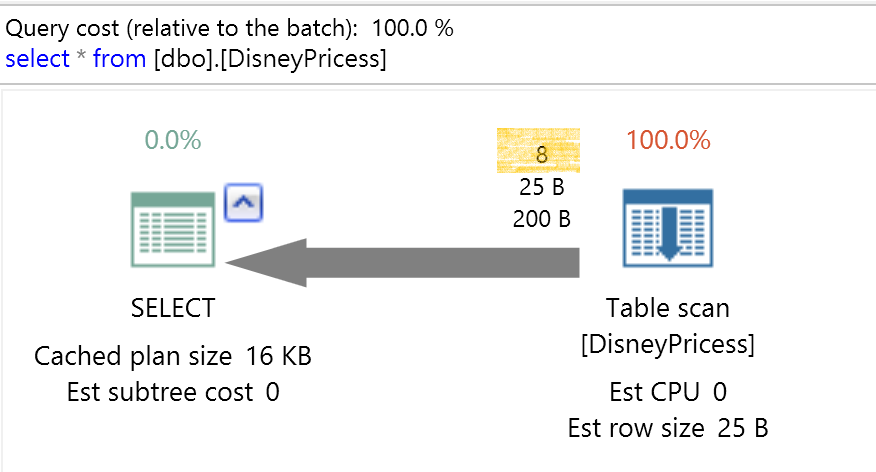
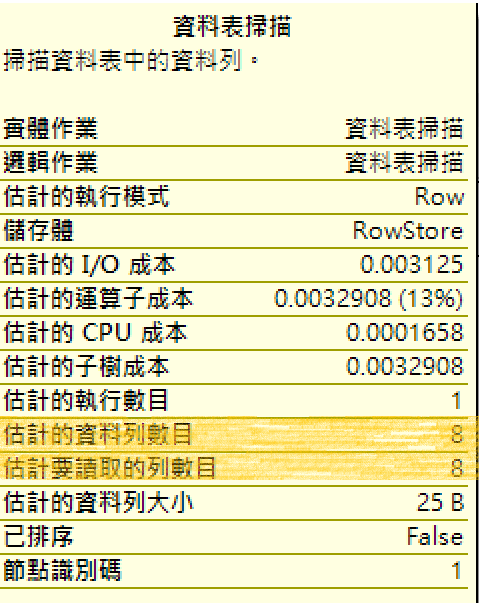
執行計畫中的每一個層級的資料數預估都有基數預估(cardinality estimate),他將會決定執行計畫選擇每個步驟資料的擷取及結合方式。
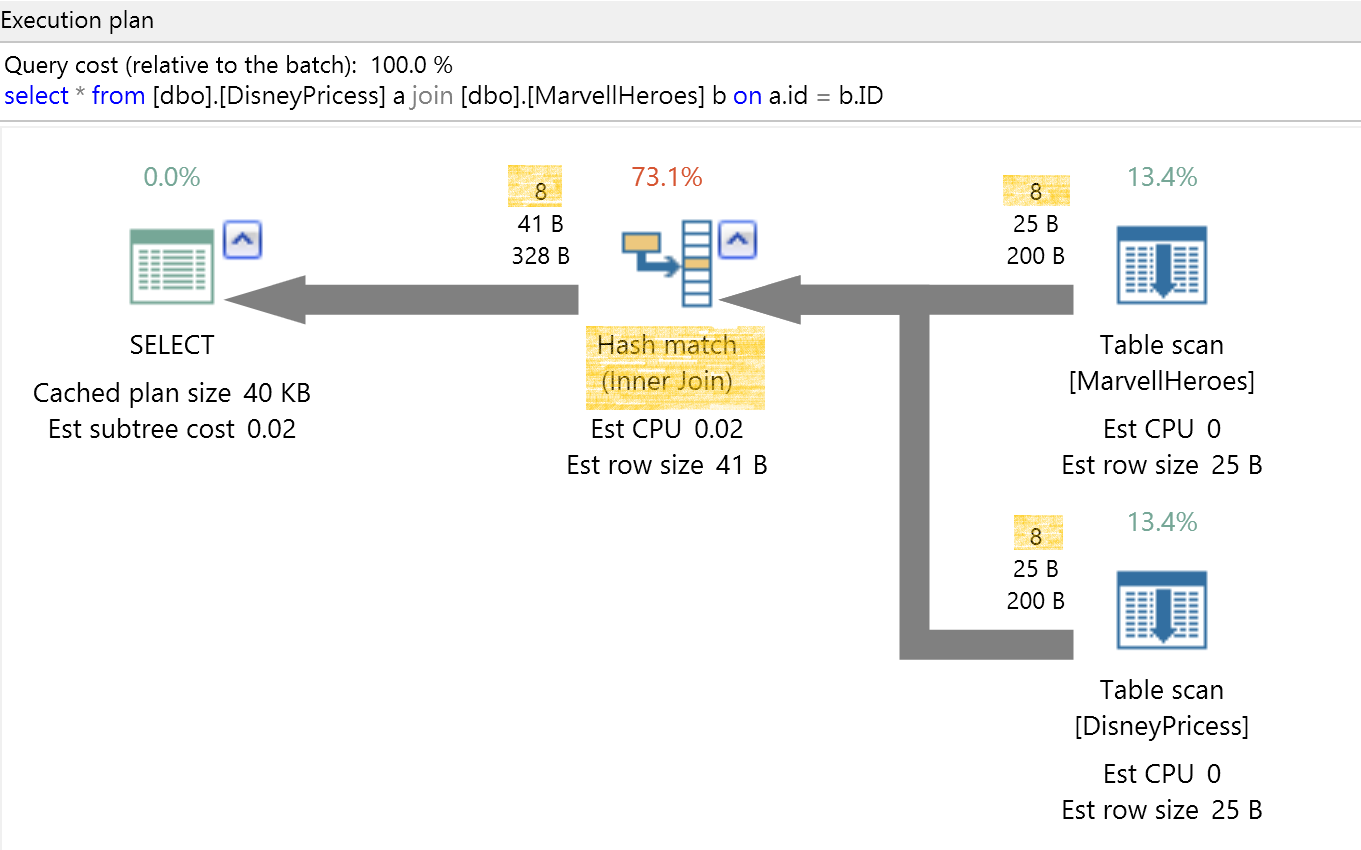
如果資料表大,但預估要查詢的資料列少,執行計畫會選擇書籤式搜尋(index seek + key lookup + nested loop);
但如果預估要查詢的資料列大,執行計畫就會選擇平行、逐頁掃描的方式。
而基數預估的資訊來源就是統計值(Statistics),倚重的就是統計值旗下的長條圖(histogram)與密度(Density)。
測試環境
先簡單建立一個資料表並加上一組索引,待會可以看見統計值。
CREATE TABLE BANK
(C1 INT,C2 INT,C3 INT)
INSERT INTO BANK VALUES(1,2,3),(1,2,3),(1,2,3),(2,4,6),(2,4,6),(3,6,9)
SELECT * FROM BANK WHERE C1=1 AND C2=1
CREATE INDEX IX_BANK ON BANK(C1,C2,C3)
看見統計值(Beyond Statistics)
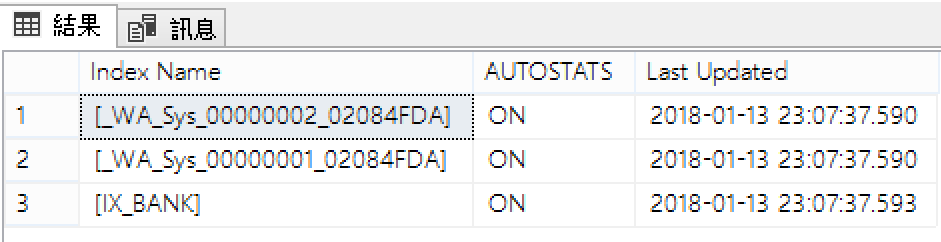
每個資料表都可能會依Query Optimizer的需要而建立統計值,除了索引欄位的統計值資訊外,當啟用自動建立統計值時(預設),Query Optimizer也會針對查詢述詞中的單一欄位來建立統計資料,統計值的名稱就會以 _WA_sys 開頭。

- IX_BANK是索引欄位統計值項目。
- _WA_sys分別是兩個欄位的統計值項目。
也可以透過system view、系統預存程序(SP_Autostats) 及DBCC SHOW_STATISTICS Command查詢指定資料表的統計值資訊。
System view(sys.stats)
select * from sys.stats s
where s.object_id = OBJECT_ID('BANK')

System Procedure(SP_Autostats)
SP_Autostats 'BANK'
DBCC Command(SHOW_STATISTICS)
輸入資料表名稱及統計值名稱,可以查詢到該個統計值摘要、長條圖及密度向量資訊。
DBCC SHOW_STATISTICS('BANK','IX_BANK')
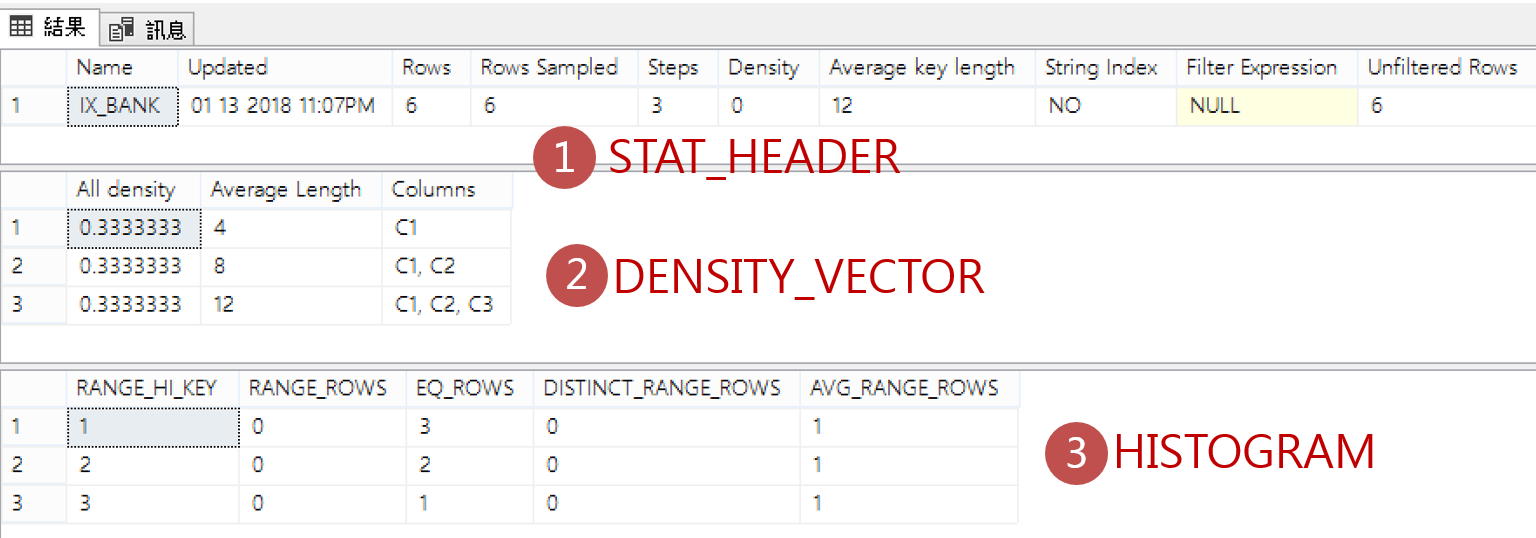
長條圖(HISTOGRAM)
![]() 就像我們在管理工具上看到的統計值圖示,每個統計值都會包含長條圖(histogram),長條圖內容儲存欄位值的分佈(Distribution),建立長條圖時,Query Optimizer會排序欄位值、計算相異數目,然後將結果彙總成最多200個連續的區間。
就像我們在管理工具上看到的統計值圖示,每個統計值都會包含長條圖(histogram),長條圖內容儲存欄位值的分佈(Distribution),建立長條圖時,Query Optimizer會排序欄位值、計算相異數目,然後將結果彙總成最多200個連續的區間。
*只包含第一個欄位
SQL 2016 SP1之後多了一個DMV可以查詢,sys.dm_db_stats_histogram,效果等同DBCC SHOW_STATISTICS WITH HISTOGRAM
SELECT
OBJECT_NAME(s.object_id) AS TableName
,s.name
,COL_NAME(scol.object_id, scol.column_id) AS 'Column'
,hist.step_number
,hist.range_high_key
,hist.range_rows
,hist.equal_rows
,hist.distinct_range_rows
,hist.average_range_rows
FROM sys.stats AS s
JOIN sys.stats_columns AS scol (NOLOCK)
ON s.stats_id = scol.stats_id
AND s.object_id = scol.object_id
AND scol.stats_column_id = 1
CROSS APPLY sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE s.object_id = OBJECT_ID('BANK')
ORDER BY s.name,hist.step_number,COL_NAME(scol.object_id, scol.column_id)
DMV查詢結果: 列出BANK資料表每個統計值的長條圖資訊(包含欄位名稱、步驟次、區間間隔範圍、區間內的筆數、相異資料的筆數、平均筆數等)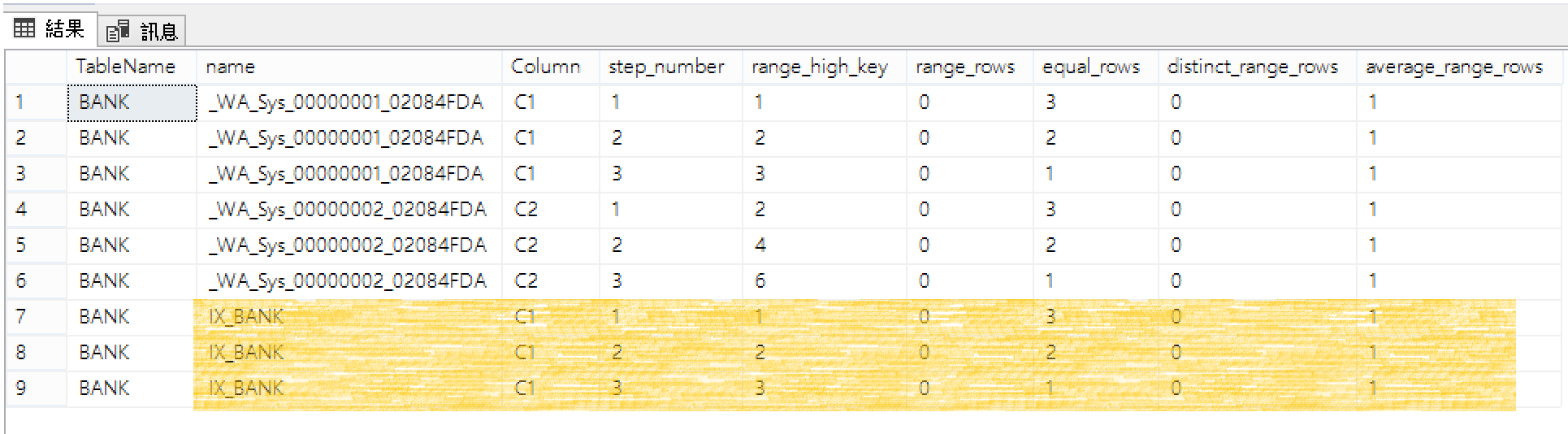
DBCC SHOW_STATISTICS也能查出類似資訊,只差少了欄位名稱。
DBCC SHOW_STATISTICS('BANK','IX_BANK') WITH HISTOGRAM

也可以透過SSMS管理工具查看
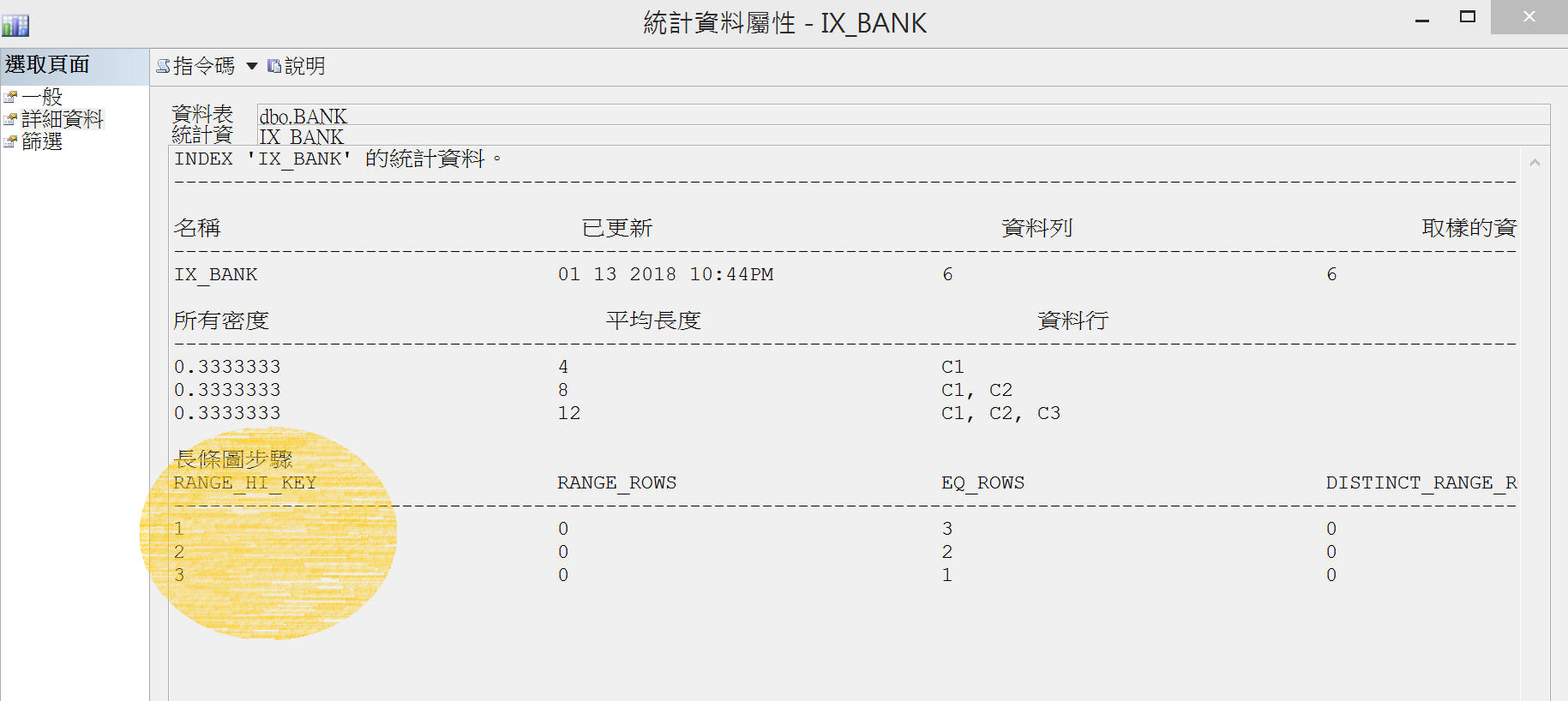
有了長條圖,Query Optimizer就能將輸入的SQL查詢條件值進行資料量預測,也就是基數估計。
密度(DENSITY):
密度是欄位值相異數目的比例,簡單的計算公式就是1 / 欄位值相異數目。欄位或索引中的統計值密度資訊分別儲存單一欄位或欄位間值相異資料的密度資訊。
因為我們給的資料雖然有6筆,但C1的值只會出現1,2,3,密度就是1/3 = 0.333333
(1,2,3),(1,2,3),(1,2,3),(2,4,6),(2,4,6),(3,6,9)
索引內的密度
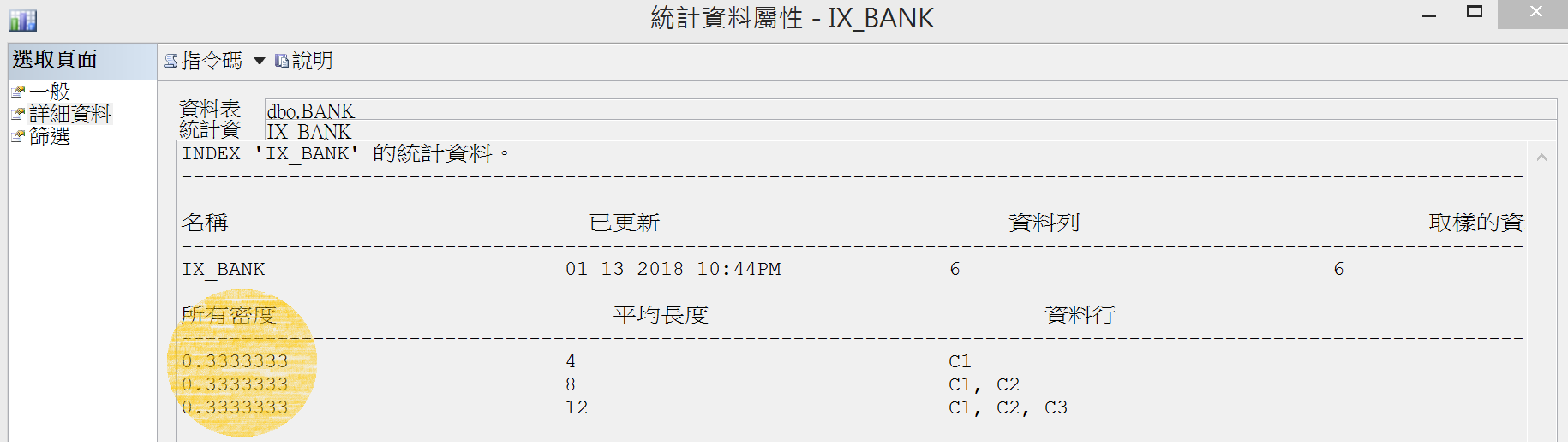
DBCC SHOW_STATISTICS WITH DENSITY_VECTOR
DBCC SHOW_STATISTICS('BANK','IX_BANK') WITH DENSITY_VECTOR
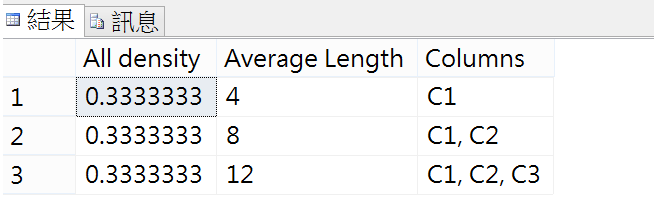
觀察密度的變化
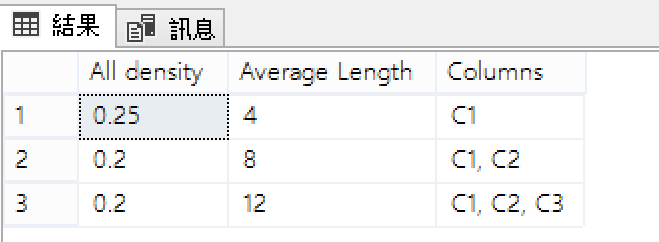
再新增幾筆資料,同時更新統計值。
INSERT INTO BANK VALUES(1,99,99),(5,100,100)
UPDATE STATISTICS BANK
欄位C1從3個值增加1個5的相異值,欄位C2和欄位C3則多了2個相異值。1/4= 0.25%,1/5=0.2%。
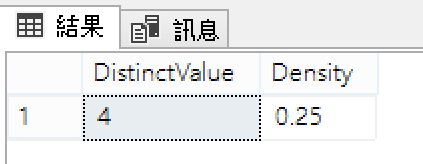
密度計算T-SQL
Select [DistinctValue]=Count(Distinct C1),
[Density]=1/CAST(Count(Distinct C1) AS Float)
from BANK
GO
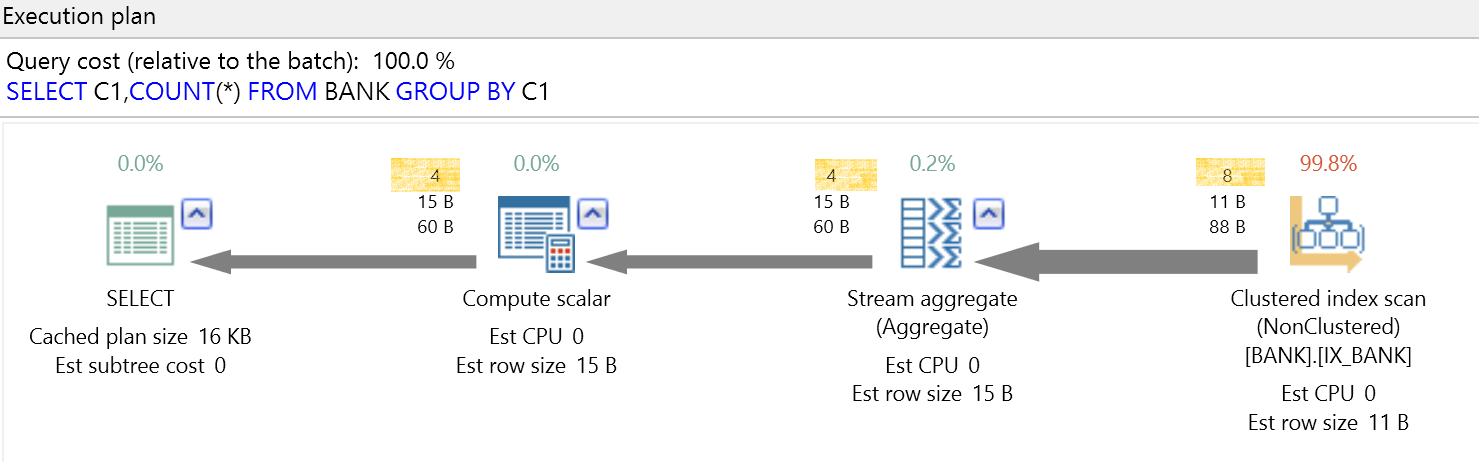
密度其中一個用途就是Group by
SELECT C1,COUNT(*) FROM BANK
GROUP BY C1
還沒執行彙總,就能預估4筆
記錄欄位值分佈的長條圖(Histogram)與欄位值密度(Density)對SQL Optmizer就像是情報中心,有了正確完整的情報,SQL Optimizer就能擬出優秀的計畫。
這篇先筆記看見統計值的幾種方式,下一篇來介紹不新鮮的統計值的影響。
 2018/1/1 內湖瑞光路583巷,換新招牌的工程
2018/1/1 內湖瑞光路583巷,換新招牌的工程
參考
Docs sys.dm_db_stats_histogram
Docs system view-sys.stats_columns
Docs system-stored-procedures sp_statistics