在報表視覺化的市場中,自從 Gartner 在八年前,增加了一個 Aanlytics and Business Intelligence Platforms 的新領域,它就陸陸續續將 UI,UX,In-memory,Cloud,Data Warehousing,ETL,Streaming...等考題加了進來,為大家評比到底什麼才是企業消費者最需要的解決方案?基礎於這些企業所考量的需求面向,本文將會為大家介紹在新的時代中,該如何考量從後端到前端的報表視覺化?
前言:
即使在科技日新月異的現代,在許多資訊領域中,還是無法產出100%可以完全覆蓋的產業標準,所以像視覺化 BI 分析平台這一段,大部份的企業還是會參考 Gartner report來做為選擇與採購解決方案的依據。在2020的時間點上,它在評比上述的這個領域,是以六大項目來做為考題,包含了:敏捷、集中式的佈署Agile, centralized BI provisioning;獨立/自助式分析Decentralized analytics;在安全控管前題下的資料探索 Governed data discovery;允許二次加工/嵌入式的解決方案 OEM or embedded BI;可兼具企業內/外甚至是跨平台的佈署 Extranet deployment;增強式的分析 Augmented analytics。以下我們將基礎於六大項目與傳統的 Infrastructure 架構,來介紹該怎麼規劃你的分析平台?
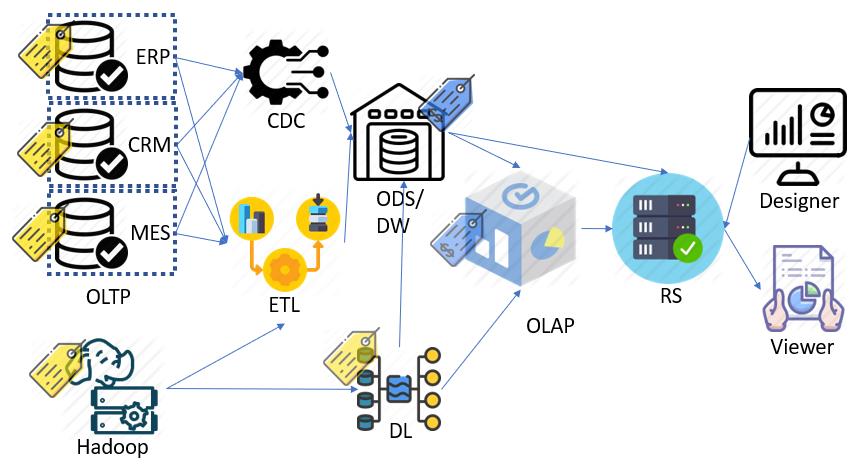
一、AP應用程式的OLTP(交易型資料庫):
在大部份工作者的大部份時間中,大家所存取的系統就是線上交易型的資料庫,包含CRM 客戶關係管理系統、SFA 銷售系統、ERP 企業資源管理系統(或是範圍小一點的"進銷存")、HRM人力資源管理系統…總之,公司為了要達到自動化、資訊化、集中化的管理,會以向外購買或是自行開發的方式,來取得不同類型的應用程式(或稱為XX系統),並且依據權限的劃出來提供給不同工作職掌的員工來使用。只要它不是雲端的 Saas服務,系統都會有交易型資料庫的配置。假設,我是一家電力公司,打算要提供一個線上的用電系統,讓使用者可以隨時來查詢用電的度數,以滿足客戶在用電策略優化的需求。例如:高用電監控與警示(避免設備過載而跳電)、用電級距計算(夏季)、記錄平時的電力需求以了解在離峰時段要儲備多少電力、領取節電獎金(比上個週期用的少會有獎勵)、成本分攤…等。
若要與項目三OLAP(分析型資料庫)做比較,OLTP所使用的技術叫做SMP(symmetric multiprocessing) aka 對稱式的多執行緒處理,相較於單一執行緒,它可以在多人作業的環境下運作的很好。尤其是它的 insert 時的 check 機制與 two phase commit 特殊技能,讓它可以擅長在與金額有關係的交易上,即使是跨行交易的 ATM也都得心應手,十能九穩!企業只需要提供較好的硬體規格,就能滿足財務上錙銖必較的平衡需求,穩固企業的金援後盾。至於量大與金錢無關則要出動項目六Hadoop/Data Lake (雖然這次介紹的不是 NoSQL,但 Hadoop是能夠滿足一部份這種類型的需求)來救援…
二、ODS/DW操作型資料儲存:
以上述的"線上的用電系統"為例,為了滿足二個月出帳一次的週期,但是又不能打擾 OLTP的運作(曾經有人在上班時段,去跑分析型報表,結果造成系統反應遲緩,資料登打或輸入作業受阻,搞得怨聲載道),會需要一個 Operational data store操作型資料儲存,來滿足主題性的資料中繼分析儲存需求。例如彙總後的單月用電量、彙總後雙月用電量、客戶折扣(老客戶優惠、新客戶優惠、軍公教優惠…)、節電獎金(用電量比上一個週期少時所提供的獎金)、用電計費公式(夏季有尖峰時段的級距費用加乘),當我們透過項目四 ETL工具(商業邏輯複雜度高)或是項目一交易式資料庫(商業邏輯複雜度低),把相關的資料表做關聯(Inner/outer/left/right join)、必要的資料操作(把猜半天的代號改成精確的名稱,合併上下階層的資料成單一欄位,將一大串的地址拆分成國家、縣市、郵遞區號…) 與 Aggregation(sum/avg/med/min/max/mod/count/std...),計算出結構性的「主題性」分析結果,並且透過經濟實惠的儲存裝置,存起來以供進一步的戰術分析應用。
如果預算充足,ODS這種抽象式的儲存空間概念,會用 Data warehouse 資料倉儲的解決方案來滿足,而不是DAS、NAS便宜的方案。DW它具有四大特性,主題導向(Subject-Oriented)、整合性(Integrated)、時間差異性(Time-Variant)、不變動性(Nonvolatile),可以滿足更複雜的需求,可提供全公司戰略層面的分析報表,當然它裡面也包含了 Data mart 資料超市,這種部門層級的分析應用。
三、MPP分析型資料庫(OLAP):
雖然SMP的OLTP 在規格很好的硬體上,處理50TB以下高達數十億的大量資料,在理論上都是可行的。但是由於更大量的資料分析,在任務的特性以及軟硬體的匹配,其實會有不同的考量,所以會導致 SMP 在這種 50TB以上的量級,因為是做垂直擴充 Vertical scaling 在單位成本上居高不下,必需要採用 MPP(massively parallel processing) 這種水平擴充 Horizontal scaling才能發揮的更好。舉例來說,你想從一本故事書中,分析它用了多少的標點符號,你可以用二個人騎馬打仗,並且把問題拆成二題,一個人戴眼鏡解一題(例如從前面解),一個戴眼鏡解一題(例如從後面解),然後把數字合起來;這個就是二份,一顆CPU配合一片記憶體的 SMP運算。當任務開始複雜,由一本故事書變成一套百科全書時,把整套書撕成N份,由N個人手拉起手繞成一大圈,戴上眼鏡開始解相同的問題,但每個人只針對自己的範圍來解題,然後再合計出所有的標點符號,會更有效率;這個就是N份,不受 CPU與記憶體綁定在同一個 Bus的硬體限制,可以更自由地做任務分組的 MPP運算。

雙方其實是有各自的優缺點,例如,MPP 雖然對於這個硬體資源池的容錯 Fault tolerance 比較高,但是相對來說它的 Reliance 信賴度也讓它損失了較多的效能,另外就是它在高可用性的管理成本上是高於 SMP許多的。所以一定要針對應用情境、資料量…等因素,找出最適合的解決方案,不要盲目的追求某一種。
**關於垂直擴充與水平擴充的比較,因為也常被客戶問到,我就用剛才的例子來說明,到底是將多個人往垂直方向去堆疊容易?還是往水平方向去組成更大的圈子容易?只需考量地心引力,這個問題就有答案了!這也是分散式運算後來大興其道的主要優勢,所以在 SQL 2019中 Big data cluster 的軟體授權中,我們也看到了,除了傳統的 SQL Engine 還多了一種每年400美金的「Big data node cores 巨量資料節點核心」SKU,就是一種新的混合式的設計架構(細節可以參考官網的說明),讓企業不再被硬體的硬碟插槽所限制住,可以不斷地進行水平方向的擴充。

至於 SQL server 到底是 SMP還是 MPP?一般你買到的都是 SMP的版本,特殊一體機的 MPP的版本APS 現在也停產了,接下來,若你的公司有需求,也只能上雲去租賃了!這個服務叫做 Azure Synapse Analytics (前身是 Azure Data Warehouse)
四、ETL工具:
為了在 OLAP能,在早期它是 Extract/Transfer/Load 三個步驟的縮寫,但是在大數據時代它已經進化成 ELT 更優化的順序步驟。例如,在 Extract 階段連接不同的來源資料庫、Flat file(*.txt, *.csv...文字檔)、網站…;然後在 Load 階段把資料搬到 ODS或是 DW端;最後在 Transfer 階段做字串處理(例如將 Year 與 Month 合併為年月,並且在中間加上"/",成為"2021/04";把"01"、"02"的值分別改成 "男"、"女" …)
常常有客戶會問我說,針對他們公司我會建議採用 ETL還是 ELT?我一定會問清楚客戶的環境,然後再回答。有趣的是,許多人以為這是一代與二代的差別。如果我回答你們公司適合用 ETL,他們會帶的不屑的表情說,你的規劃已經過時了。殊不知,ELT是用在非關聯式資料庫的情境,例如 Hadoop在用的,用錯了你會等更久。
你可能會問,隨著時代在進步,難道沒有更好的解決方案嗎?以市場上的領先者 Snowflake 為例,它就是應用了 Virual ETL與平行處理的技術,並提供了高可擴充的大量運算資源,讓你可以連接市面上絕大多數的各種格式的資料源,接著在進行批次載入的同時,也把資料清理/轉換也做好了,直接一次就送到 Data Mart。而不用先進入 DW再去 Data Mart。
**業界比較有名的有 Informatica, Trinity, SSIS, Pentaho, Talend
五、CDC工具:
它的全名叫 Change data capture,是一個間諜式的資料複寫工具,可支援同質與異質的資料庫。例如在台灣常見的應用情境,台商覺得企業命脈的 ERP/MES 肚子中的資料庫是用到價格較高的 Oracle,但是又想在經濟實惠的條件下發展其報表系統,所以就採購了 CDC 的解決方案。厲害的 CDC能夠以間接的方式讀取 Oracle 的 Redo Log,透過這種高明比較不傷效能的方式,來實現 slow changing dimension,配合所需的商業流程,把逐筆的資料來源以彙總或是明細的方式,複寫至目標資料庫。例如,對於不常發生的"客戶地址"欄位的異動,我要新增、修改、刪除的明細。對於常發生的"業績"欄位,我只要當天"新增"的彙總,來了解今天新進帳的金額是多少?
**業界比較有名的有 Attunity, Goldden gate, SharePlex, HVR
六、Hadoop/DL巨量資料處理與資料湖:
隨著世界級的搜尋引擎與社群網路的發展,對於這種 PB以上等級的巨量資料會需要包含 Name node與 Data node 的 Hadoop 分散式 MapReduce 運算的解決方案(或是再衍生出來的 Spark, Storm…)。後續它又應用在形形色色的場景中,例如:線上旅遊網站、eBay這種電子商務、Chevron石油開採…但以上的應用只包含單純且巨量的數據(品項、開採點)處理部份, 包含對Log做分析、文件的字詞分析、對分佈做排序、反向索引、字串處理…等作業,並不包含金流(OLTP比較適合)或是其他需要做什麼 Moving average 移動平均這類的複雜運算…
接下來,Data Node又發展成一個抽象的容器,可以兼容低、中、高不同轉速的儲存裝置;透過不同成本結構來符合企業中不同的情境,就是所謂的資料湖。
總之,項目六,可以是 BI 報表的一個資料來源,而非必要的角色。
七、報表工具:
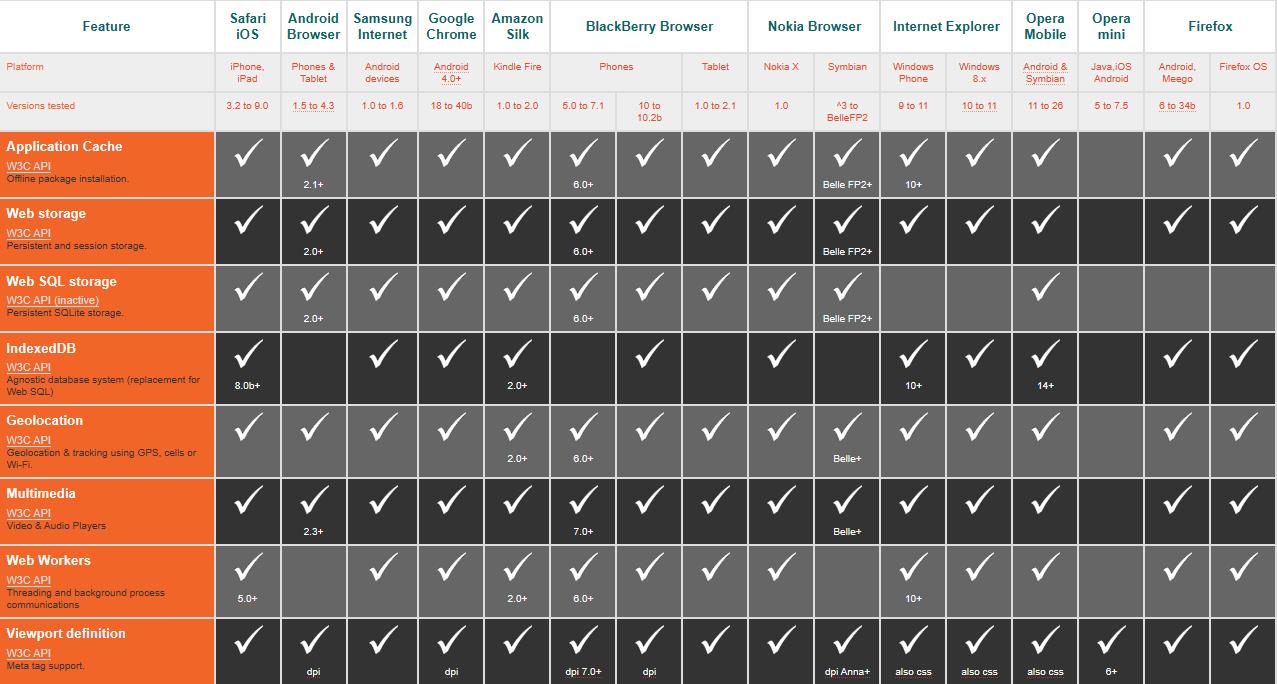
已故的管理之神曾經說過:「企業的經營靠管理,而管理靠報表」,可見報表對於企業的重要性。但是早期一頁30~50列的「編頁式報表」,雖然可以做到上/下頁、第一頁/最後一頁的操作,但是隨著管理之神事業的發展,他看的報表也進化到,基礎於 Html5 (下表是2014年底 release 的公開標準) 與 Native App的「行動式報表」;甚至是近五年基礎於 D3.JS 的高度視覺化報表(例如 Tableau 與 PowerBI)
八、報表伺服器:
承上,既然有了報表,接下來就會衍生出閱讀者的需求,會有人想要站著看、躺著看、白天看、晚上看、用電腦看、用手機看、用Pad看、用App看、用Browser看、看完還要下指導棋…等問題,都需要靠 Reporting server來實現。
過去透過 VPN 來連線企業 Intranet 的報表伺服器,除了會遇到企業對外頻寬大小、VPN連線人數限制、機房維運輪班人力調度…等挑戰,還會有 ROI的 review challenge。在目前公有雲愈漸普及的情況下,像 PowerBI這樣的 Saas服務,一個月只要 9.99美金(大約是320元新台幣),就能享受算人頭吃到飽報表服務。若企業採用 Saas,也可以透過 Iaas 的方式佈署在 SLA 99.9以上高可靠度的Azure 機房,將你的報表伺服器托管在雲端機房,甚至可以排程,除了上班時間、老闆宵夜場、老闆清晨高爾夫球場之外,系統就下線來節省費用,都是彈指就可以實現的。
九、人工智慧:
在白雪公主的童話故事中,壞心的後母使用了魔鏡詢問了「世界上最美麗的女人是誰?」,基礎於NLP技術的成熟,當我們可以用自然語言來詢問商業問題,繪製報表的時間就能從最快的30分鐘的手工報表,縮短為10~30秒。例如:「Show me year over year difference in average sales over ship date by line chart」當你一個字一個字的打進去(在歐美地區的 Cortana有支援你在 Win10 的環境下用講的)時,畫面上,就會依序的出現,在所有歷史記錄中,平均銷售金額的逐年變化的 Bar chart;然後輸入到 ship data時,畫面會將原先的 order date 改成你指定的 ship date;最後再依你的指示將 Bar chart 改成 Line chart折線圖。這個功能在 Power BI叫作 QnA,在 Tableau叫作 Ask data。
另外,二大陣營,還分別在資料源匯入時,用人工智慧自動解析資料格式(日期、字串、數值…)、Mapping key(用二邊的欄位名稱來建立關聯性)、將第一個 Row視為欄位名稱;或是自動分析資料內隱含或相依性的資訊,在 Power BI叫作 Insights,在Tableau叫作 Explain data。提供 Prediction趨勢線(Power BI官網、Tableau官網)…
總之,二大陣營都儘可能應用 AI來方便消費者的使用。
十、其他:
延續本系列的第一單元 BI 報表的概念,透過三部曲希望能協助大家快速上手,做出漂漂亮亮的精美報表。所以安排在本文來補充,整個 BI 生態系甚至是較嚴肅的資料分類/歸檔議題。
Connet:由Desktop 出發,去連結到DB(MS SQL, MySQL, Oracle)與非DB(Excel, PDF, TXT, 雲端的ERP/CRM/POS...等系統)
Analye:透過Report, Dashboard, Story 的視覺化設計,對階層式的視覺化元件下鑽或是對多個視覺化的元件的相互連動,去呈現既有的事實、去預測未來的數據、去推估未來的發展
Share:在資訊安全的基礎下,實現報表在不同裝置、不同對象、不同時間…的視覺化呈現與分享(對上/下游廠商、對主管/下屬/同事…),以及溝通(意見傳遞、指令下達、腦力激盪、High light…)

十一、資料分類:
資料分析其實跟 Machine learning 很像,需要先有數量以及Tag (分類標籤),才能由 OLTP進到 OLAP的。例如透過分類分出 Operation / Business來,然後分別把資料留在 OLTP 與把資料做彙總後匯入 OLAP。
為此微軟也透過併購 ADRM Software 這家公司來提供給客戶更完整的解決方案,針對想透過優化自家的流程成為業界翹楚的客戶,可以買他們的 Industry models(產業最佳實務模型) ;針對想透過精進自家解決方案的客戶,可以買他們的 Solution models;針對想透過強化不同 functionality 部門的競爭優勢,可以買他們的 Business area models。你可以快速地參考產業中的最佳實務,如何規劃資料的層級( Level)?如何規劃一個包容萬物且兼具彈性的架構?如何一致性的執行資料的分類?當中又是採取什麼樣的命名規則?甚至是資料治理的策略為何?
十二、結論:
最後我想用 OLTP與OLAP的比較做為總結,來呼應本文「全局思考」的標題。OLTP 是地主篳路藍縷的創業之路必先招募的夥計,在時間上它會比 OLAP來的早,例如有錙銖必較管帳的帳房先生,與小心謹慎管錢的出納小姐,地主會配置給他們二個,非常合身剪裁的工作服(資源)與彈丸之地的服務櫃台(儲存空間),此外因為怕有舞弊或內線交易之嫌,許多資訊都被分散至最小以防止相互連結出公司大方向的發展策略,但也由於個人負責的範圍小,會被要求被問到問題時,要在最短地時間內回答出來。另外還被地主要求的定期拍照後重建 (Backup/ Restore) 這種類型的防災演練來對抗各種的天然災害;
當事業發展到一個程度,地主不再凡事需要親力親為,開始會想要招募精明幹練的 OLAP 掌櫃來幫他提供策略與方向,會大方地配置給他,寬大華麗的錦袍(資源)與甲第星羅的寫字樓(儲存空間),甚至允許掌櫃可以在私人的庫房中,建立一個五芒星陣(Star/ Snowflake schema) 以大房間來管理錢/帳/庫存/銷售…等議題(多主題資料),但也因為問題的範圍大,是可以容許用長時間來準備的;至於地主要求的防災演練,他則會大器地選擇定期(每個月/季)重新裝潢一次 (整批 Reload) 來取代傳統的拍照後重建。
李秉錡 Christian Lee
Once worked at Microsoft Taiwan