Azure Machine Learning workspace
前言
此篇為補充方式呈現
其實主要出入是這篇舊文章是 V1 API
DAY03 建立 Datastore 和 Dataset (上) - 10 上傳資料檔
https://github.com/dsindy/kaggle-titanic/blob/master/data/train.csv
DAY04 建立 Datastore 和 Dataset (下)
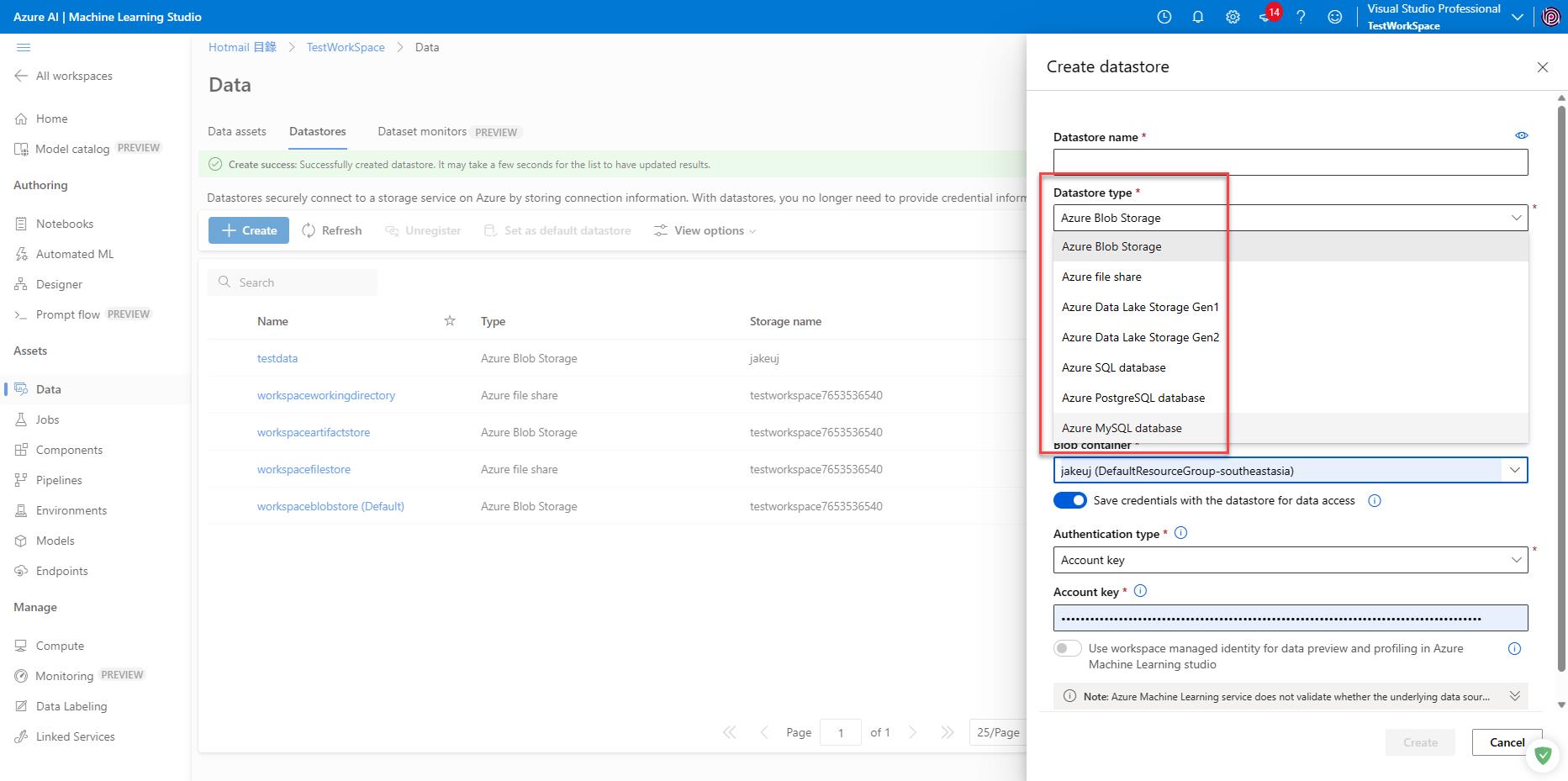
Data types vs. dataset types
Data asset types
The Azure Machine Learning CLI v2 and Python SDK v2 now include the following data types:
- uri_file (display name: File)
- uri_folder (display name: Folder)
- mltable (display name: Table)
Learn more about data asset types
Dataset types
Dataset types from Azure Machine Learning CLI v1 and Python SDK v1 can still be used, but will be mapped to the appropriate data type in the v2 systems:
- file dataset type: maps to Folder type
- tabular dataset type: maps to Table type
Learn more about dataset types
Compute
- NV6 (M60) 將於 2023/7/31 棄用
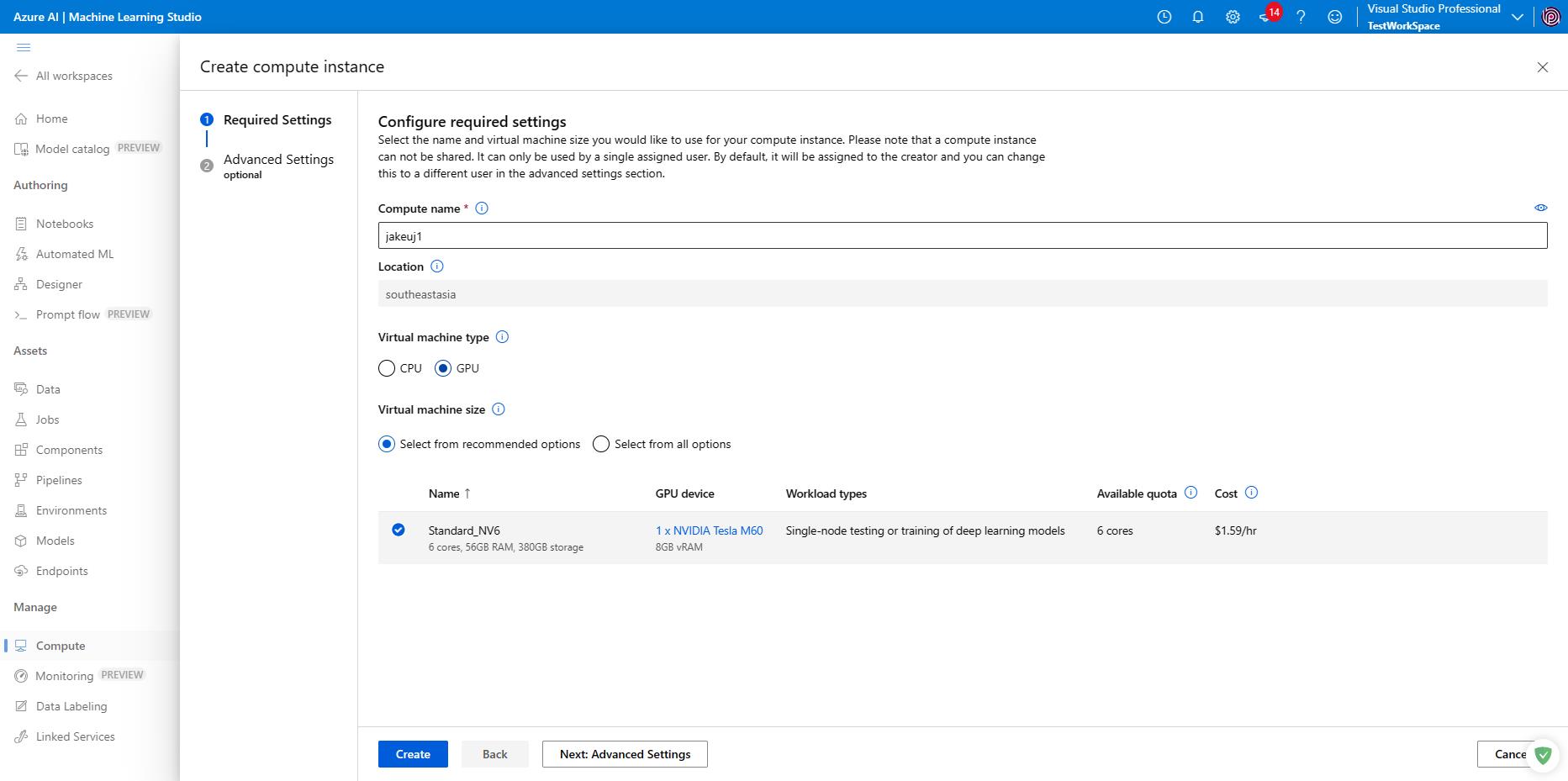
還有 serverless 可以選,但第一次按了要等三到五分鐘
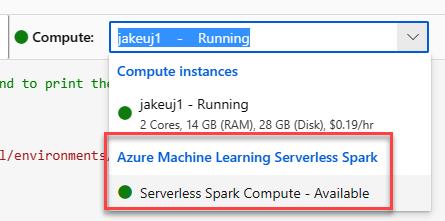
看起來是閒置 20 min 釋放

Lib 是用 pyspark,懂 Spark 可以研究一下
在 Azure Machine Learning 中使用 Apache Spark 進行互動式資料整頓 - Azure Machine Learning | Microsoft Learn
NoteBook Sample
import pandas as pd
df = pd.read_csv("azureml://subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/MLRG/workspaces/TestWorkSpace/datastores/testdata/paths/test.csv")
df.head()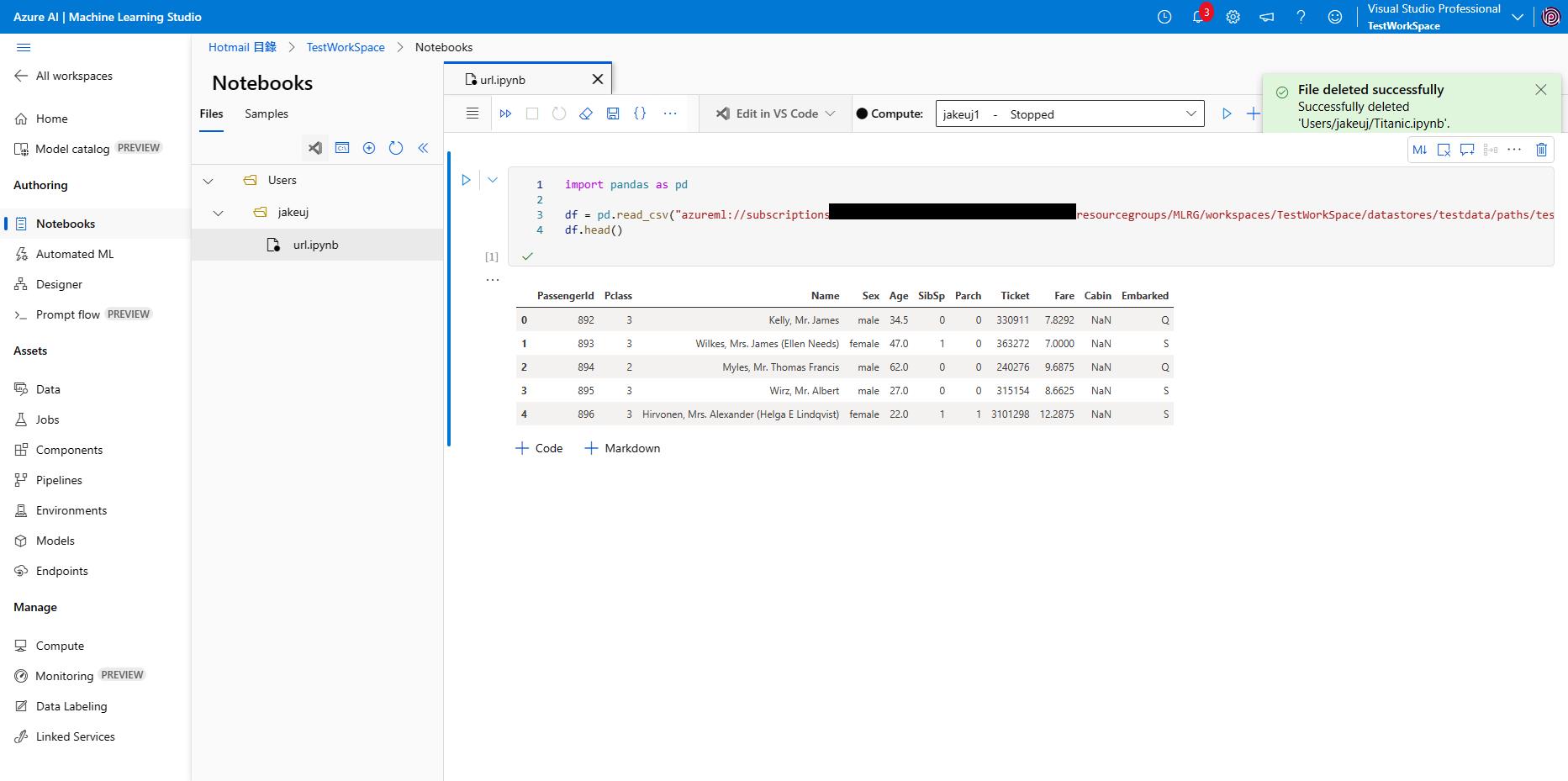
azureml 可以從設定好的 DataSet 中取得
Designer
6. select columns: Survived, Pclass, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked
13. 在右邊 asset library 輸入 train model,拖曳到 Canvas 中,用 filter based feature selection 左邊的點點連接到它。 Train model 的右邊方框,在 Label Column 選擇 Survived。(原文為 Survivde)
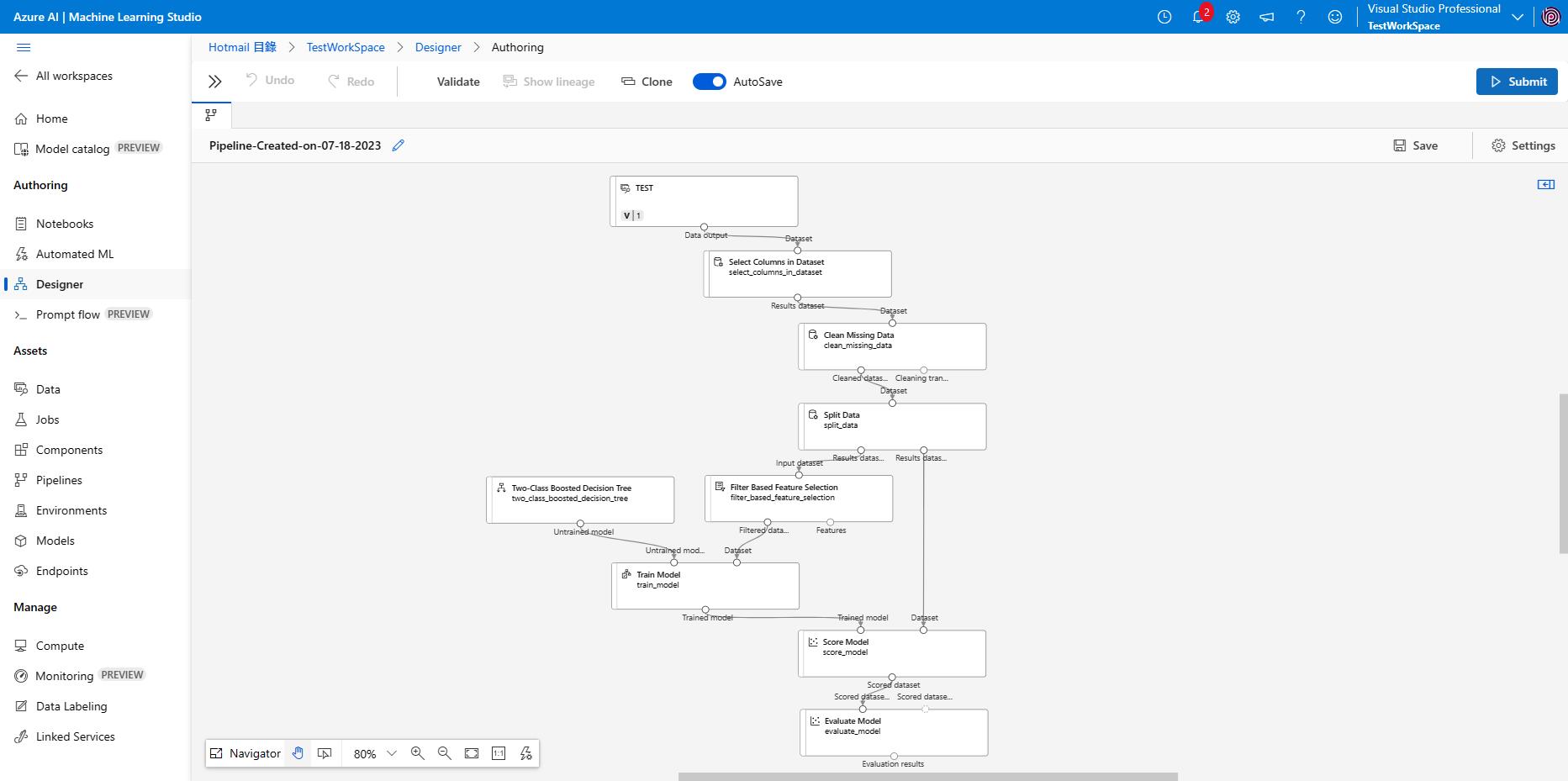
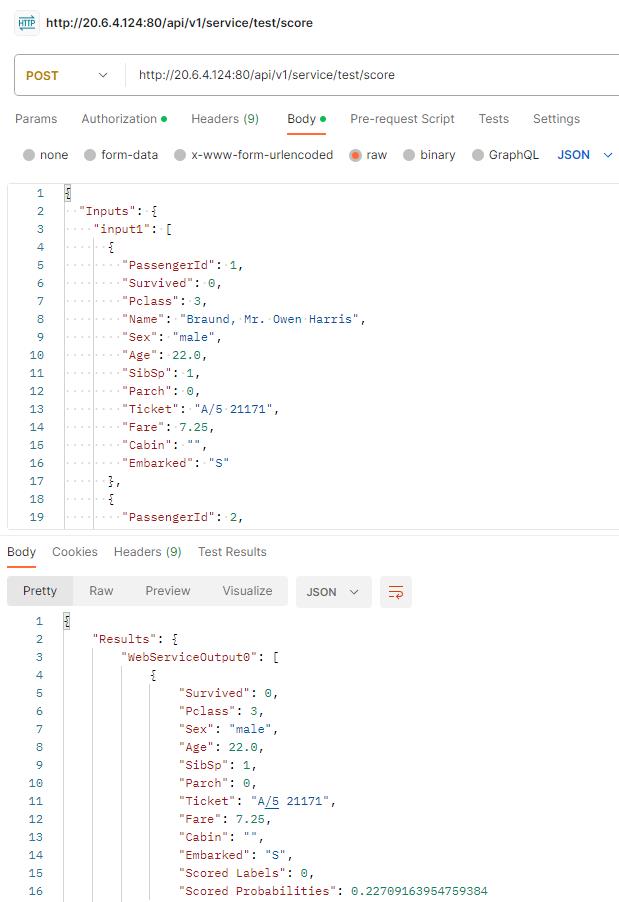
DAY08 部署用 Designer 做好的 Pipeline 到 Web API
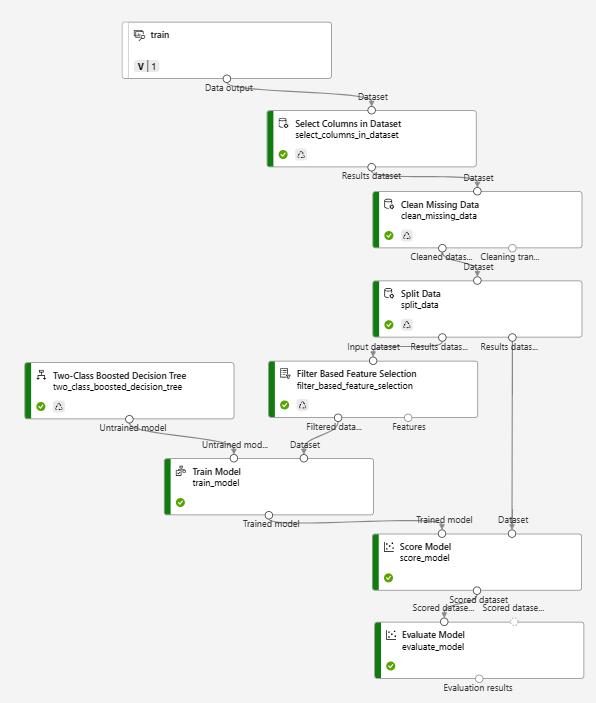
Create inference pipeline 在 Job 結果裡面
SDK
azureml-sdk: This package has been tested with Python 3.7, 3.8, 3.9 and 3.10.
參照
[DAY06] 開始用 Notebook 在 Azure Machine Learing 上寫程式 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
什麼是 Azure OpenAI 服務? - Azure AI services | Microsoft Learn
