上一篇文章中,我們探討到CheckPoint檢查點會將記憶體(Buffer Pool)中的中途資料分頁flush到磁碟上,其中checkPoint又可以分為自動、間接、手動及系統內部觸發幾種類型,這篇我們來嘗試使用SQL Server 2012推出,SQL Server 2016正式推薦使用的間接檢查點(Indirect CheckPoint)機制。
在此之前,我們先回到SQL Server 2016以前版本的預設:自動檢查點(Auto CheckPoint)機制,順道確認在ldf與mdf不一致時,ldf檔案是否能回追資料(ReDo)。
自動檢查點機制 (automatic checkpoints)
通常我們不會特別設定檢查點機制,因此預設就是使用自動檢查點(Automatic CheckPoint)。
Technet文章說明:
如果想進一步了解自動檢查點的收集Dirty Page的機制或是舊版SQL 7.0的排列搜尋機制(elevator seek),推薦大家參以下這篇由三位SQL軟體工程師撰寫的文章。
SQL 2016 – It Just Runs Faster: Indirect Checkpoint Default
不過,因為伺服器層級的組態設定Recovery Interval是0,看起來只剩下儲存時的磁碟反應時間可以觸發自動檢查點!
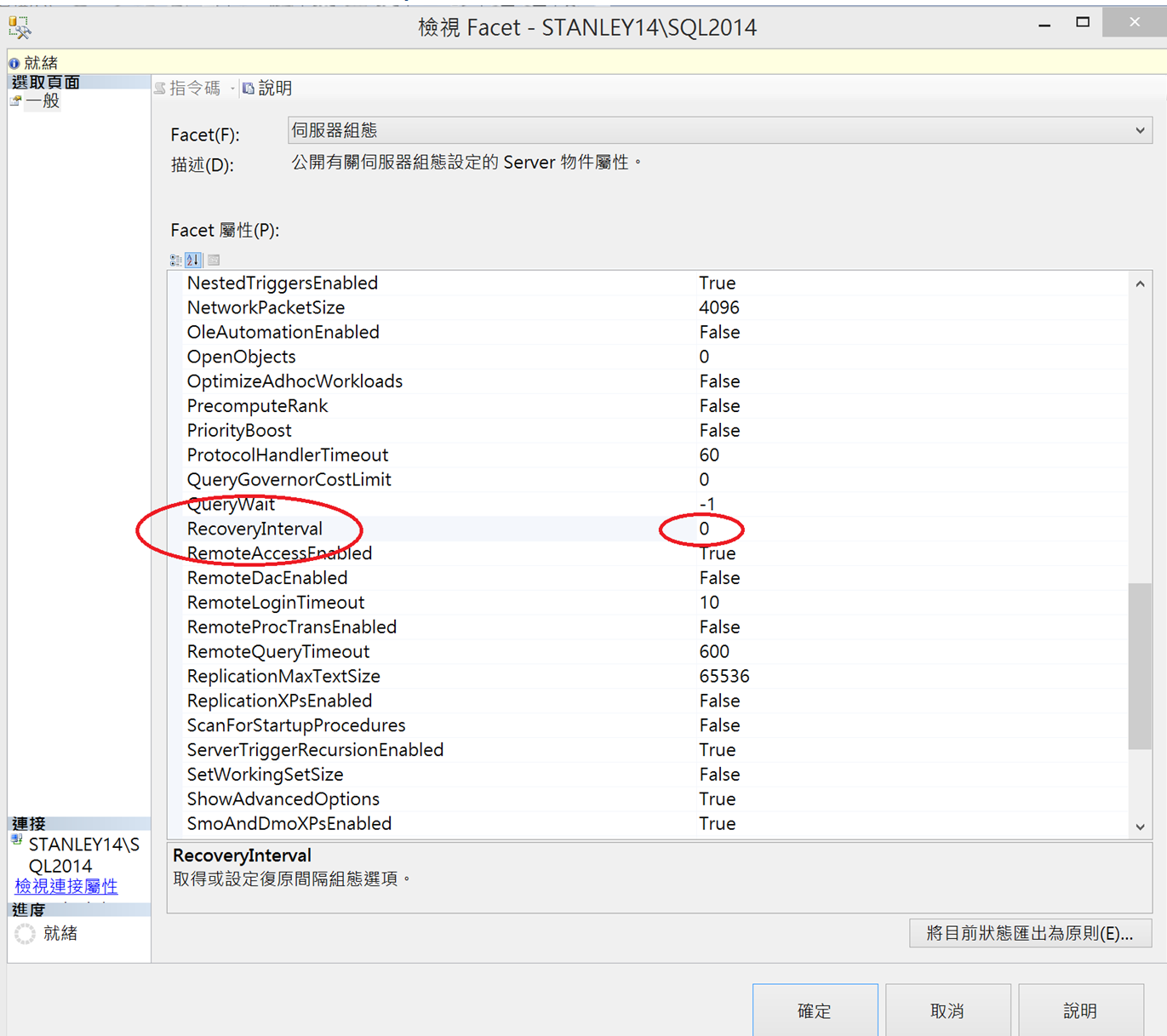
這邊我們先離題一下!
如果反應時間沒有慢到達標(Auto CheckPoint)、沒有收集到足夠的Dirty Page(Auto CheckPoint)、沒有記憶體壓力(Lazy writer)、沒有手動及系統內部的檢查點被觸發,總之就是沒發生Flush到Disk的活動,已經commit的資料分頁會不會一直待在Buffer Cache?
如果答案是YES,那麼使用Storage廠商同步到異地的機制,是否能正確回追(ReDo)資料?
mdf與ldf不同步的實驗
1.我們先打開process monitor,按照上一篇的步驟設定Filer條件。
2.然後試著執行一段迴圈:每一秒打一筆交易到資料庫內,接著Commit,依此類推執行120次,然後出去跑步10km加上回家洗澡,觀察1小時多中的磁碟活動:
USE [FlushDiskDb]
drop table t1
create table t1
(
c1 int identity,
c2 varchar(30)
)
Declare @COUNT INT = 0;
WHILE (@COUNT < 120)
BEGIN
BEGIN tran tran_1
SET @COUNT = @COUNT + 1
INSERT INTO t1
VALUES ('T' + CONVERT(VARCHAR, @COUNT))
COMMIT
WAITFOR DELAY '00:00:01'
END
神奇的是完全沒有偵測到資料檔(mdf or ndf)的寫入,在記憶體long stay 1小時了!
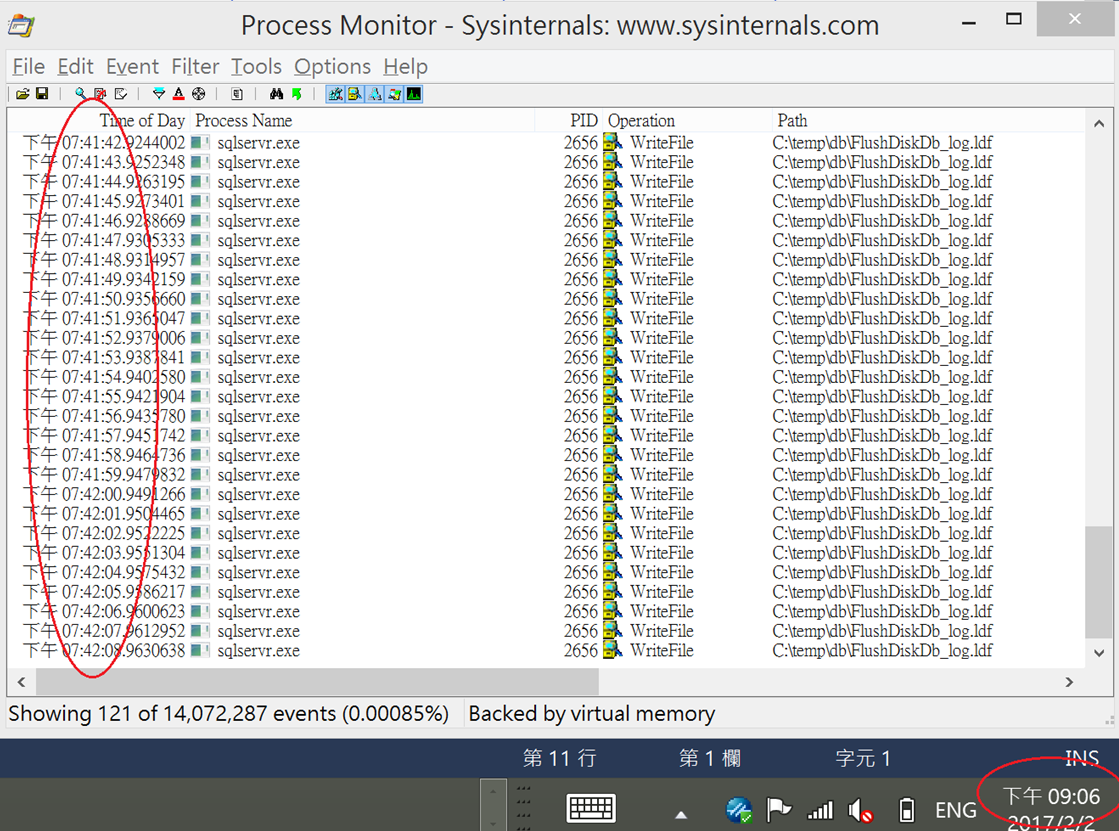
查詢Data Buffer也發現的確還在記憶體,尚未flush到Disk

3.模擬storage廠商的異地同步機制,因為Database在線上,沒辦法複製,我們用暴力的方式kill sqlservr process,避免觸發了系統內部的check point
taskkill /f /im sqlservr.exe
執行
4.將磁碟內mdf及ldf複製到另外一台資料庫,然後掛載(Attach)
USE [master]
GO
CREATE DATABASE [FlushDiskDb] ON
( FILENAME = N'F:\Data\FlushDiskDb.mdf' ),
( FILENAME = N'F:\Data\FlushDiskDb_log.ldf' )
FOR ATTACH
GO
5.接著查詢Table T1,確認Database Engine是否成功的使用Transaction log 檔案回追資料?
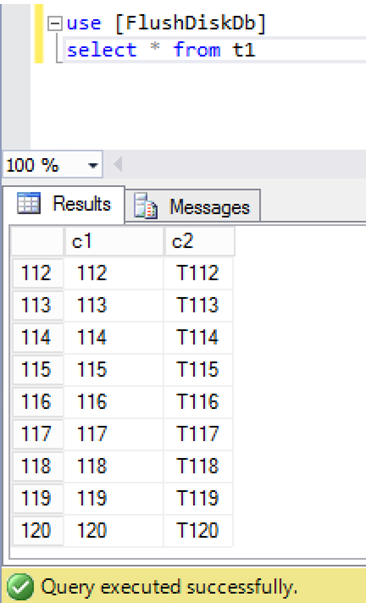
噹噹!120筆全員到齊!
不管使用自動與間接檢查點機制,紀錄檔(ldf)與資料檔(mdf、ndf)可能會存在時間差,但Database Engine還是能透過正確的ldf檔來確保ACID的持久性(Durability),關鍵就是ldf是否也正確同步到異地了!
自動檢查點發生的頻率
1.為了觀察CheckPoint發生的頻率,我們來建立擴充事件的監控。
--先查詢DB_ID
SELECT DB_ID(N'FlushDiskDb')
--建立擴充事件
CREATE EVENT SESSION [CheckPointEvent] ON SERVER
ADD EVENT sqlserver.checkpoint_begin(
ACTION(sqlserver.database_id,sqlserver.database_name,sqlserver.is_system)
WHERE ([sqlserver].[database_id]=(20))
)
--,ADD EVENT sqlserver.checkpoint_end(
--ACTION(sqlserver.database_id,sqlserver.database_name,sqlserver.is_system)
-- WHERE ([sqlserver].[database_id]=(20))
-- )
ADD TARGET package0.event_file
(
SET FILENAME = N'C:\temp\db\CheckPointEvent.xet'
)
WITH (MAX_DISPATCH_LATENCY = 1 SECONDS)
--啟用擴充事件
ALTER EVENT SESSION [CheckPointEvent] ON SERVER STATE=START
建立完畢!
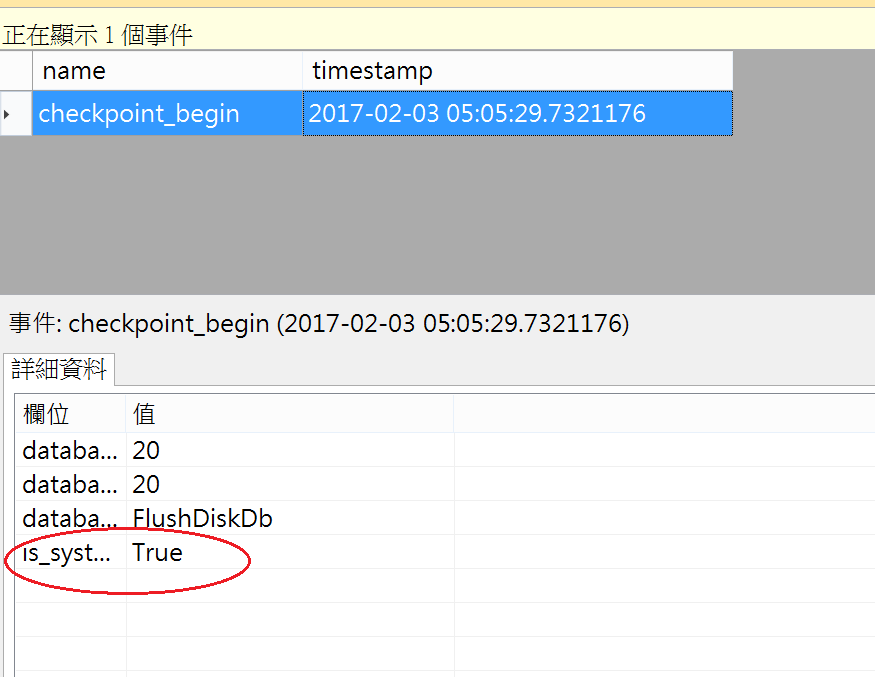
2.執行20萬筆資料寫入,觀測自動檢查點的執行次數!
USE [FlushDiskDb]
--建立資料表t01
drop table t01
create table t01
(
c1 int identity,
c2 varchar(30)
)
--執行20萬筆寫入
Declare @COUNT INT = 0;
WHILE (@COUNT < 200000)
BEGIN
SET @COUNT = @COUNT + 1
INSERT INTO t01
VALUES ('T' + CONVERT(VARCHAR, @COUNT))
END
只錄到1次CheckPoint
間接檢查點(Indirect CheckPoint)
為了降低資料庫復原的時間,SQL Server 2012在資料庫層級新增了一組TARGET_RECOVERY_TIME,她是一個復原時間的目標,可以讓我們自行決定是否採用間接簡單點機制,在SQL 2012-2014間預設還是使用自動檢查點機制,但到了SQL Server 2016之後,如果在UI新增資料庫,新的預設值就是採用間接CheckPoint機制,Target Recovery Time預設為60秒,SQL Server會在內部計算多少Dirty Page作為觸發check point的門檻來符合目標復原時間的目標。
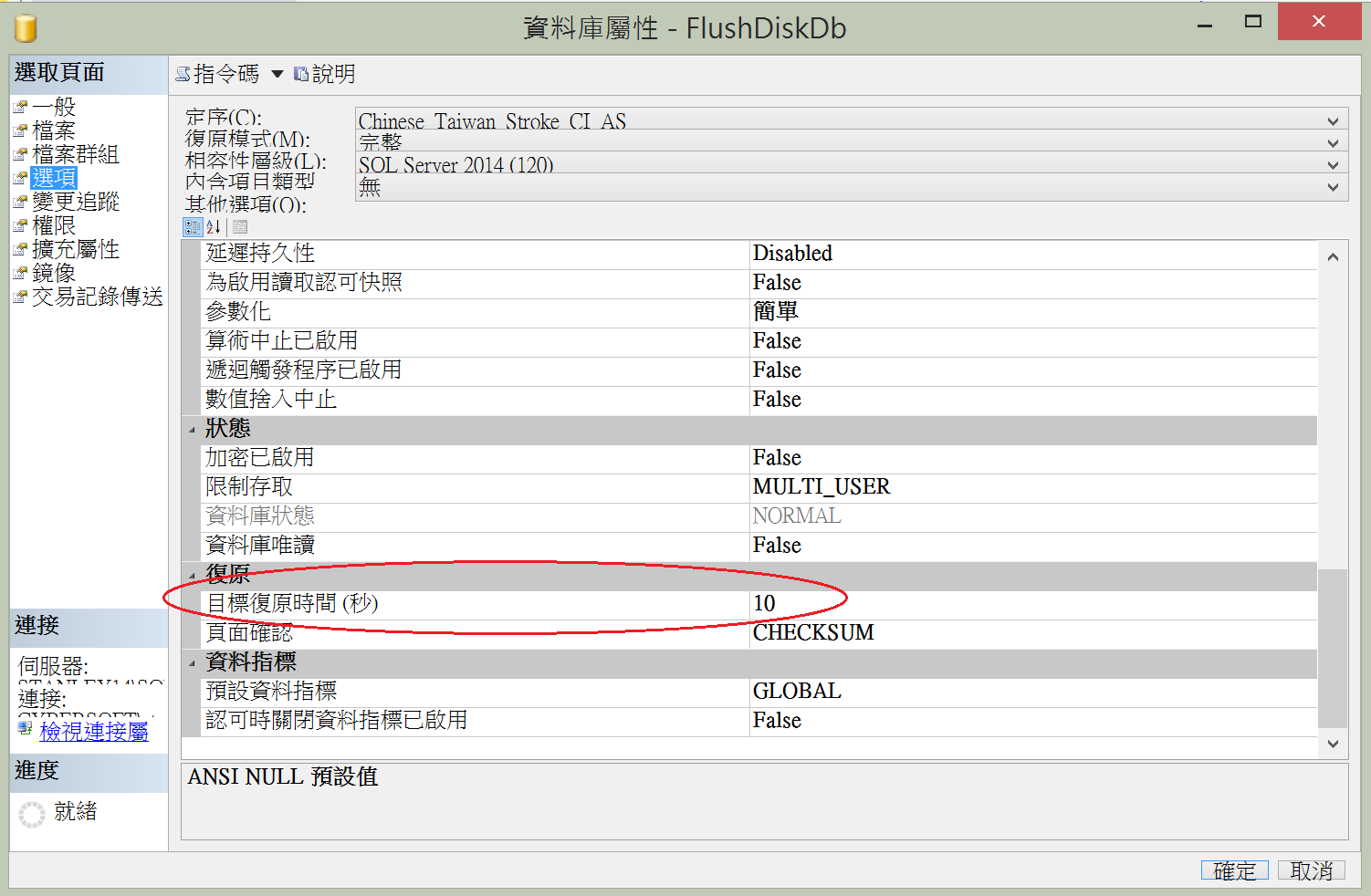
1.把資料庫目標復原時間設定成10秒
ALTER DATABASE [FlushDiskDb] SET TARGET_RECOVERY_TIME = 10 SECONDS;
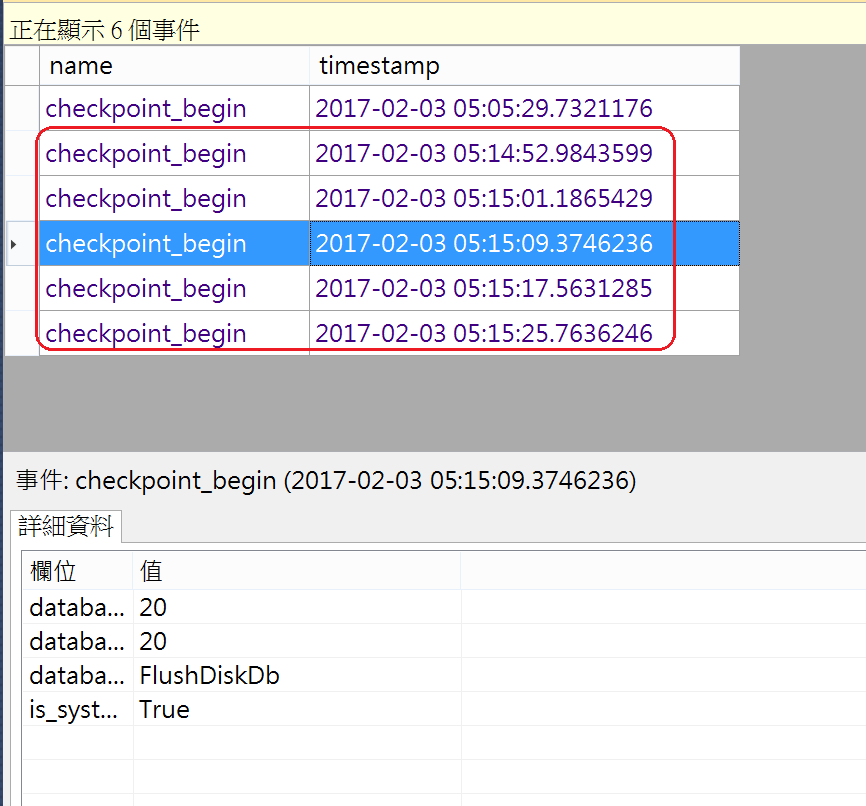
2.建立Table:T02,然後打20萬筆交易,計算發生CheckPoint的頻率
USE [FlushDiskDb]
drop table t1
create table t1
(
c1 int identity,
c2 varchar(30)
)
Declare @COUNT INT = 0;
WHILE (@COUNT < 2000)
BEGIN
BEGIN tran tran_1
SET @COUNT = @COUNT + 1
INSERT INTO t1
VALUES ('T' + CONVERT(VARCHAR, @COUNT))
COMMIT
WAITFOR DELAY '00:00:00.01'
END
相較自動檢查點機制,間接檢查點總共增加了5次CheckPoint活動
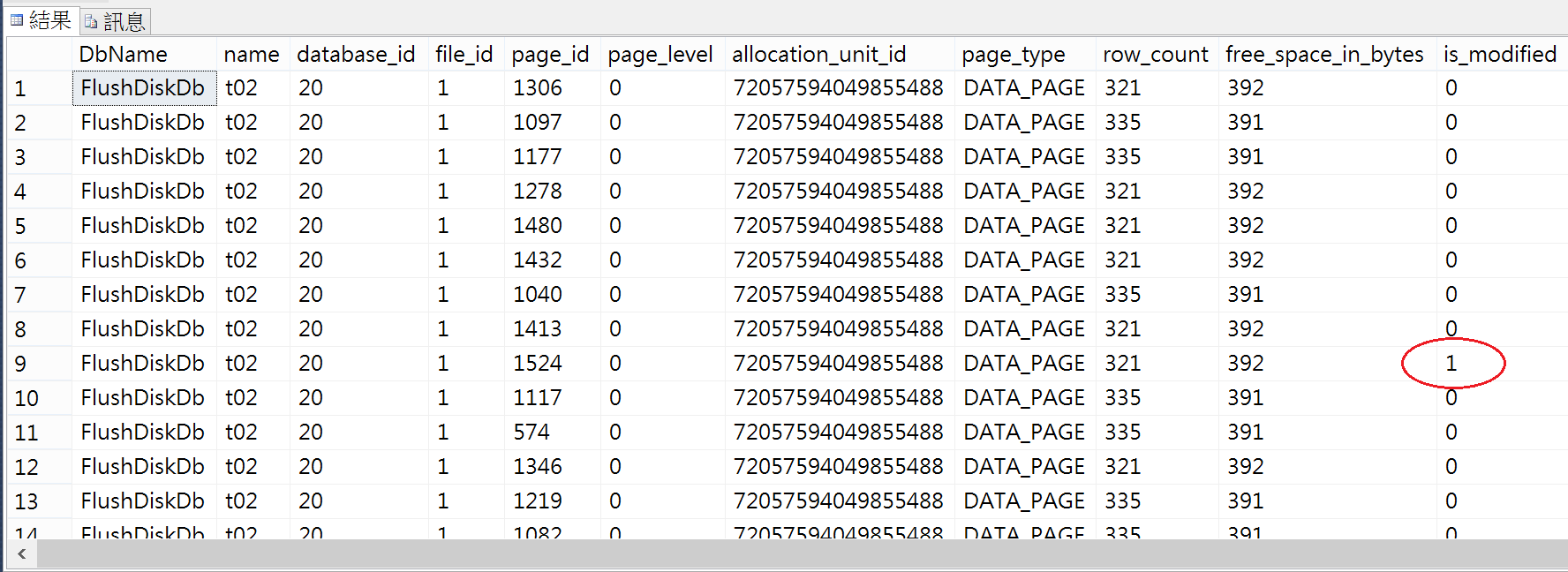
3.查詢Buffer Pool內的Data Page
USE FlushDiskDb
SELECT
DB_NAME(buf.database_id) AS DbName
,o.name
,buf.*
FROM sys.dm_os_buffer_descriptors buf
LEFT JOIN sys.allocation_units AS au WITH (NOLOCK)
ON buf.allocation_unit_id = au.allocation_unit_id
LEFT JOIN sys.partitions AS pt WITH (NOLOCK)
ON au.container_id = pt.hobt_id
LEFT JOIN sys.objects AS o WITH (NOLOCK)
ON pt.object_id = o.object_id
LEFT JOIN sys.indexes AS idx WITH (NOLOCK)
ON o.object_id = idx.object_id
AND pt.index_id = idx.index_id
WHERE DB_NAME(buf.database_id) = db_name()
and o.type_desc = 'USER_TABLE'
大部分的Dirty Page已經Flush到磁碟上,一旦資料庫需要復原,就只需要回追幾個Data Page的資料了。
自動檢查點機制(Auto CheckPoint) vs 間接檢查點機制(Indirect CheckPoint)
可以參考以下Mike Ruthruff這篇文章的比較,在SQL 2016的版本中,若使用間接檢查點機制,可以讓磁碟的寫入活動更為平均。
另外也可以注意到把2012或2014資料庫搬到SQL 2016使用自動檢查點機制時的效能影響。
https://blogs.msdn.microsoft.com/sqlcat/2016/08/03/changes-in-sql-server-2016-checkpoint-behavior/
小結:
1.是否使用間接檢查點機制: 降低復原時間的考量。
2.伺服器配置的記憶體越大,代表掃描記憶體找出Dirty Page的時間越久,這時候就需要更勤勞的CheckPoint活動。
3.也可以用Trace flag 3502/3504監控CheckPoint活動,但建議使用擴充事件(Extended Event)監控。
參考:
Database Checkpoints (SQL Server)
Configure the recovery interval Server Configuration Option
Changes in SQL Server 2016 Checkpoint Behavior
SQL 2016 – It Just Runs Faster: Indirect Checkpoint Default
Change the Target Recovery Time of a Database (SQL Server)