很少扎實的實作SQL Server Database Engine內部的行為,最近發現某個客戶的效能瓶頸可能在Transaction log的I/O,同時另外一家客戶正在導入儲存廠商異地備援(DR site)的解決方案(不打算用AlwaysOn傳送到異地),由於保護的是磁碟資源,我們需要確保磁碟上的mdf、ndf與ldf的一致性。
來筆記Buffer Flush To Disk讀書心得以及SQL2012/2014/SQL2016相關的新古與全新功能。
維持ACID的完整性(Atomicity)及持久性(Durability)
為了維持關聯式資料庫A.C.I.D的重要使命,SQL Server採用交易紀錄(Transaction log)來實現完整性Atomicity及持久性(Durability),這邊先簡單解釋完整性Atomicity及持久性(Durability):
- 完整性Atomicity: 交易必須全部完成執行,要不就是全部不執行。
- 持久性(Durability):交易完成之後,其作用便永遠存在於系統之中。
為了能擁有飛快的I/O效能,更新資料庫資料時,SQL Server會先將資料檔及紀錄檔更新在Buffer Pool(也稱Buffer cache),也就是記憶體緩存區內,而為了確保完整性及持久性,一個交易的Commit完成,則是將寫入Buffer Pool中的Log Flush到Disk上作為確認,也就是write-ahead log (WAL),先確保log儲存磁碟正確(這與AlwaysOn的同步認可很類似)。
因為資料分頁(Data Page)還在Buffer Pool上,此時若SQL Server所在的伺服器發生記憶體異常,只要Transaction log的磁碟檔案(.ldf)正確,DataBase Engine還是可以使用Transaction Log完成ReDo及UnDo將Disk上的mdf/ndf檔案追回或復原正確。
*如果直接同步mdf、ndf與ldf到異地機房(DR Site),可能會碰上log(ldf)是新的,但data file(mdf ndf)還是舊的情境。
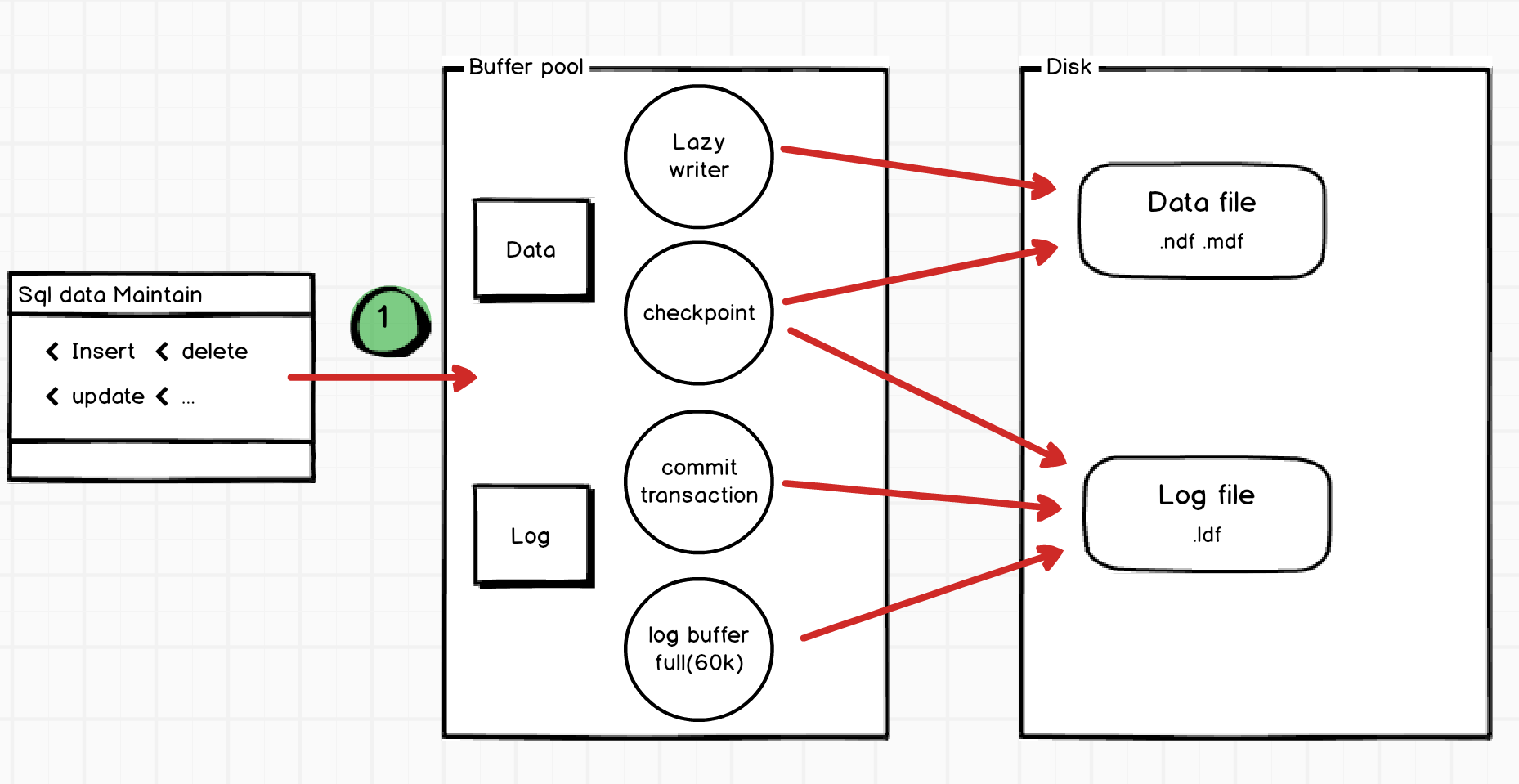
從Buffer Pool寫入Log到磁碟的時間點
前面文章理解到Transaction Log寫入磁碟的其中一個時間點是交易Commit的Ending pose,整理幾個寫入磁碟的時間點:
- 交易commit
- log Buffer到達60K的容量
- checkpoint 檢查點
這邊我們先簡單測試交易commit前後,DataBase Engine在磁碟上的活動。
1.建立測試資料庫、測試資料表及測試資料
CREATE DATABASE [FlushDiskDb]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'FlushDiskDb', FILENAME = N'C:\temp\db\FlushDiskDb.mdf' , SIZE = 5120KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'FlushDiskDb_log', FILENAME = N'C:\temp\db\FlushDiskDb_log.ldf' , SIZE = 2048KB , FILEGROWTH = 10%)
GO
USE [master]
GO
ALTER DATABASE [FlushDiskDb] SET RECOVERY FULL WITH NO_WAIT
GO
create table t1
(
c1 int identity,
c2 varchar(30)
)
insert t1 VALUES('Stanley')
insert t1 VALUES('Taiwan')
2.打開process monitor
3.設定Filter條件
Ctrl + L 熱鍵跳出Filer選項
設定Filter條件: Path > Contaons > database file路徑
4.建立一個交易,然後先不要Commit
use FlushDiskDb
BEGIN tran tran_one
update t1
set c2 = 'France'
where c1 = 2
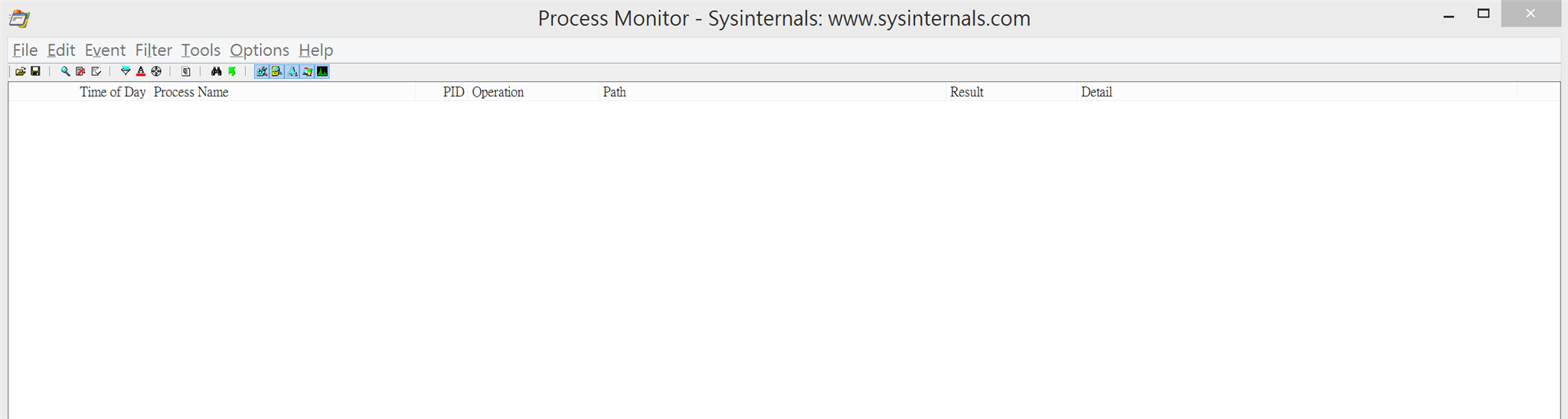
5.果然在process monitor中: 空空如也!
6.但如果此時在交易的最後面下了commit
process monitor 出現了寫入.ldf的磁碟活動! 而且只有ldf沒有mdf磁碟活動喔。
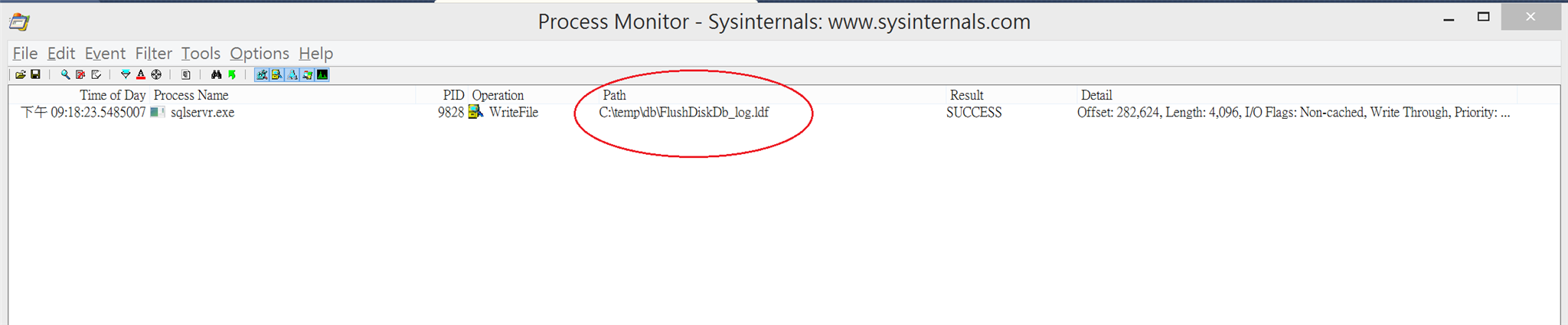
write-ahead log (WAL),先保證log寫入磁碟來確保ACID的AD!
從Buffer Pool寫入資料分頁到磁碟的時間點
前面的簡單練習可以理解到Log寫入磁碟的時間點,也許聰明的工程師一定很快想進一步知道,資料分頁寫入磁碟的時間點? 從Technet的文章很快找到答案:
- checkpoint:檢查點發生
- Lazy writer:懶惰寫入器工作了(因為很懶惰,觸發的機會相較checkpoint少很多)
- Eager writing: 熱切的寫入器被選擇,然後大量載入交易發生了(nonlogged操作的一種,這邊暫時不討論)
簡單把Data Page和log buffer一起劃圖來表示磁碟寫入流程:
檢查點(CheckPoint)觸發時機
這邊我們先study最常發生的CheckPoint,中文是檢查點,CheckPoint會將目前記憶體中已修改的頁面 (中途分頁或稱Dirty Page)和交易記錄資訊從記憶體緩存(Buffer Cache)中寫入磁碟上。
Database Engine 支援幾種類型的檢查點:
- 自動:SQL DataBase Engine決定,可在執行個體層級設定(recovery interval)。
- 間接:SQL Server 2012中的新功能,在資料庫層級設定固定週期的檢查點時間(TARGET_RECOVERY_TIME)。
- 手動: 人為的方式執行checkpoint指令
- 系統內部: 執行資料庫備份、快照、停止 SQL Server (MSSQLSERVER) 服務、SQL Server 容錯移轉叢集執行個體 (FCI) 離線、使用 ALTER DATABASE 加入或移除資料庫檔案..
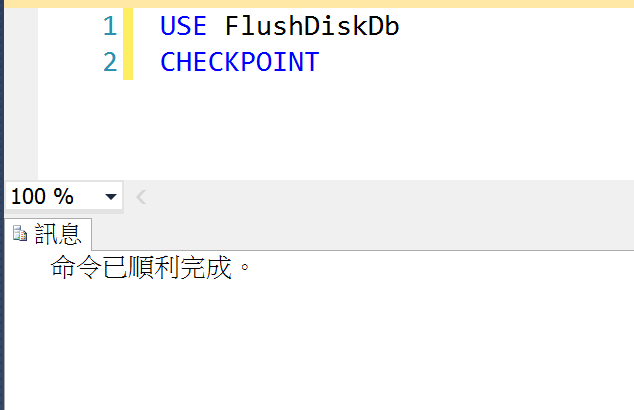
我們來試試剛剛的案例,新增查詢視窗,手動輸入checkpoint指令!
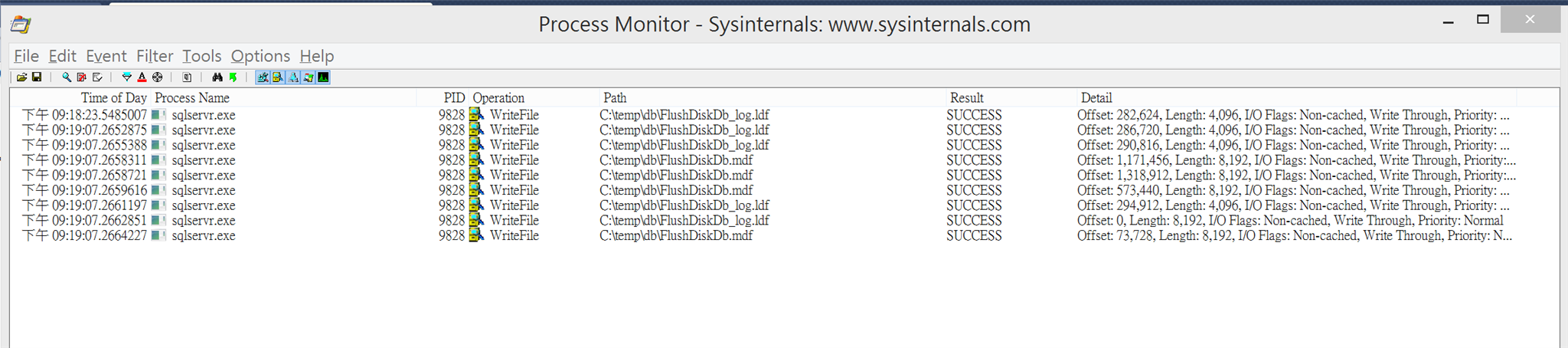
Process monitor多了寫入.mdf的磁碟活動
Checkpoint vs Lazy writer
Checkpoint和Lazy writer很類似,但Checkpoint的設計出發點是為了縮短資料庫的復原時間,但Lazy writer則是為了解決記憶體壓力,兩種執行後都會將Buffer Cache的資料分頁寫入磁碟,但只有Lazy Writer會釋放出資源。
如果也希望checkpoint釋放資源,舉例來說,我們需要手動再執行DBCC DROPCLEANBUFFERS指令:
CHECKPOINT;
GO
DBCC DROPCLEANBUFFERS;
GO
查詢目前Buffer Pool中的資料表
我們可以透過sys.dm_os_buffer_descriptors 這個dm查詢到!
USE FlushDiskDb
SELECT
DB_NAME(buf.database_id) AS DbName
,o.name
,buf.*
FROM sys.dm_os_buffer_descriptors buf
LEFT JOIN sys.allocation_units AS au WITH (NOLOCK)
ON buf.allocation_unit_id = au.allocation_unit_id
LEFT JOIN sys.partitions AS pt WITH (NOLOCK)
ON au.container_id = pt.hobt_id
LEFT JOIN sys.objects AS o WITH (NOLOCK)
ON pt.object_id = o.object_id
LEFT JOIN sys.indexes AS idx WITH (NOLOCK)
ON o.object_id = idx.object_id
AND pt.index_id = idx.index_id
WHERE DB_NAME(buf.database_id) = db_name()
and o.type_desc = 'USER_TABLE'
ORDER by name
執行結果:
1.Checkpoint執行前: Dirty Page

2.Checkpoint執行後

3.DBCC DROPCLEANBUFFERS執行後:

今天先大致理解Buffer Pool寫入磁碟的架構及時間點,周末繼續筆記未完成的SQL2012/2014/2016新古和全新功能。
參考:
Writing Pages
https://technet.microsoft.com/en-us/library/aa337560(v=sql.105).aspx
資料庫檢查點 (SQL Server)
https://msdn.microsoft.com/zh-tw/library/ms189573(v=sql.120).aspx