搜尋的功能在軟體發展到一個階段,甚至是在軟體建置初期就會被要求加入的一個功能,實作搜尋功能的方式有很多,我接觸過的除了傳統關聯式資料庫的 LIKE,還有 Microsoft Index Service、HP IDOL 到今天我要介紹的 Elasticsearch。
什麼是 Elasticsearch?
Elasticsearch(簡稱ES),是一個 Open Source 的搜尋專案,base on Apache Lucene,專案由 Shay Banon 於 2010 年 2 月啟動,其協定是 Apache 2.0。
Elasticsearch 由於其天生的分散式和即時特性,很多人把它作為資料庫使用,也有很多人把它拿來儲存 Log,Elasticsearch 的發佈在 Lucene 和 Solr 社群引起很大的騷動,Solr 4.0+ 版本的 SolrCloud 也吸收了很多 Elasticsearch 的特性。
基本名詞解釋
- Node:Elasticsearch 可以用單一站台或叢集的方式運作,以一個整體的服務對外提供搜尋的功能,一個安裝有 Elasticsearch 服務的站台就稱為是一個 Node。
- Cluster:想當然爾,一群安裝有 Elasticsearch 服務的站台們,就稱為是 Cluster。
- Field:這是 Elasticsearch 儲存資料的最小單位,類似於關聯式資料庫的 Column。
- Document:若干個 Field 集合成一個 Document,類似於關聯式資料庫的 Row,每一個 Document 都有一個唯一的 ID 作為區分。
- Type:一個 Document 必須隸屬於一個 Type,類似於關聯式資料庫的 Table。
- Index:一個 Type 必須隸屬於一個 Index,類似於關聯式資料庫的 Database。
- Shard:通常叫做分片,這是 Elasticsearch 提供分散式搜尋的基礎,其含義是將一個完整的 Index 分成若干部分,儲存在相同或不同的 Node 上,這些組成 Index 的部分就叫做 Shard。
- Replica:意思跟 Replication 差不多,就是 Shard 的備份,所以一個 Index 的 Shard 數量就等於 Shard × (1 + Replica)。
分散式的特性 - 備份不重覆
我畫了一圖,假設我一個 Elasticsearch 的 Cluster 有 3 個 Node,我將 Index 切成 3 個 Shard、1 份 Replica,大致上就會長成下面這個樣子。
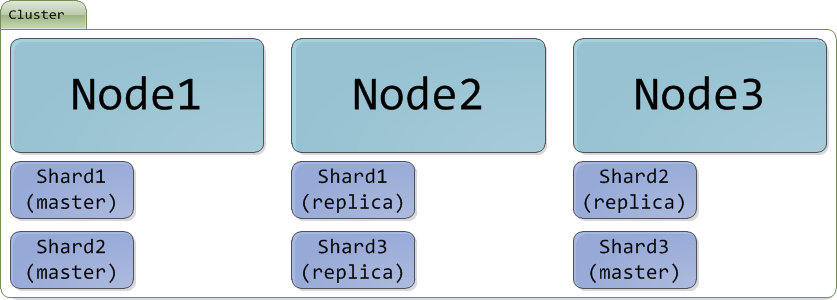
從上面這張圖可以看到一個特性,以我假設的情況為例,在任一個 Node 上無論 Shard 是 master 還是 replica,絕對不會有重覆編號的 Shard 出現。
如果我的 Shard 太多,Node 太少怎麼辦?Elasticsearch 就不會分配多餘的 Shard 到 Node 裡面,不過至少 master 的 Shard 保證都會有一份。
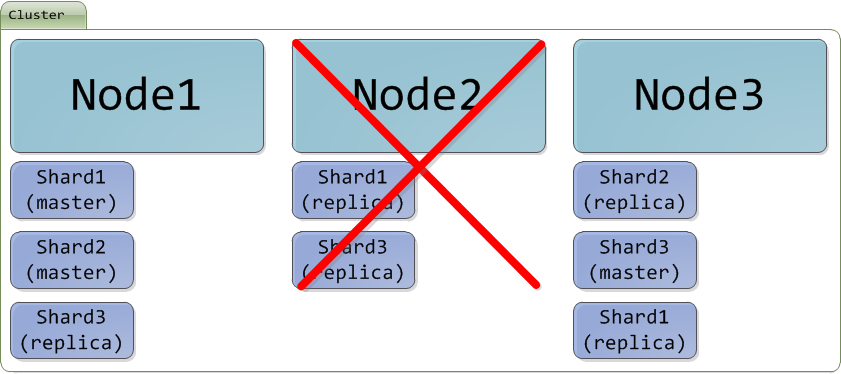
分散式的特性 - 自動還原資料
假設有一天 Cluster 內的 Node2 掛點了,Cluster 就會啟動重新分配 Shard 的機制,而遺失的 Shard 就會從其他 Node 補足,目的在確保資料的完整性,重新分配後大致上就會長這個樣子,是不是很方便?