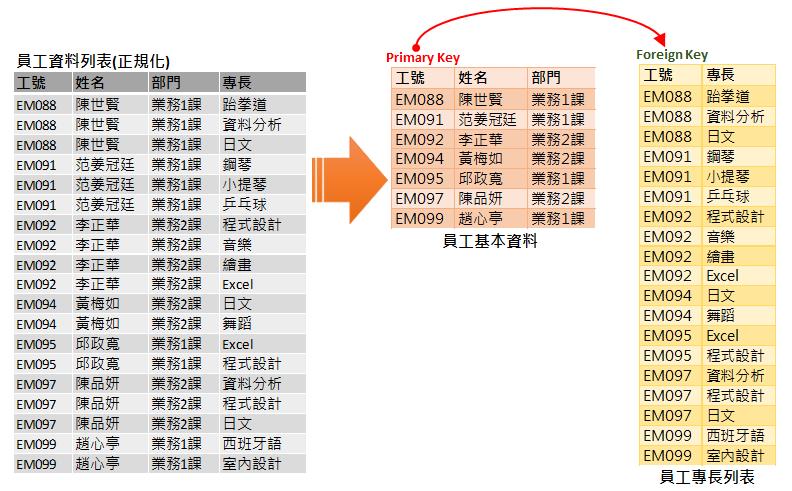
上一篇文章我們使用Power Query編輯器實作了將非結構化資料表轉換成結構化資料的DAW DATA,也從範例中介紹了「基元值」(Atomic Value)這個專有名詞。然而,這份DAW DATA仍不是完美的關聯式資料表,理由是重複性資料站多,主要索引關鍵欄位也需要建構與釐清。
若要解決此例中「工號」、「姓名」與「部門」等三個資料欄位的內容太多重複的困擾,那就必須開啟關聯式資料庫之資料表第二階段正規化的分析與轉換。也就是將此資料表適度切割成不同的資料表,以達成完全相依的資料表設計。對此例而言,我們可以將此資料表拆分成[員工基本資料]以及[員工專長],然後再為這兩個資料表建立一對多的關聯,也正是關聯式資料庫的主要訴求。
請下載這篇文章的實作範例,開始以下的實作囉!
建立關聯式資料表
在Power Query編輯器左側的查詢導覽窗格裡,以滑鼠右鍵點選剛剛完成的查詢,再從展開的快顯功能中點選[重複]功能選項,以此查詢複製出另一個一模一樣的新查詢,而此新查詢與[員工專長清單]有著相同的資料來源與所有的查詢步驟。
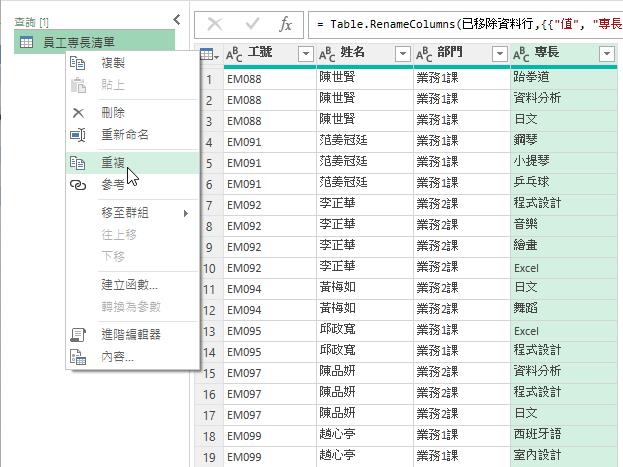
接著,點選剛剛建立的新查詢,然後點選[姓名]與[部門]這兩個資料行後,再以滑鼠右鍵點選其中一個資料行的資料行名稱,從展開的快顯功能表中點選[移除資料行]功能選項。
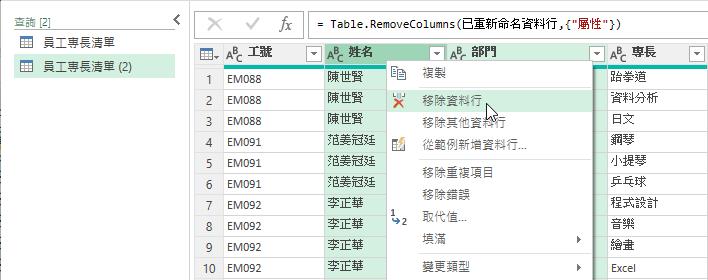
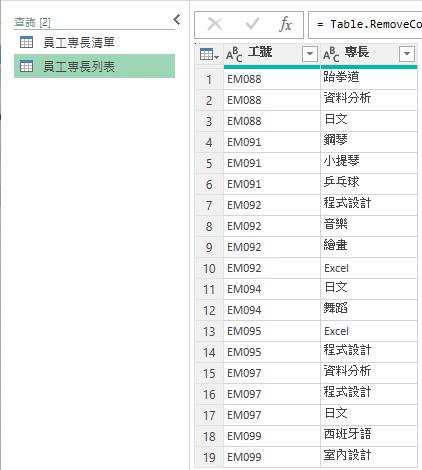
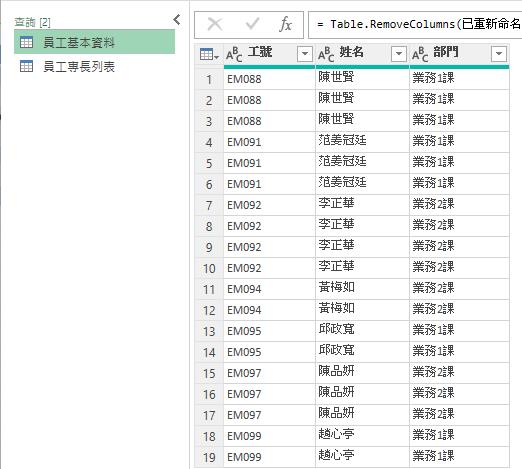
留下來的[工號]與[專長]便是每位員工的專長項目列表了,完成後即可將此查詢結果更名為[員工專長列表]查詢。
接著點選先前的[員工專長清單]查詢,以滑鼠右鍵點選[專長]資料行的資料行名稱後,從展開的快顯功能表中點選[移除]功能選項。
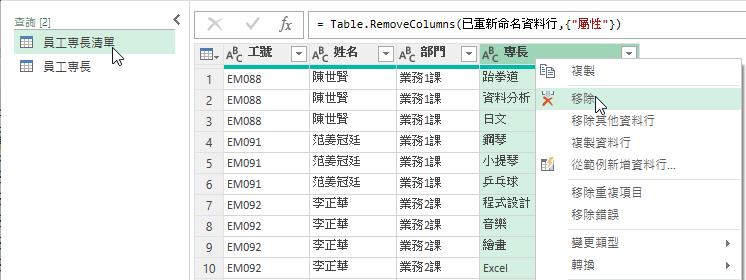
然後,將此查詢結果更名為更貼切的[員工基本資料]查詢。
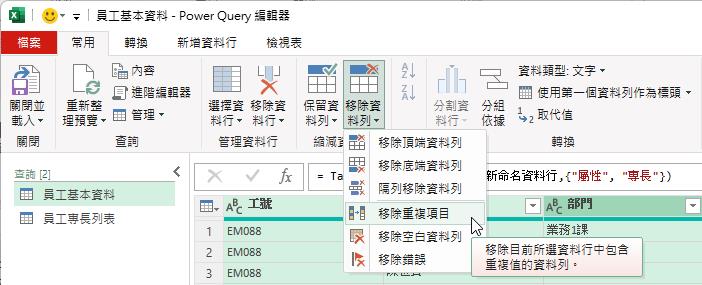
在同時選取查詢結果裡的所有資料行後,點按[常用]索引標籤裡的[移除資料列]命令按鈕,並從展開的功能選單中點選[移除重複項目]功能選項。這也正符合了關聯式資料庫的關聯特性,那就是要建立關聯的資料表中,不含重複的「值組」(Tuple),也就是說,不含重複的資料記錄。
最終完成的查詢結果中,沒有重複內容的[工號]資料行,就是這張資料表的主索引鍵(Primary Key),而[姓名]與[部門]在此資料表裡都相依於[工號]資料行。因此,便可以為前後這兩個查詢結果資料表進行關聯的設定了。而這重責大任就交由Excel的Power Pivot(資料模管理員)來幫忙囉!此時,可以點按[常用]索引標籤,點按[關閉並載入]命令按鈕的下半部按鈕,並從展開的下拉式功能選單中點選[關閉並載入至…]功能選項。
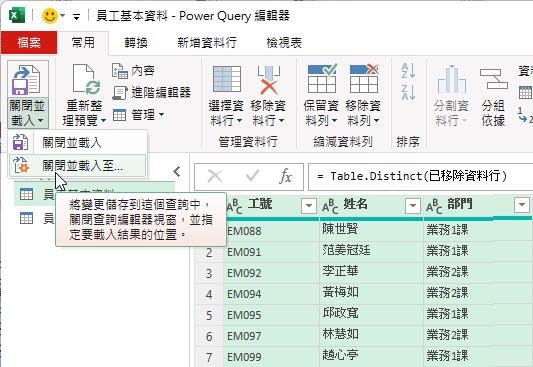
開啟[匯入資料]對話方塊後,點按[只建立連線]功能選項並勾選[新增此資料至資料模型]核取方塊,完成此對話方塊的操作。
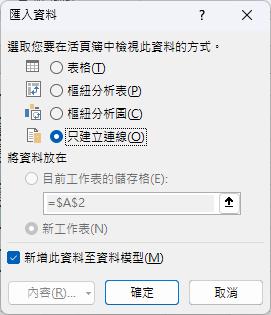
回到Excel的操作環境,點按[Power Pivot]索引標籤底下[資料模型]群組裡的[管理]命令按鈕,即可。
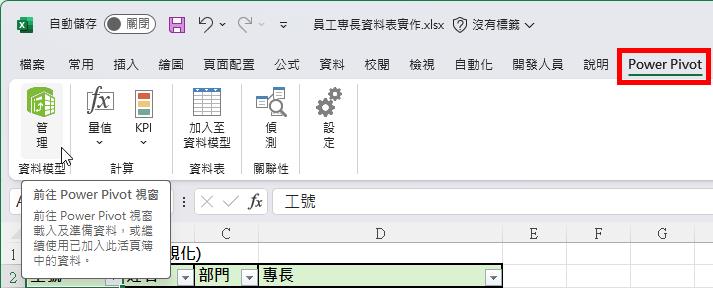
進入[適用於Excel的Power Pivot]應用程式,也就是資料模型管理員的操作環境,此處的兩張資料表正是來自Power Query查詢結果的複本。
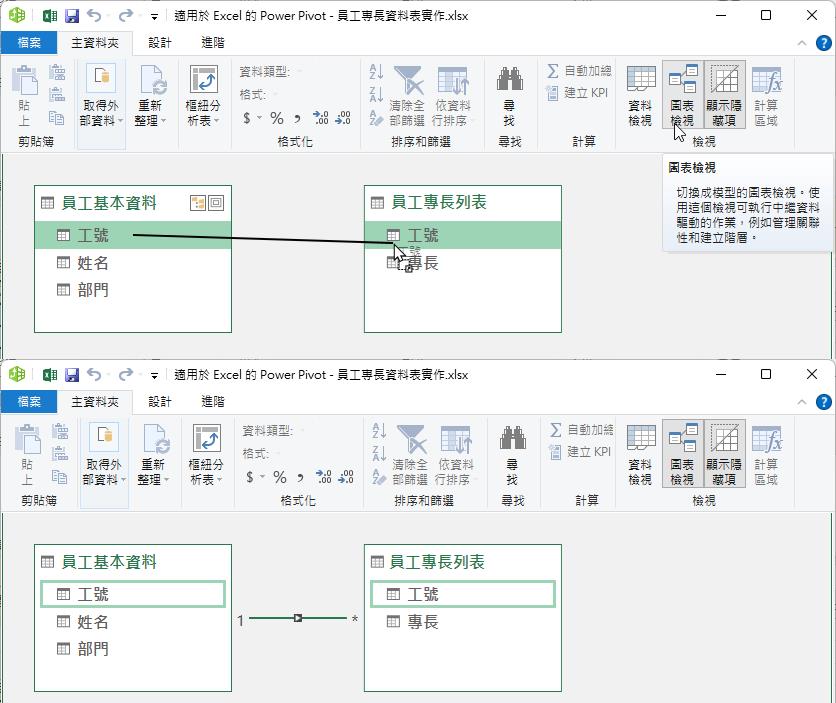
點按[主資料夾]索引標籤裡的[圖表檢視]命令按鈕,即可在此介面中利用滑鼠拖曳操作,設定兩資料表之間的關聯。例如:拖曳[員工基本資料]資料表裡的[工號],拖曳疊放在[員工專長列表]資料表裡的[工號]。為這兩張資料表建立起一對多的關聯。
本文旨在運用Power Query面臨非結構化資料,如何進行拆分與整理,也從中學習資料庫的概念與專由名詞,準備好建立關聯性資料庫的基本素材,也就是結構化資料表後,再藉由Power Pivot資料模型的運用,建構出資料表之間的關聯,至於如何加以運用以符合您的需求,就請發揮您的想像力來解決您的需求囉!
小知識
資料欄位裡的內容到底是不是「基元值」(Atomic Value),是可以由使用者自行認定的。例如:「血型」欄位的內容,應該很適合也理應是「基元值」(Atomic Value)的特性,因為血型的內容直到目前為止,應該不外乎是「A」、「B」、「AB」、「O」,這些內容並不會再分類下去;而「地址」欄位的內容是不是屬於「基元值」(Atomic Value),就比較彈性與客製化了。若是一個包含鄉鎮市區街及道號房號的完整詳細地址,若想要再分割成各個值,例如:將「詳細地址」再分割成「縣市」、「鄉鎮市區」、「村里」與「街道巷弄」等四個資料欄位,且這四個欄位的內容都不會再分割了,那麼這四個資料欄位都是屬於符合「基元值」(Atomic Value)的特性,也就是符合結構化資料表的要求。
【下載此實作範例檔案】