我有個後端API,如果權限不足時。前端攔截器會取得對應的StatusCode並回應相對應的錯誤訊息,但找網路上的教學來做,卻發現我的StatusCode一直都是0…
2024-04-12
我有個後端API,如果權限不足時。前端攔截器會取得對應的StatusCode並回應相對應的錯誤訊息,但找網路上的教學來做,卻發現我的StatusCode一直都是0…
做網頁系統開發一定會遇到帳號登入的問題。
大家都知道密碼要用[HttpPost]放在Request Body裡面來進行傳遞。這句話只對了一半,因為只要在瀏覽器按下F12進入開發者模式,密碼還是會被看光光的,好恐怖的阿。
所以對密碼進行加密是最基本的資安防護。
這幾天剛 好有機會把WebAPI ModelBinding的方式整理一下,MVC也是差不多的用法,但還是會有一些差異。
今天會用到[FromRoute], [FromQuery], [FromBody]這三種ModelBinding方式
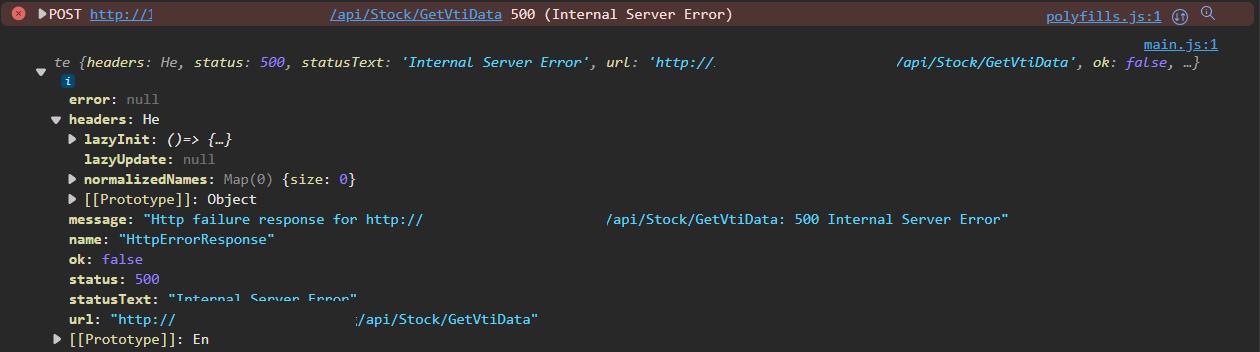
寫Web API時最討厭遇到500 (Internal Server Error)這種後端程式錯誤了,只返回一個Error Responese,c#的catch也抓不到錯誤訊息。由於不是本機環境,也沒有辦法下中斷點Debug,所以也不知道該如何除錯,這時候就知道紀錄後端Log的重要性了。
之前使用的原本是ElmahCore,但爬文後,發現Serilog的使用率比較高,相關資料也比較多。
ActionFilter的流程以及ActionFilter流程結束時間點的研究。
使用ActionFilterAttribute抽象類別並覆寫OnActionExecuting。實作IP過濾
預設情況下 NgModules 都是Eager Loading(急切載入)的,這意味一開始進入首頁,所有的 NgModules 無論是否需要都會被載入,使用Lazy Loading(延遲載入)功能,會等到Module內的元件有需要使用時才載入,延遲加載有助於讓初始化的檔案保持為較小的大小,從而減少加載的時間。
.Net 7 Open API Swagger設定
Linux Ubuntu實際架站(.Net WebAPI + Angular)範例
寫.Net程式一定會遇到非同步(await/async),async要放在哪裡比較沒有異議,但await放的地方才是重點。
目錄遍歷(Path Traversal)攻擊是透過相對路徑的方式來跨目錄的方式,藉機取得Server上原本是不公開的檔案。用比喻的方式來說的話,就大概是類似:
你授權請助理小姐去書桌第一格抽屜(目錄)拿開會要用的報告(公開的檔案),但助理小姐知道第二格抽屜(目錄)有500萬現金,雖然你沒授權他可以開,在你也沒有上鎖的情況下,助理小姐就自己打開第二格抽屜(目錄)拿走了500萬(非公開的檔案)。
上面這個範例,大概就是目錄遍歷(Path Traversal)攻擊的方式。
當我們透過HttpClient要調用API時,Model Binding是一個重要的東西。要給API的參數可以來自URL網址參數,可以以來自網址路由,可以來自表單。
如果是POST的話,資料則是可以放在Body裡面。
這篇文章整理了一些比較常見的傳輸參數的作法。
這幾天再用Insomnia測試API時,發現到:
使用IIS Express啟動網頁時,API可以透過Insomnia成功呼叫。
但使用Kestrel(https)啟動網頁時,呼叫API會一直回應401 Unauthorized的錯誤,但直接用瀏覽器卻又可以成功呼叫API。
有了前端畫面跟後端API。
最終的目的當然是要透過前端UI來呼叫後端的API,然後拿取得的API Result來做其他的應用。
而不是只用Postman或是瀏覽器來執行執行API網址這樣而已。
這時一定會遇到CORS的問題
前篇文章介紹的是單一Ubuntu Server掛載單一ASP.NET Core 程式。執行.Net程式後,Nginx會反向代理到預設的http://localhost:5000。
如果我們有不同的後端站台,在相同的Domain(IP)的情況下,Nginx要如何知道要反向代理到哪個網址呢?
Ubuntu部屬.Net Core程式
SFTP對於網頁開發來說是個重要的工具,可以透過SFTP把要發佈的程式上傳到Web Server,部屬靜態網頁至Nginx。並透過ChrootDirectory來限制能瀏覽的目錄,限制SFTP看到系統上的其他檔案。
Angular前端程式開發好之後,當然是要找地方部屬。個人之前是放在IIS上面,後來查資料才知道GitHub也可以直接部屬靜態網頁,這樣就可以放在Internet上面讓大家瀏覽了。
Angular生命週期是個重要的東西,了解其執行順序,對於日後開發前端程式時。也能更準確地把程式寫在對應的生命週期實作function裡面。
SignalR是一個自己蠻有興趣的東西,提供Server與Client端之間的即時通訊,而且使用也不算複雜。
SignalR所提供的功能有:
這次利用SignalR來做個訊息推播(Server to Client) & 廣播(Client to Client)的簡單範例。
Client to Client廣播測試請參考另外一篇文章 => SignalR(二):Server to all Client推播 & Client to all Client廣播
=================
SignalR是一個自己蠻有興趣的東西,提供Server與Client端之間的即時通訊,而且使用也不算複雜。
SignalR所提供的功能有:
這次利用SignalR來做個訊息推播的簡單範例。
做幾個簡單的範例來記錄ng-template. ng-container之間的差異
Scoped:每次Post/Get Request在Application結束前,都會使用相同的instance
Transient:每次注入都會建立新的instance
Singleton:應用程式從開始到結束,使用的都是同一個instance。(ex:執行應用程式後,會先進入Program,接著執行Post/Get Request,接著再執行一次Post/Get Request。這種情況使用的都是同一個Service實體。第二次Post/Get Request不會再進入Program,不算Application結束)。
Angular的元件,有些時候會把一些共用邏輯寫到Service裡面,但是會發現明明就是不同的元件,但不同元件之間的變數可能會被不同元件互相連動影響,導致變數有可能變成共用的這種情形發生。
今天再寫單元測試的時候遇到了一個奇怪的問題,通常單元測試寫好後,會自己進行跑一次偵錯看看有沒有什麼問題。但今天執行偵錯後,沒有出現任何的錯誤訊息,綠勾勾跟紅叉叉都沒有,單元測試就這樣無聲無息地結束了,讓人百思不得其解,也不知道哪個環節出錯了。
最近再使用Except()時,遇到個問題。明明他的功能就是要幫我們找出a有b沒有的資料,但結果卻一直跑出a已經有了,b也有的重複資料,研究了一下發現問題還蠻有趣的,也可以順便回憶一下reference type跟value type的相關知識喔~
我們在寫程式時,通常會把設定寫在appsettings.json裡面,但是不同的開發環境會有不同的設定值(例如:檔案產出路徑…etc)。.Net預設會使用appsettings.json這個檔案的設定值,但如果我們有不同的組態設定檔時(例如:DEV. SIT. UAT. PRD)。我們就要分別先新增appsettings.DEV.json, appsettings.SIT.json,appsettings.UAT.json,appsettings.PRD.json,其中的DEV.SIT.UAT會對應到不同的環境變數(appsettings.{環境變數}.json),有了不同環境的設定檔後,下面會來教大家要如何在本機開發環境切換不同的設定檔來進行測試。
當前端網頁開發完成後,接著就是實際放到iis上了(不然就只能一直再本機上面執行),過程中可能會遇到一些問題(CORS. 路徑設定…etc),趁著這次剛好有機會時做整個過程,就順便把整個過程做個紀錄。
最近在寫單元測試時,Setup一個Function之後,明明使用Verifiable()檢查確認Function有時被執行
Moq API:Verifiable() & Verfiy()